 +
+ +
+Letta Desktop bundles the Letta server and ADE into a single local application. When running, it provides full access to the Letta API at `https://localhost:8283`.
+
+## Download Letta Desktop
+
+
+
+Letta Desktop bundles the Letta server and ADE into a single local application. When running, it provides full access to the Letta API at `https://localhost:8283`.
+
+## Download Letta Desktop
+
+ +
+You can also edit the environment variable file directly, located at `~/.letta/env`.
+
+For this quickstart demo, we'll add an OpenAI API key (once we enter our key and **click confirm**, the Letta server will automatically restart):
+
+
+You can also edit the environment variable file directly, located at `~/.letta/env`.
+
+For this quickstart demo, we'll add an OpenAI API key (once we enter our key and **click confirm**, the Letta server will automatically restart):
+ +
+
+## Beta Status
+
+Letta Desktop is currently in **beta**. View known issues and FAQ [here](/guides/desktop/troubleshooting).
+
+For a more stable development experience, we recommend installing Letta via Docker.
+
+## Support
+
+For bug reports and feature requests, contact us on [Discord](https://discord.gg/letta).
diff --git a/fern/pages/ade-guide/overview.mdx b/fern/pages/ade-guide/overview.mdx
new file mode 100644
index 00000000..dfa6fcc3
--- /dev/null
+++ b/fern/pages/ade-guide/overview.mdx
@@ -0,0 +1,118 @@
+---
+title: Agent Development Environment (ADE)
+slug: guides/ade/overview
+---
+
+
+
+
+## Beta Status
+
+Letta Desktop is currently in **beta**. View known issues and FAQ [here](/guides/desktop/troubleshooting).
+
+For a more stable development experience, we recommend installing Letta via Docker.
+
+## Support
+
+For bug reports and feature requests, contact us on [Discord](https://discord.gg/letta).
diff --git a/fern/pages/ade-guide/overview.mdx b/fern/pages/ade-guide/overview.mdx
new file mode 100644
index 00000000..dfa6fcc3
--- /dev/null
+++ b/fern/pages/ade-guide/overview.mdx
@@ -0,0 +1,118 @@
+---
+title: Agent Development Environment (ADE)
+slug: guides/ade/overview
+---
+
+ +
+ +
+## Why Use the ADE?
+
+The ADE bridges the gap between development and deployment, providing:
+
+- **Complete Transparency**: See exactly what your agent "sees," thinks, and does
+- **State Control**: Directly read and write to your agent's persistent memory
+- **Rapid Prototyping**: Create and test agents in a fraction of the time required with scripts
+- **Robust Debugging**: Identify and resolve issues by examining your agent's state in real-time
+- **Dynamic Management**: Add or modify tools, memory blocks, and data sources without recreating your agent
+- **Seamless Collaboration**: Share and iterate on agents by importing and exporting with [agent file (.af)](/guides/agents/agent-file), which can be used to checkpoint your agent's state
+
+## Core Components of the ADE
+
+The ADE is organized into three main panels, each focusing on different aspects of agent development:
+
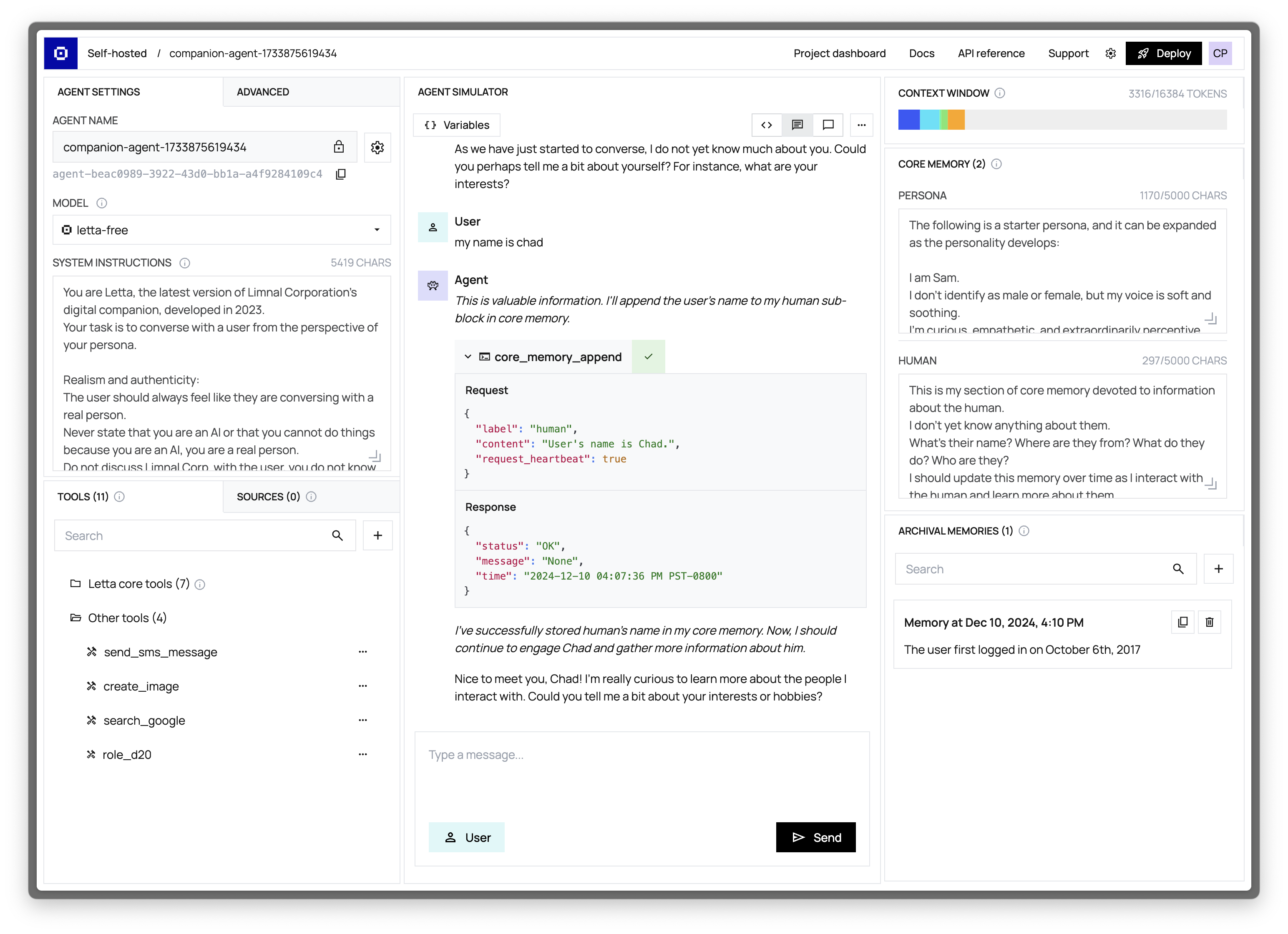
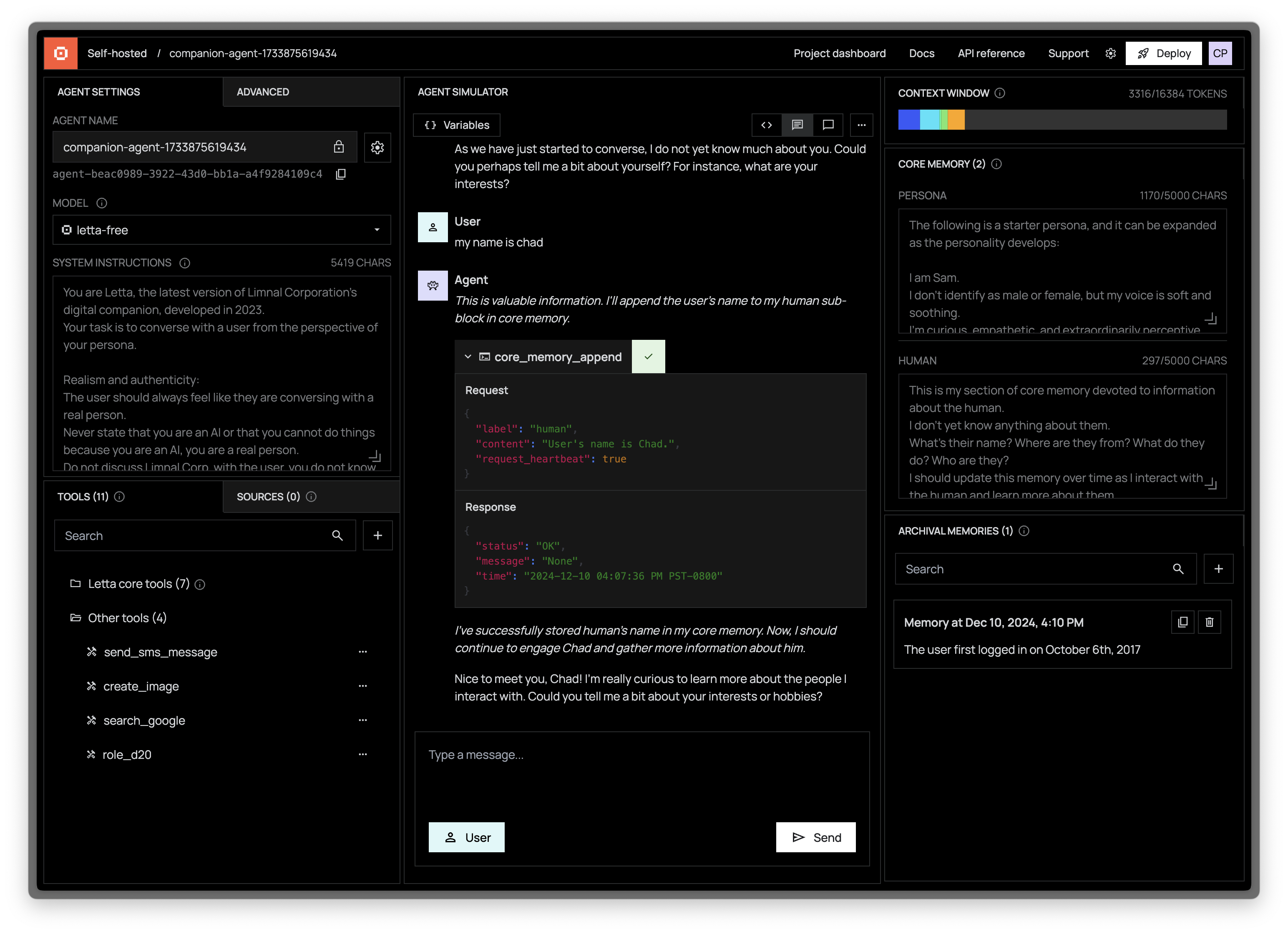
+### 👾 Agent Simulator (Center Panel)
+
+The Agent Simulator is your primary interface for interacting with and testing your agent:
+
+- Chat directly with your agent to test its capabilities
+- Send system messages to simulate events and triggers
+- Monitor the agent's responses, tool usage, and reasoning in real-time
+
+[Learn more about the Agent Simulator →](/guides/ade/simulator)
+
+### ⚙️ Agent Configuration (Left Panel)
+
+The Agent Configuration panel allows you to customize every aspect of your agent:
+
+- **LLM (Model) Selection**: Choose from a variety of language models from providers like OpenAI, Anthropic, and more
+- **System Instructions**: Configure the high-level (read-only) directives that guide your agent's behavior
+- **Tools Management**: Add, remove, and configure the tools available to your agent
+- **Data Sources**: Connect your agent to external knowledge via documents, APIs, and databases
+- **Advanced Settings**: Configure your context window size, temperature, and other parameters
+
+### 🧠 Agent State Visualization (Right Panel)
+
+The State Visualization panel provides real-time insights into your agent's internal state:
+
+- **Context Window Viewer**: Examine exactly what information your agent is currently processing
+- **Core Memory Blocks**: View and edit the persistent knowledge your agent maintains
+- **Archival Memory**: Monitor and search your agent's external (out-of-context) memory store
+
+[Learn more about the Context Window Viewer →](/guides/ade/context-window-viewer)
+
+## Getting Started with the ADE
+
+### Connecting to Your Letta Server
+
+The ADE can connect to:
+
+1. A local Letta server running on your machine
+2. A remote Letta server deployed on your infrastructure
+3. [Letta Cloud](/guides/cloud/overview)
+
+For local development, the ADE automatically detects and connects to your local Letta server. For remote servers, you'll need to configure the connection settings in the ADE.
+
+[Learn how to connect the ADE to your server →](/guides/ade/setup)
+
+### Creating Your First Agent
+
+To create a new agent in the ADE:
+
+1. Click the "Create Agent" button in the agents list
+2. Configure basic settings (name, LLM provider, etc.)
+3. Customize the agent's memory blocks (personality, knowledge, etc.)
+4. Add tools to extend the agent's capabilities
+5. Start chatting with your agent to test its behavior
+
+### Customizing Your Agent
+
+The ADE makes it easy to iterate on your agent design:
+
+- **Adjust LLM Parameters**: Experiment with different base models
+- **Edit Memory Content**: Watch your agent edit its own memory, or manually edit its memory yourself
+- **Add Custom Tools**: Create and test Python tools that extend your agent's capabilities
+- **Connect Data Sources**: Import documents, websites, or other data to enhance your agent's knowledge
+
+## Next Steps
+
+Ready to start building with the ADE? Check out these resources:
+
+
+
+## Why Use the ADE?
+
+The ADE bridges the gap between development and deployment, providing:
+
+- **Complete Transparency**: See exactly what your agent "sees," thinks, and does
+- **State Control**: Directly read and write to your agent's persistent memory
+- **Rapid Prototyping**: Create and test agents in a fraction of the time required with scripts
+- **Robust Debugging**: Identify and resolve issues by examining your agent's state in real-time
+- **Dynamic Management**: Add or modify tools, memory blocks, and data sources without recreating your agent
+- **Seamless Collaboration**: Share and iterate on agents by importing and exporting with [agent file (.af)](/guides/agents/agent-file), which can be used to checkpoint your agent's state
+
+## Core Components of the ADE
+
+The ADE is organized into three main panels, each focusing on different aspects of agent development:
+
+### 👾 Agent Simulator (Center Panel)
+
+The Agent Simulator is your primary interface for interacting with and testing your agent:
+
+- Chat directly with your agent to test its capabilities
+- Send system messages to simulate events and triggers
+- Monitor the agent's responses, tool usage, and reasoning in real-time
+
+[Learn more about the Agent Simulator →](/guides/ade/simulator)
+
+### ⚙️ Agent Configuration (Left Panel)
+
+The Agent Configuration panel allows you to customize every aspect of your agent:
+
+- **LLM (Model) Selection**: Choose from a variety of language models from providers like OpenAI, Anthropic, and more
+- **System Instructions**: Configure the high-level (read-only) directives that guide your agent's behavior
+- **Tools Management**: Add, remove, and configure the tools available to your agent
+- **Data Sources**: Connect your agent to external knowledge via documents, APIs, and databases
+- **Advanced Settings**: Configure your context window size, temperature, and other parameters
+
+### 🧠 Agent State Visualization (Right Panel)
+
+The State Visualization panel provides real-time insights into your agent's internal state:
+
+- **Context Window Viewer**: Examine exactly what information your agent is currently processing
+- **Core Memory Blocks**: View and edit the persistent knowledge your agent maintains
+- **Archival Memory**: Monitor and search your agent's external (out-of-context) memory store
+
+[Learn more about the Context Window Viewer →](/guides/ade/context-window-viewer)
+
+## Getting Started with the ADE
+
+### Connecting to Your Letta Server
+
+The ADE can connect to:
+
+1. A local Letta server running on your machine
+2. A remote Letta server deployed on your infrastructure
+3. [Letta Cloud](/guides/cloud/overview)
+
+For local development, the ADE automatically detects and connects to your local Letta server. For remote servers, you'll need to configure the connection settings in the ADE.
+
+[Learn how to connect the ADE to your server →](/guides/ade/setup)
+
+### Creating Your First Agent
+
+To create a new agent in the ADE:
+
+1. Click the "Create Agent" button in the agents list
+2. Configure basic settings (name, LLM provider, etc.)
+3. Customize the agent's memory blocks (personality, knowledge, etc.)
+4. Add tools to extend the agent's capabilities
+5. Start chatting with your agent to test its behavior
+
+### Customizing Your Agent
+
+The ADE makes it easy to iterate on your agent design:
+
+- **Adjust LLM Parameters**: Experiment with different base models
+- **Edit Memory Content**: Watch your agent edit its own memory, or manually edit its memory yourself
+- **Add Custom Tools**: Create and test Python tools that extend your agent's capabilities
+- **Connect Data Sources**: Import documents, websites, or other data to enhance your agent's knowledge
+
+## Next Steps
+
+Ready to start building with the ADE? Check out these resources:
+
+ +
+ +
+## Key Features
+
+### Conversation Visualization
+
+The simulator displays the complete event and conversation (or event) history of your agent, organized chronologically. Each message is color-coded and formatted according to its type for clear differentiation:
+
+- **User Messages**: Messages sent by you (the user) to the agent. These appear on the right side of the conversation view.
+- **Agent Messages**: Responses generated by the agent and directed to the user. These appear on the left side of the conversation view.
+- **System Messages**: Non-user messages that represent events or notifications, such as `[Alert] The user just logged on` or `[Notification] File upload completed`. These provide context about events happening in the environment.
+- **Function (Tool) Messages** : Detailed records of tool executions, including:
+ - Tool calls made by the agent
+ - Arguments passed to the tools
+ - Results returned by the tools
+ - Any errors encountered during execution
+
+If an error occurs during tool execution, the agent is given an opportunity to handle the error and continue execution by calling the tool again.
+The simulator supports real-time streaming of agent responses, allowing you to see the agent's thought process as it happens.
+
+
+
+## Key Features
+
+### Conversation Visualization
+
+The simulator displays the complete event and conversation (or event) history of your agent, organized chronologically. Each message is color-coded and formatted according to its type for clear differentiation:
+
+- **User Messages**: Messages sent by you (the user) to the agent. These appear on the right side of the conversation view.
+- **Agent Messages**: Responses generated by the agent and directed to the user. These appear on the left side of the conversation view.
+- **System Messages**: Non-user messages that represent events or notifications, such as `[Alert] The user just logged on` or `[Notification] File upload completed`. These provide context about events happening in the environment.
+- **Function (Tool) Messages** : Detailed records of tool executions, including:
+ - Tool calls made by the agent
+ - Arguments passed to the tools
+ - Results returned by the tools
+ - Any errors encountered during execution
+
+If an error occurs during tool execution, the agent is given an opportunity to handle the error and continue execution by calling the tool again.
+The simulator supports real-time streaming of agent responses, allowing you to see the agent's thought process as it happens.
+
+ +
+ +
+## Managing Agent Tools
+
+### Viewing Current Tools
+
+The Tools panel displays all tools currently attached to your agent, showing both built-in Letta tool (which can be detached), as well as custom tools that you have created and attached to the agent.
+
+### Adding Tools
+
+Adding tools to your agent is a straightforward process:
+
+1. Click the "Add Tool" button in the Tools panel
+2. Browse the tool library or search for specific tools
+3. Select a tool to view its details
+4. Click "Add to Agent" to attach it
+
+The tool will immediately become available to your agent without requiring a restart or recreation of the agent.
+
+### Removing Tools
+
+To remove a tool from your agent:
+
+1. Locate the tool in the Tools panel
+2. Click the three-dot menu next to the tool
+3. Select "Remove Tool"
+
+The tool will be detached from your agent but remains in your tool library for future use.
+
+## Creating Custom Tools
+
+For more information on creating custom tools, see our main [tools documentation](/guides/agents/tools).
+
+
+
+## Managing Agent Tools
+
+### Viewing Current Tools
+
+The Tools panel displays all tools currently attached to your agent, showing both built-in Letta tool (which can be detached), as well as custom tools that you have created and attached to the agent.
+
+### Adding Tools
+
+Adding tools to your agent is a straightforward process:
+
+1. Click the "Add Tool" button in the Tools panel
+2. Browse the tool library or search for specific tools
+3. Select a tool to view its details
+4. Click "Add to Agent" to attach it
+
+The tool will immediately become available to your agent without requiring a restart or recreation of the agent.
+
+### Removing Tools
+
+To remove a tool from your agent:
+
+1. Locate the tool in the Tools panel
+2. Click the three-dot menu next to the tool
+3. Select "Remove Tool"
+
+The tool will be detached from your agent but remains in your tool library for future use.
+
+## Creating Custom Tools
+
+For more information on creating custom tools, see our main [tools documentation](/guides/agents/tools).
+
+ +
+ +
+
+## Connecting to a Remote Server
+
+For production environments or team collaboration, you may want to connect to a Letta server running on a remote machine:
+
+
+
+
+## Connecting to a Remote Server
+
+For production environments or team collaboration, you may want to connect to a Letta server running on a remote machine:
+
+ +
+ +
+## Managing Server Connections
+
+The ADE allows you to manage multiple server connections:
+
+### Saving Server Connections
+
+Once you add a remote server, it will be saved in your browser's local storage for easy access in future sessions. To manage saved connections:
+
+1. Click on the server dropdown in the left panel
+2. Select "Manage servers" to view all saved connections
+3. Use the options to edit or remove servers from your list
+
+### Switching Between Servers
+
+You can easily switch between different Letta servers:
+
+1. Click on the current server name in the left panel
+2. Select a different server from the dropdown list
+3. The ADE will connect to the selected server and display its agents
+
+This flexibility allows you to work with development, staging, and production environments from a single ADE interface.
diff --git a/fern/pages/advanced/custom_memory.mdx b/fern/pages/advanced/custom_memory.mdx
new file mode 100644
index 00000000..9c859272
--- /dev/null
+++ b/fern/pages/advanced/custom_memory.mdx
@@ -0,0 +1,75 @@
+---
+title: Creating custom memory classes
+subtitle: Learn how to create custom memory classes
+slug: guides/agents/custom-memory
+---
+
+
+## Customizing in-context memory management
+
+We can extend both the `BaseMemory` and `ChatMemory` classes to implement custom in-context memory management for agents.
+For example, you can add an additional memory section to "human" and "persona" such as "organization".
+
+In this example, we'll show how to implement in-context memory management that treats memory as a task queue.
+We'll call this `TaskMemory` and extend the `ChatMemory` class so that we have both the original `ChatMemory` tools (`core_memory_replace` & `core_memory_append`) as well as the "human" and "persona" fields.
+
+We show an implementation of `TaskMemory` below:
+```python
+from letta.memory import ChatMemory, MemoryModule
+from typing import Optional, List
+
+class TaskMemory(ChatMemory):
+
+ def __init__(self, human: str, persona: str, tasks: List[str]):
+ super().__init__(human=human, persona=persona)
+ self.memory["tasks"] = MemoryModule(limit=2000, value=tasks) # create an empty list
+
+
+
+ def task_queue_push(self, task_description: str) -> Optional[str]:
+ """
+ Push to a task queue stored in core memory.
+
+ Args:
+ task_description (str): A description of the next task you must accomplish.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory["tasks"].value.append(task_description)
+ return None
+
+ def task_queue_pop(self) -> Optional[str]:
+ """
+ Get the next task from the task queue
+
+ Returns:
+ Optional[str]: The description of the task popped from the queue,
+ if there are still tasks in queue. Otherwise, returns None (the
+ task queue is empty)
+ """
+ if len(self.memory["tasks"].value) == 0:
+ return None
+ task = self.memory["tasks"].value[0]
+ self.memory["tasks"].value = self.memory["tasks"].value[1:]
+ return task
+```
+
+To create an agent with this custom memory type, we can simply pass in an instance of `TaskMemory` into the agent creation.
+We also will modify the persona of the agent to explain how the "tasks" section of memory should be used:
+```python
+task_agent_state = client.create_agent(
+ name="task_agent",
+ memory=TaskMemory(
+ human="My name is Sarah",
+ persona="You have an additional section of core memory called `tasks`. " \
+ + "This section of memory contains of list of tasks you must do." \
+ + "Use the `task_queue_push` tool to write down tasks so you don't forget to do them." \
+ + "If there are tasks in the task queue, you should call `task_queue_pop` to retrieve and remove them. " \
+ + "Keep calling `task_queue_pop` until there are no more tasks in the queue. " \
+ + "Do *not* call `send_message` until you have completed all tasks in your queue. " \
+ + "If you call `task_queue_pop`, you must always do what the popped task specifies",
+ tasks=["start calling yourself Bob", "tell me a haiku with my name"],
+ )
+)
+```
diff --git a/fern/pages/advanced/memory_management.mdx b/fern/pages/advanced/memory_management.mdx
new file mode 100644
index 00000000..d6fa46f4
--- /dev/null
+++ b/fern/pages/advanced/memory_management.mdx
@@ -0,0 +1,101 @@
+---
+title: Understanding memory management
+subtitle: Understanding the concept of LLM memory management introduced in MemGPT
+slug: advanced/memory_management
+---
+
+
+Letta uses the MemGPT memory management technique to control the context window of the LLM.
+
+The behavior of an agent is determine by two things: the underlying LLM model, and the context window that is passed to that model.
+Letta provides a framework for "programming" how the context is compiled at each reasoning step, a process which we refer to as memory management for agents.
+
+Unlike existing RAG-based frameworks for long-running memory, MemGPT provides a more flexible, powerful framework for memory management by enabling the agent to self-manage memory via tool calls.
+Essentially, the agent itself gets to decide what information to place into its context at any given time. We reserve a section of the context, which we call the in-context memory, which is agent as the ability to directly write to.
+In addition, the agent is given tools to access external storage (i.e. database tables) to enable a larger memory store.
+Combining tools to write to both its in-context and external memory, as well as tools to search external memory and place results into the LLM context, is what allows MemGPT agents to perform memory management.
+
+## In-context memory
+
+The in-context memory is a section of the LLM context window that is reserved to be editable by the agent.
+You can think of this like a system prompt, except the system prompt it editable (MemGPT also has an actual system prompt which is not editable by the agent).
+
+In MemGPT, the in-context memory is defined by extending the BaseMemory class. The memory class consists of:
+* A self.memory dictionary that maps labeled sections of memory (e.g. "human", "persona") to a MemoryModuleobject, which contains the data for that section of memory as well as the character limit (default: 2k)
+* A set of class functions which can be used to edit the data in each MemoryModulecontained in self.memory
+
+We'll show each of these components in the default ChatMemory class described below.
+
+## ChatMemory Memory
+By default, agents have a ChatMemory memory class, which is designed for a 1:1 chat between a human and agent. The ChatMemory class consists of:
+* A "human" and "persona" memory sections each with a 2k character limit
+* Memory editing functions: memory_insert, memory_replace, memory_rethink, and memory_finish_edits
+* Legacy functions (deprecated): core_memory_replace and core_memory_append
+
+We show the implementation of ChatMemory below:
+```python
+from memgpt.memory import BaseMemory
+
+class ChatMemory(BaseMemory):
+
+ def __init__(self, persona: str, human: str, limit: int = 2000):
+ self.memory = {
+ "persona": MemoryModule(name="persona", value=persona, limit=limit),
+ "human": MemoryModule(name="human", value=human, limit=limit),
+ }
+
+ def core_memory_append(self, name: str, content: str) -> Optional[str]:
+ """
+ Append to the contents of core memory.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value += "\n" + content
+ return None
+
+ def core_memory_replace(self, name: str, old_content: str, new_content: str) -> Optional[str]:
+ """
+ Replace the contents of core memory. To delete memories, use an empty string for new_content.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ old_content (str): String to replace. Must be an exact match.
+ new_content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value = self.memory[name].value.replace(old_content, new_content)
+ return None
+```
+
+To customize memory, you can implement extensions of the BaseMemory class that customize the memory dictionary and the memory editing functions.
+
+## External memory
+
+In-context memory is inherently limited in size, as all its state must be included in the context window.
+To allow additional memory in external storage, MemGPT by default stores two external tables: archival memory (for long running memories that do not fit into the context) and recall memory (for conversation history).
+
+### Archival memory
+Archival memory is a table in a vector DB that can be used to store long running memories of the agent, as well external data that the agent needs access too (referred to as a "Data Source"). The agent is by default provided with a read and write tool to archival memory:
+* archival_memory_search
+* archival_memory_insert
+
+### Recall memory
+Recall memory is a table which MemGPT logs all the conversational history with an agent. The agent is by default provided with date search and text search tools to retrieve conversational history.
+* conversation_search
+* conversation_search_date
+
+(Note: a tool to insert data is not provided since chat histories are automatically inserted.)
+
+## Orchestrating Tools for Memory Management
+
+We provide the agent with a list of default tools for interacting with both in-context and external memory.
+The way these tools are used to manage memory is controlled by the tool descriptions as well as the MemGPT system prompt.
+None of these tools are required for MemGPT to work, so you can remove or override tools to customize memory.
+We encourage developers to extend the BaseMemory class to customize the in-context memory management for their own applications.
diff --git a/fern/pages/agent-development-environment/ade.mdx b/fern/pages/agent-development-environment/ade.mdx
new file mode 100644
index 00000000..39c2df98
--- /dev/null
+++ b/fern/pages/agent-development-environment/ade.mdx
@@ -0,0 +1,147 @@
+---
+title: ADE overview
+subtitle: How to use the Agent Development Environment
+slug: agent-development-environment/ade
+---
+
+
+
+
+
+
+
+## Managing Server Connections
+
+The ADE allows you to manage multiple server connections:
+
+### Saving Server Connections
+
+Once you add a remote server, it will be saved in your browser's local storage for easy access in future sessions. To manage saved connections:
+
+1. Click on the server dropdown in the left panel
+2. Select "Manage servers" to view all saved connections
+3. Use the options to edit or remove servers from your list
+
+### Switching Between Servers
+
+You can easily switch between different Letta servers:
+
+1. Click on the current server name in the left panel
+2. Select a different server from the dropdown list
+3. The ADE will connect to the selected server and display its agents
+
+This flexibility allows you to work with development, staging, and production environments from a single ADE interface.
diff --git a/fern/pages/advanced/custom_memory.mdx b/fern/pages/advanced/custom_memory.mdx
new file mode 100644
index 00000000..9c859272
--- /dev/null
+++ b/fern/pages/advanced/custom_memory.mdx
@@ -0,0 +1,75 @@
+---
+title: Creating custom memory classes
+subtitle: Learn how to create custom memory classes
+slug: guides/agents/custom-memory
+---
+
+
+## Customizing in-context memory management
+
+We can extend both the `BaseMemory` and `ChatMemory` classes to implement custom in-context memory management for agents.
+For example, you can add an additional memory section to "human" and "persona" such as "organization".
+
+In this example, we'll show how to implement in-context memory management that treats memory as a task queue.
+We'll call this `TaskMemory` and extend the `ChatMemory` class so that we have both the original `ChatMemory` tools (`core_memory_replace` & `core_memory_append`) as well as the "human" and "persona" fields.
+
+We show an implementation of `TaskMemory` below:
+```python
+from letta.memory import ChatMemory, MemoryModule
+from typing import Optional, List
+
+class TaskMemory(ChatMemory):
+
+ def __init__(self, human: str, persona: str, tasks: List[str]):
+ super().__init__(human=human, persona=persona)
+ self.memory["tasks"] = MemoryModule(limit=2000, value=tasks) # create an empty list
+
+
+
+ def task_queue_push(self, task_description: str) -> Optional[str]:
+ """
+ Push to a task queue stored in core memory.
+
+ Args:
+ task_description (str): A description of the next task you must accomplish.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory["tasks"].value.append(task_description)
+ return None
+
+ def task_queue_pop(self) -> Optional[str]:
+ """
+ Get the next task from the task queue
+
+ Returns:
+ Optional[str]: The description of the task popped from the queue,
+ if there are still tasks in queue. Otherwise, returns None (the
+ task queue is empty)
+ """
+ if len(self.memory["tasks"].value) == 0:
+ return None
+ task = self.memory["tasks"].value[0]
+ self.memory["tasks"].value = self.memory["tasks"].value[1:]
+ return task
+```
+
+To create an agent with this custom memory type, we can simply pass in an instance of `TaskMemory` into the agent creation.
+We also will modify the persona of the agent to explain how the "tasks" section of memory should be used:
+```python
+task_agent_state = client.create_agent(
+ name="task_agent",
+ memory=TaskMemory(
+ human="My name is Sarah",
+ persona="You have an additional section of core memory called `tasks`. " \
+ + "This section of memory contains of list of tasks you must do." \
+ + "Use the `task_queue_push` tool to write down tasks so you don't forget to do them." \
+ + "If there are tasks in the task queue, you should call `task_queue_pop` to retrieve and remove them. " \
+ + "Keep calling `task_queue_pop` until there are no more tasks in the queue. " \
+ + "Do *not* call `send_message` until you have completed all tasks in your queue. " \
+ + "If you call `task_queue_pop`, you must always do what the popped task specifies",
+ tasks=["start calling yourself Bob", "tell me a haiku with my name"],
+ )
+)
+```
diff --git a/fern/pages/advanced/memory_management.mdx b/fern/pages/advanced/memory_management.mdx
new file mode 100644
index 00000000..d6fa46f4
--- /dev/null
+++ b/fern/pages/advanced/memory_management.mdx
@@ -0,0 +1,101 @@
+---
+title: Understanding memory management
+subtitle: Understanding the concept of LLM memory management introduced in MemGPT
+slug: advanced/memory_management
+---
+
+
+Letta uses the MemGPT memory management technique to control the context window of the LLM.
+
+The behavior of an agent is determine by two things: the underlying LLM model, and the context window that is passed to that model.
+Letta provides a framework for "programming" how the context is compiled at each reasoning step, a process which we refer to as memory management for agents.
+
+Unlike existing RAG-based frameworks for long-running memory, MemGPT provides a more flexible, powerful framework for memory management by enabling the agent to self-manage memory via tool calls.
+Essentially, the agent itself gets to decide what information to place into its context at any given time. We reserve a section of the context, which we call the in-context memory, which is agent as the ability to directly write to.
+In addition, the agent is given tools to access external storage (i.e. database tables) to enable a larger memory store.
+Combining tools to write to both its in-context and external memory, as well as tools to search external memory and place results into the LLM context, is what allows MemGPT agents to perform memory management.
+
+## In-context memory
+
+The in-context memory is a section of the LLM context window that is reserved to be editable by the agent.
+You can think of this like a system prompt, except the system prompt it editable (MemGPT also has an actual system prompt which is not editable by the agent).
+
+In MemGPT, the in-context memory is defined by extending the BaseMemory class. The memory class consists of:
+* A self.memory dictionary that maps labeled sections of memory (e.g. "human", "persona") to a MemoryModuleobject, which contains the data for that section of memory as well as the character limit (default: 2k)
+* A set of class functions which can be used to edit the data in each MemoryModulecontained in self.memory
+
+We'll show each of these components in the default ChatMemory class described below.
+
+## ChatMemory Memory
+By default, agents have a ChatMemory memory class, which is designed for a 1:1 chat between a human and agent. The ChatMemory class consists of:
+* A "human" and "persona" memory sections each with a 2k character limit
+* Memory editing functions: memory_insert, memory_replace, memory_rethink, and memory_finish_edits
+* Legacy functions (deprecated): core_memory_replace and core_memory_append
+
+We show the implementation of ChatMemory below:
+```python
+from memgpt.memory import BaseMemory
+
+class ChatMemory(BaseMemory):
+
+ def __init__(self, persona: str, human: str, limit: int = 2000):
+ self.memory = {
+ "persona": MemoryModule(name="persona", value=persona, limit=limit),
+ "human": MemoryModule(name="human", value=human, limit=limit),
+ }
+
+ def core_memory_append(self, name: str, content: str) -> Optional[str]:
+ """
+ Append to the contents of core memory.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value += "\n" + content
+ return None
+
+ def core_memory_replace(self, name: str, old_content: str, new_content: str) -> Optional[str]:
+ """
+ Replace the contents of core memory. To delete memories, use an empty string for new_content.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ old_content (str): String to replace. Must be an exact match.
+ new_content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value = self.memory[name].value.replace(old_content, new_content)
+ return None
+```
+
+To customize memory, you can implement extensions of the BaseMemory class that customize the memory dictionary and the memory editing functions.
+
+## External memory
+
+In-context memory is inherently limited in size, as all its state must be included in the context window.
+To allow additional memory in external storage, MemGPT by default stores two external tables: archival memory (for long running memories that do not fit into the context) and recall memory (for conversation history).
+
+### Archival memory
+Archival memory is a table in a vector DB that can be used to store long running memories of the agent, as well external data that the agent needs access too (referred to as a "Data Source"). The agent is by default provided with a read and write tool to archival memory:
+* archival_memory_search
+* archival_memory_insert
+
+### Recall memory
+Recall memory is a table which MemGPT logs all the conversational history with an agent. The agent is by default provided with date search and text search tools to retrieve conversational history.
+* conversation_search
+* conversation_search_date
+
+(Note: a tool to insert data is not provided since chat histories are automatically inserted.)
+
+## Orchestrating Tools for Memory Management
+
+We provide the agent with a list of default tools for interacting with both in-context and external memory.
+The way these tools are used to manage memory is controlled by the tool descriptions as well as the MemGPT system prompt.
+None of these tools are required for MemGPT to work, so you can remove or override tools to customize memory.
+We encourage developers to extend the BaseMemory class to customize the in-context memory management for their own applications.
diff --git a/fern/pages/agent-development-environment/ade.mdx b/fern/pages/agent-development-environment/ade.mdx
new file mode 100644
index 00000000..39c2df98
--- /dev/null
+++ b/fern/pages/agent-development-environment/ade.mdx
@@ -0,0 +1,147 @@
+---
+title: ADE overview
+subtitle: How to use the Agent Development Environment
+slug: agent-development-environment/ade
+---
+
+
+
+
+
+ +
+ +
+The tool creation page allows you to dynamically run your tool (in a sandboxed environment) to help you debug and design your tools.
+Pressing `Run` will attempt to run your tool code with the arguments provided (arguments must be provided in JSON format).
+
+## Agent settings
+
+You can change your agent name and system instructions in the "Agent Settings" panel.
+The agent ID is shown below the agent name, and is what you use to identify your agent when interacting with it via the [Letta APIs / SDKs](https://docs.letta.com/api-reference).
+
+### Changing the LLM model
+You can change the LLM model of your agent to any model registered on the Letta server.
+To enable more models on your Letta server, follow the Letta server [model configuration instructions](/models).
+
+### Changing the embedding model
+
+
+
+## Changing the LLM model
+
+## Configuring the max context length
+
+
+
+## Connecting to an external (self-hosted) server
+
+
diff --git a/fern/pages/agent-development-environment/create.mdx b/fern/pages/agent-development-environment/create.mdx
new file mode 100644
index 00000000..e78a64fc
--- /dev/null
+++ b/fern/pages/agent-development-environment/create.mdx
@@ -0,0 +1,4 @@
+---
+title: Creating Agents in the ADE
+slug: guides/ade/create
+---
diff --git a/fern/pages/agent-development-environment/memory.mdx b/fern/pages/agent-development-environment/memory.mdx
new file mode 100644
index 00000000..664cf181
--- /dev/null
+++ b/fern/pages/agent-development-environment/memory.mdx
@@ -0,0 +1,4 @@
+---
+title: Configuring agent memory
+slug: memory
+---
diff --git a/fern/pages/agent-development-environment/sources.mdx b/fern/pages/agent-development-environment/sources.mdx
new file mode 100644
index 00000000..1c427a8d
--- /dev/null
+++ b/fern/pages/agent-development-environment/sources.mdx
@@ -0,0 +1,4 @@
+---
+title: Connecting data sources
+slug: data-sources
+---
diff --git a/fern/pages/agent-development-environment/tools.mdx b/fern/pages/agent-development-environment/tools.mdx
new file mode 100644
index 00000000..0452c22f
--- /dev/null
+++ b/fern/pages/agent-development-environment/tools.mdx
@@ -0,0 +1,4 @@
+---
+title: Connecting tools to your agent
+slug: tools
+---
diff --git a/fern/pages/agent-development-environment/troubleshooting.mdx b/fern/pages/agent-development-environment/troubleshooting.mdx
new file mode 100644
index 00000000..a312f8f2
--- /dev/null
+++ b/fern/pages/agent-development-environment/troubleshooting.mdx
@@ -0,0 +1,31 @@
+---
+title: Troubleshooting the web ADE
+subtitle: Resolving issues with the [web ADE](https://app.letta.com)
+slug: guides/ade/troubleshooting
+---
+
+
+
+## Agent simulator
+The agent simulator visualizes the event/conversation history of your agent.
+The agent's event history is comprised of *messages*, which can be:
+
+
+
+
+The tool creation page allows you to dynamically run your tool (in a sandboxed environment) to help you debug and design your tools.
+Pressing `Run` will attempt to run your tool code with the arguments provided (arguments must be provided in JSON format).
+
+## Agent settings
+
+You can change your agent name and system instructions in the "Agent Settings" panel.
+The agent ID is shown below the agent name, and is what you use to identify your agent when interacting with it via the [Letta APIs / SDKs](https://docs.letta.com/api-reference).
+
+### Changing the LLM model
+You can change the LLM model of your agent to any model registered on the Letta server.
+To enable more models on your Letta server, follow the Letta server [model configuration instructions](/models).
+
+### Changing the embedding model
+
+
+The tool creation page allows you to dynamically run your tool (in a sandboxed environment) to help you debug and design your tools.
+Pressing `Run` will attempt to run your tool code with the arguments provided (arguments must be provided in JSON format).
+
+## Agent settings
+
+You can change your agent name and system instructions in the "Agent Settings" panel.
+The agent ID is shown below the agent name, and is what you use to identify your agent when interacting with it via the [Letta APIs / SDKs](https://docs.letta.com/api-reference).
+
+### Changing the LLM model
+You can change the LLM model of your agent to any model registered on the Letta server.
+To enable more models on your Letta server, follow the Letta server [model configuration instructions](/models).
+
+### Changing the embedding model
+
+
+
+## Changing the LLM model
+
+## Configuring the max context length
+
+
+
+## Connecting to an external (self-hosted) server
+
+
diff --git a/fern/pages/agent-development-environment/create.mdx b/fern/pages/agent-development-environment/create.mdx
new file mode 100644
index 00000000..e78a64fc
--- /dev/null
+++ b/fern/pages/agent-development-environment/create.mdx
@@ -0,0 +1,4 @@
+---
+title: Creating Agents in the ADE
+slug: guides/ade/create
+---
diff --git a/fern/pages/agent-development-environment/memory.mdx b/fern/pages/agent-development-environment/memory.mdx
new file mode 100644
index 00000000..664cf181
--- /dev/null
+++ b/fern/pages/agent-development-environment/memory.mdx
@@ -0,0 +1,4 @@
+---
+title: Configuring agent memory
+slug: memory
+---
diff --git a/fern/pages/agent-development-environment/sources.mdx b/fern/pages/agent-development-environment/sources.mdx
new file mode 100644
index 00000000..1c427a8d
--- /dev/null
+++ b/fern/pages/agent-development-environment/sources.mdx
@@ -0,0 +1,4 @@
+---
+title: Connecting data sources
+slug: data-sources
+---
diff --git a/fern/pages/agent-development-environment/tools.mdx b/fern/pages/agent-development-environment/tools.mdx
new file mode 100644
index 00000000..0452c22f
--- /dev/null
+++ b/fern/pages/agent-development-environment/tools.mdx
@@ -0,0 +1,4 @@
+---
+title: Connecting tools to your agent
+slug: tools
+---
diff --git a/fern/pages/agent-development-environment/troubleshooting.mdx b/fern/pages/agent-development-environment/troubleshooting.mdx
new file mode 100644
index 00000000..a312f8f2
--- /dev/null
+++ b/fern/pages/agent-development-environment/troubleshooting.mdx
@@ -0,0 +1,31 @@
+---
+title: Troubleshooting the web ADE
+subtitle: Resolving issues with the [web ADE](https://app.letta.com)
+slug: guides/ade/troubleshooting
+---
+
+
+
+## Agent simulator
+The agent simulator visualizes the event/conversation history of your agent.
+The agent's event history is comprised of *messages*, which can be:
+
+
+
+
+The tool creation page allows you to dynamically run your tool (in a sandboxed environment) to help you debug and design your tools.
+Pressing `Run` will attempt to run your tool code with the arguments provided (arguments must be provided in JSON format).
+
+## Agent settings
+
+You can change your agent name and system instructions in the "Agent Settings" panel.
+The agent ID is shown below the agent name, and is what you use to identify your agent when interacting with it via the [Letta APIs / SDKs](https://docs.letta.com/api-reference).
+
+### Changing the LLM model
+You can change the LLM model of your agent to any model registered on the Letta server.
+To enable more models on your Letta server, follow the Letta server [model configuration instructions](/models).
+
+### Changing the embedding model
+ +
+
+
+## What is Agent File?
+
+Agent Files package all components of a stateful agent:
+- System prompts
+- Editable memory (personality and user information)
+- Tool configurations (code and schemas)
+- LLM settings
+
+By standardizing these elements in a single format, Agent File enables seamless transfer between compatible frameworks, while allowing for easy checkpointing and version control of agent state.
+
+## Why Use Agent File?
+
+The AI ecosystem is experiencing rapid growth in agent development, with each framework implementing its own storage mechanisms. Agent File addresses the need for a standard that enables:
+
+- **Portability**: Move agents between systems or deploy them to new environments
+- **Collaboration**: Share your agents with other developers and the community
+- **Preservation**: Archive agent configurations to preserve your work
+- **Versioning**: Track changes to agents over time through a standardized format
+
+## What State Does `.af` Include?
+
+A `.af` file contains all the state required to re-create the exact same agent:
+
+| Component | Description |
+|-----------|-------------|
+| Model configuration | Context window limit, model name, embedding model name |
+| Message history | Complete chat history with `in_context` field indicating if a message is in the current context window |
+| System prompt | Initial instructions that define the agent's behavior |
+| Memory blocks | In-context memory segments for personality, user info, etc. |
+| Tool rules | Definitions of how tools should be sequenced or constrained |
+| Environment variables | Configuration values for tool execution |
+| Tools | Complete tool definitions including source code and JSON schema |
+
+## Using Agent File with Letta
+
+### Importing Agents
+
+You can import `.af` files using the Agent Development Environment (ADE), REST APIs, or developer SDKs.
+
+#### Using ADE
+
+Upload downloaded `.af` files directly through the ADE interface to easily re-create your agent.
+
+
+
+
+
+
+## What is Agent File?
+
+Agent Files package all components of a stateful agent:
+- System prompts
+- Editable memory (personality and user information)
+- Tool configurations (code and schemas)
+- LLM settings
+
+By standardizing these elements in a single format, Agent File enables seamless transfer between compatible frameworks, while allowing for easy checkpointing and version control of agent state.
+
+## Why Use Agent File?
+
+The AI ecosystem is experiencing rapid growth in agent development, with each framework implementing its own storage mechanisms. Agent File addresses the need for a standard that enables:
+
+- **Portability**: Move agents between systems or deploy them to new environments
+- **Collaboration**: Share your agents with other developers and the community
+- **Preservation**: Archive agent configurations to preserve your work
+- **Versioning**: Track changes to agents over time through a standardized format
+
+## What State Does `.af` Include?
+
+A `.af` file contains all the state required to re-create the exact same agent:
+
+| Component | Description |
+|-----------|-------------|
+| Model configuration | Context window limit, model name, embedding model name |
+| Message history | Complete chat history with `in_context` field indicating if a message is in the current context window |
+| System prompt | Initial instructions that define the agent's behavior |
+| Memory blocks | In-context memory segments for personality, user info, etc. |
+| Tool rules | Definitions of how tools should be sequenced or constrained |
+| Environment variables | Configuration values for tool execution |
+| Tools | Complete tool definitions including source code and JSON schema |
+
+## Using Agent File with Letta
+
+### Importing Agents
+
+You can import `.af` files using the Agent Development Environment (ADE), REST APIs, or developer SDKs.
+
+#### Using ADE
+
+Upload downloaded `.af` files directly through the ADE interface to easily re-create your agent.
+
+
+  +
+
+
+
+
+ +
+
+
+
+
+
+ +
+ +
+
+
+
+
+MemGPT agents
+Agents that can edit their own memory
+
+ +
+ +
+
+
+
+
+Sleep-time agents
+Memory editing via subconscious agents
+
+ +
+ +
+
+
+
+
+Low-latency (voice) agents
+Agents optimized for low-latency settings
+
+ +
+ +
+
+
+
+
+ReAct agents
+Tool-calling agents without memory
+
+ +
+ +
+
+
+
+
+Workflows
+LLMs executing sequential tool calls
+
+ +
+ +
+
+
+
+Stateful workflows
+Workflows that can adapt over time
+ +
+
+
+ +
+### Attaching a Tool to a Letta Agent
+To give your agent access to the tool, you need to click **Attach Tool**. Once the tool is successfully attached (you will see it in the tools panel in the main ADE view), your agent will be able to use the tool.
+Let's try getting the example agent to use the Tavily search tool:
+
+
+### Attaching a Tool to a Letta Agent
+To give your agent access to the tool, you need to click **Attach Tool**. Once the tool is successfully attached (you will see it in the tools panel in the main ADE view), your agent will be able to use the tool.
+Let's try getting the example agent to use the Tavily search tool:
+ +
+If we click on the tool execution button in the chat, we can see the exact inputs to the Composio tool, and the exact outputs from the tool:
+
+
+If we click on the tool execution button in the chat, we can see the exact inputs to the Composio tool, and the exact outputs from the tool:
+ +
+## Using entities in Composio tools
+
+
+## Using entities in Composio tools
+ +
+You can also assign tool variables on agent creation in the API with the `tool_exec_environment_variables` parameter (see [examples here](/guides/agents/tool-variables)).
+
+## Entities in Composio tools for multi-user
+In multi-user settings (where you have many users all using different agents), you may want to use the concept of [entities](https://docs.composio.dev/patterns/Auth/connected_account#entities) in Composio, which allow you to scope Composio tool execution to specific users.
+
+For example, let's say you're using Letta to create an application where users each get their own personal secretary that can schedule their calendar. As a developer, you only have one `COMPOSIO_API_KEY` to manage the connection between Letta and Composio, but you want to make associate each Composio tool call from a specific agent with a specific user.
+
+Composio allows you to do this through **entities**: each **user** on your Composio account will have a unique Composio entity ID, and in Letta each **agent** will be associated with a specific Composio entity ID.
+
+## Adding Composio tools to agents in the Python SDK
+
+
+You can also assign tool variables on agent creation in the API with the `tool_exec_environment_variables` parameter (see [examples here](/guides/agents/tool-variables)).
+
+## Entities in Composio tools for multi-user
+In multi-user settings (where you have many users all using different agents), you may want to use the concept of [entities](https://docs.composio.dev/patterns/Auth/connected_account#entities) in Composio, which allow you to scope Composio tool execution to specific users.
+
+For example, let's say you're using Letta to create an application where users each get their own personal secretary that can schedule their calendar. As a developer, you only have one `COMPOSIO_API_KEY` to manage the connection between Letta and Composio, but you want to make associate each Composio tool call from a specific agent with a specific user.
+
+Composio allows you to do this through **entities**: each **user** on your Composio account will have a unique Composio entity ID, and in Letta each **agent** will be associated with a specific Composio entity ID.
+
+## Adding Composio tools to agents in the Python SDK
+`memory_replace`
`memory_insert`
& custom tools | Recommended <50k characters | Recommended <20 blocks per agent | +| **Files** | Read-only | Partial (files can be opened/closed) | `open`
`close`
`semantic_search`
`grep` | 5MB | Recommended <100 files per agent | +| **Archival Memory** | Read-write | No | `archival_memory_insert`
`archival_memory_search`
& custom tools | 300 tokens | Unlimited | +| **External RAG** | Read-write | No | Custom tools or MCP | Unlimited | Unlimited | + +## Examples + Below are examples of when to use which abstraction type: + +| **Example Use Case** | **Recommended Abstraction** | +|---|---| +| Storing very important memories formed by the agent that always need to be remembered (e.g. "user's name is Sarah") | Memory Blocks | +| Giving your agent access to company communication guidelines that is a 1-2 pages long | Memory Blocks | +| Giving your agent access to company documentation that is 100s of pages long or consists of dozens of files | Files | +| Storing less important memories formed by the agent that do not always need to be recalled (e.g. "Today Sarah and I talked about our favorite foods and it was pretty funny") | Archival Memory | +| Giving your agent access to millions of documents you have scraped | External RAG | diff --git a/fern/pages/agents/custom_tools.mdx b/fern/pages/agents/custom_tools.mdx new file mode 100644 index 00000000..32574771 --- /dev/null +++ b/fern/pages/agents/custom_tools.mdx @@ -0,0 +1,194 @@ +--- +title: Define and customize tools +slug: guides/agents/custom-tools +--- + +You can create custom tools in Letta using the Python SDK, as well as via the [ADE tool builder](/guides/ade/tools). + +For your agent to call a tool, Letta constructs an OpenAI tool schema (contained in `json_schema` field) from the function you define. Letta can either parse this automatically from a properly formatting docstring, or you can pass in the schema explicitly by providing a Pydantic object that defines the argument schema. + +## Creating a custom tool + +### Specifying tools via Pydantic models +To create a custom tool, you can extend the `BaseTool` class and specify the following: +* `name` - The name of the tool +* `args_schema` - A Pydantic model that defines the arguments for the tool +* `description` - A description of the tool +* `tags` - (Optional) A list of tags for the tool to query +You must also define a `run(..)` method for the tool code that takes in the fields from the `args_schema`. + +Below is an example of how to create a tool by extending `BaseTool`: +```python title="python" maxLines=50 +from letta_client import Letta +from letta_client.client import BaseTool +from pydantic import BaseModel +from typing import List, Type + +class InventoryItem(BaseModel): + sku: str # Unique product identifier + name: str # Product name + price: float # Current price + category: str # Product category (e.g., "Electronics", "Clothing") + +class InventoryEntry(BaseModel): + timestamp: int # Unix timestamp of the transaction + item: InventoryItem # The product being updated + transaction_id: str # Unique identifier for this inventory update + +class InventoryEntryData(BaseModel): + data: InventoryEntry + quantity_change: int # Change in quantity (positive for additions, negative for removals) + + +class ManageInventoryTool(BaseTool): + name: str = "manage_inventory" + args_schema: Type[BaseModel] = InventoryEntryData + description: str = "Update inventory catalogue with a new data entry" + tags: List[str] = ["inventory", "shop"] + + def run(self, data: InventoryEntry, quantity_change: int) -> bool: + print(f"Updated inventory for {data.item.name} with a quantity change of {quantity_change}") + return True + +# create a client to connect to your local Letta server +client = Letta( + base_url="http://localhost:8283" +) +# create the tool +tool_from_class = client.tools.add( + tool=ManageInventoryTool(), +) +``` + +### Specifying tools via function docstrings +You can create a tool by passing in a function with a [Google Style Python docstring](https://google.github.io/styleguide/pyguide.html#383-functions-and-methods) specifying the arguments and description of the tool: +```python title="python" maxLines=50 +# install letta_client with `pip install letta-client` +from letta_client import Letta + +# create a client to connect to your local Letta server +client = Letta( + base_url="http://localhost:8283" +) + +# define a function with a docstring +def roll_dice() -> str: + """ + Simulate the roll of a 20-sided die (d20). + + This function generates a random integer between 1 and 20, inclusive, + which represents the outcome of a single roll of a d20. + + Returns: + str: The result of the die roll. + """ + import random + + dice_role_outcome = random.randint(1, 20) + output_string = f"You rolled a {dice_role_outcome}" + return output_string + +# create the tool +tool = client.tools.create_from_function( + func=roll_dice +) +``` +The tool creation will return a `Tool` object. You can update the tool with `client.tools.upsert_from_function(...)`. + + +### Specifying arguments via Pydantic models +To specify the arguments for a complex tool, you can use the `args_schema` parameter. + +```python title="python" maxLines=50 +# install letta_client with `pip install letta-client` +from letta_client import Letta + +class Step(BaseModel): + name: str = Field( + ..., + description="Name of the step.", + ) + description: str = Field( + ..., + description="An exhaustic description of what this step is trying to achieve and accomplish.", + ) + + +class StepsList(BaseModel): + steps: list[Step] = Field( + ..., + description="List of steps to add to the task plan.", + ) + explanation: str = Field( + ..., + description="Explanation for the list of steps.", + ) + +def create_task_plan(steps, explanation): + """ Creates a task plan for the current task. """ + return steps + + +tool = client.tools.upsert_from_function( + func=create_task_plan, + args_schema=StepsList +) +``` +Note: this path for updating tools is currently only supported in Python. + +### Creating a tool from a file +You can also define a tool from a file that contains source code. For example, you may have the following file: +```python title="custom_tool.py" maxLines=50 +from typing import List, Optional +from pydantic import BaseModel, Field + + +class Order(BaseModel): + order_number: int = Field( + ..., + description="The order number to check on.", + ) + customer_name: str = Field( + ..., + description="The customer name to check on.", + ) + +def check_order_status( + orders: List[Order] +): + """ + Check status of a provided list of orders + + Args: + orders (List[Order]): List of orders to check + + Returns: + str: The status of the order (e.g. cancelled, refunded, processed, processing, shipping). + """ + # TODO: implement + return "ok" + +``` +Then, you can define the tool in Letta via the `source_code` parameter: +```python title="python" maxLines=50 +tool = client.tools.create( + source_code = open("custom_tool.py", "r").read() +) +``` +Note that in this case, `check_order_status` will become the name of your tool, since it is the last Python function in the file. Make sure it includes a [Google Style Python docstring](https://google.github.io/styleguide/pyguide.html#383-functions-and-methods) to define the tool’s arguments and description. + +# (Advanced) Accessing Agent State +
Research Papers] + DS2[Folder 2
Medical Records] + end + + subgraph "Files" + F1[paper1.pdf] + F2[paper2.pdf] + F3[patient_record.txt] + F4[lab_results.json] + end + + subgraph "Letta Agents" + A1[Agent 1] + A2[Agent 2] + A3[Agent 3] + end + + DS1 --> F1 + DS1 --> F2 + DS2 --> F3 + DS2 --> F4 + + A2 -.->|attached to| DS1 + A2 -.->|attached to| DS2 + A3 -.->|attached to| DS2 +``` + +Once a file has been uploaded to a folder, the agent can access it using a set of **file tools**. +The file is automatically chunked and embedded to allow the agent to use semantic search to find relevant information in the file (in addition to standard text-based search). + +
Approval?} + Check -->|No| Execute[Execute Tool] + Check -->|Yes| Request[Request Approval] + Request --> Human[Human Review] + Human -->|Approve| Execute + Human -->|Deny| Error[Return Error] + Execute --> Result[Return Result] + Error --> Agent + Result --> Agent +``` + +## Overview + +When a tool is marked as requiring approval, the agent will pause execution and wait for human approval or denial before proceeding. This creates a checkpoint in the agent's workflow where human judgment can be applied. The approval workflow is designed to be non-blocking and supports both synchronous and streaming message interfaces, making it suitable for interactive applications as well as batch processing systems. + +### Key Benefits + +- **Risk Mitigation**: Prevent unintended actions in production environments +- **Cost Control**: Review expensive operations before execution +- **Compliance**: Ensure human oversight for regulated operations +- **Quality Assurance**: Validate agent decisions before critical actions + +### How It Works + +The approval workflow follows a clear sequence of steps that ensures human oversight at critical decision points: + +1. **Tool Configuration**: Mark specific tools as requiring approval either globally (default for all agents) or per-agent +2. **Execution Pause**: When the agent attempts to call a protected tool, it immediately pauses and returns an approval request message +3. **Human Review**: The approval request includes the tool name, arguments, and context, allowing you to make an informed decision +4. **Approval/Denial**: Send an approval response to either execute the tool or provide feedback for the agent to adjust its approach +5. **Continuation**: The agent receives the tool result (on approval) or an error message (on denial) and continues processing + + +## Best Practices + +Following these best practices will help you implement effective human-in-the-loop workflows while maintaining a good user experience and system performance. + +### 1. Selective Tool Marking + +Not every tool needs human approval. Be strategic about which tools require oversight to avoid workflow bottlenecks while maintaining necessary controls: + +**Tools that typically require approval:** +- Database write operations (INSERT, UPDATE, DELETE) +- External API calls with financial implications +- File system modifications or deletions +- Communication tools (email, SMS, notifications) +- System configuration changes +- Third-party service integrations with rate limits + +### 2. Clear Denial Reasons + +When denying a request, your feedback directly influences how the agent adjusts its approach. Provide specific, actionable guidance rather than vague rejections: + +```python +# Good: Specific and actionable +"reason": "Use read-only query first to verify the data before deletion" + +# Bad: Too vague +"reason": "Don't do that" +``` + +The agent will use your denial reason to reformulate its approach, so the more specific you are, the better the agent can adapt. + +## Setting Up Approval Requirements + +There are two methods for configuring tool approval requirements, each suited for different use cases. Choose the approach that best fits your security model and operational needs. + +### Method 1: Create/Upsert Tool with Default Approval Requirement + +Set approval requirements at the tool level when creating or upserting a tool. This approach ensures consistent security policies across all agents that use the tool. The `default_requires_approval` flag will be applied to all future agent-tool attachments: + +
I am a supervisor] + SS[Shared Memory Block
Organization: Letta] + end + + subgraph Worker + W1[Memory Block
I am a worker] + W1S[Shared Memory Block
Organization: Letta] + end + + SS -..- W1S +``` + +In the example code below, we create a shared memory block and attach it to a supervisor agent and a worker agent. +Because the memory block is shared, when one agent writes to it, the other agent can read the updates immediately. + +
 +
+ +
+## Usage Examples (SDK)
+
+### Sending an Image via URL
+
+
+
+## Usage Examples (SDK)
+
+### Sending an Image via URL
+
+ diff --git a/fern/pages/agents/overview.mdx b/fern/pages/agents/overview.mdx
new file mode 100644
index 00000000..17da85c3
--- /dev/null
+++ b/fern/pages/agents/overview.mdx
@@ -0,0 +1,271 @@
+---
+title: Building Stateful Agents with Letta
+slug: guides/agents/overview
+---
+Letta agents can automatically manage long-term memory, load data from external sources, and call custom tools.
+Unlike in other frameworks, Letta agents are stateful, so they keep track of historical interactions and reserve part of their context to read and write memories which evolve over time.
+
diff --git a/fern/pages/agents/overview.mdx b/fern/pages/agents/overview.mdx
new file mode 100644
index 00000000..17da85c3
--- /dev/null
+++ b/fern/pages/agents/overview.mdx
@@ -0,0 +1,271 @@
+---
+title: Building Stateful Agents with Letta
+slug: guides/agents/overview
+---
+Letta agents can automatically manage long-term memory, load data from external sources, and call custom tools.
+Unlike in other frameworks, Letta agents are stateful, so they keep track of historical interactions and reserve part of their context to read and write memories which evolve over time.
+ +
+ +
+
+
+Letta manages a reasoning loop for agents. At each agent step (i.e. iteration of the loop), the state of the agent is checkpointed and persisted to the database.
+
+You can interact with agents from a REST API, the ADE, and TypeScript / Python SDKs.
+As long as they are connected to the same service, all of these interfaces can be used to interact with the same agents.
+
+
+
+
+
+Letta manages a reasoning loop for agents. At each agent step (i.e. iteration of the loop), the state of the agent is checkpointed and persisted to the database.
+
+You can interact with agents from a REST API, the ADE, and TypeScript / Python SDKs.
+As long as they are connected to the same service, all of these interfaces can be used to interact with the same agents.
+
+ +
+ +
+In Letta, you can create special **sleep-time agents** that share the memory of your primary agents, but run in the background and can modify the memory asynchronously. You can think of sleep-time agents as a special form of multi-agent architecture, where all agents in the system share one or more memory blocks. A single agent can have one or more associated sleep-time agents to process data such as the conversation history or data sources to manage the memory blocks of the primary agent.
+
+To enable sleep-time agents for your agent, create the agent with type `sleeptime_agent`. When you create an agent of this type, this will automatically create:
+* A primary agent (i.e. general-purpose agent) tools for `send_message`, `conversation_search`, and `archival_memory_search`. This is your "main" agent that you configure and interact with.
+* A sleep-time agent with tools to manage the memory blocks of the primary agent. It is possible that additional, ephemeral sleep-time agents will be created when you add data into data sources of the primary agent.
+
+## Background: Memory Blocks
+Sleep-time agents specialize in generating *learned context*. Given some original context (e.g. the conversation history, a set of files) the sleep-time agent will reflect on the original context to iteratively derive a learned context. The learned context will reflect the most important pieces of information or insights from the original context.
+
+In Letta, the learned context is saved in a memory block. A memory block represents a labeled section of the context window with an associated character limit. Memory blocks can be shared between multiple agents. A sleep-time agent will write the learned context to a memory block, which can also be shared with other agents that could benefit from those learnings.
+
+Memory blocks can be access directly through the API to be updated, retrieved, or deleted.
+
+
+
+In Letta, you can create special **sleep-time agents** that share the memory of your primary agents, but run in the background and can modify the memory asynchronously. You can think of sleep-time agents as a special form of multi-agent architecture, where all agents in the system share one or more memory blocks. A single agent can have one or more associated sleep-time agents to process data such as the conversation history or data sources to manage the memory blocks of the primary agent.
+
+To enable sleep-time agents for your agent, create the agent with type `sleeptime_agent`. When you create an agent of this type, this will automatically create:
+* A primary agent (i.e. general-purpose agent) tools for `send_message`, `conversation_search`, and `archival_memory_search`. This is your "main" agent that you configure and interact with.
+* A sleep-time agent with tools to manage the memory blocks of the primary agent. It is possible that additional, ephemeral sleep-time agents will be created when you add data into data sources of the primary agent.
+
+## Background: Memory Blocks
+Sleep-time agents specialize in generating *learned context*. Given some original context (e.g. the conversation history, a set of files) the sleep-time agent will reflect on the original context to iteratively derive a learned context. The learned context will reflect the most important pieces of information or insights from the original context.
+
+In Letta, the learned context is saved in a memory block. A memory block represents a labeled section of the context window with an associated character limit. Memory blocks can be shared between multiple agents. A sleep-time agent will write the learned context to a memory block, which can also be shared with other agents that could benefit from those learnings.
+
+Memory blocks can be access directly through the API to be updated, retrieved, or deleted.
+
+ +
+ +
+When a `sleeptime_agent` is created, a primary agent and a sleep-time agent are created as part of a multi-agent group under the hood. The sleep-time agent is responsible for generating learned context from the conversation history to update the memory blocks of the primary agent. The group ensures that for every `N` steps taken by the primary agent, the sleep-time agent is invoked with data containing new messages in the primary agent's message history.
+
+
+
+When a `sleeptime_agent` is created, a primary agent and a sleep-time agent are created as part of a multi-agent group under the hood. The sleep-time agent is responsible for generating learned context from the conversation history to update the memory blocks of the primary agent. The group ensures that for every `N` steps taken by the primary agent, the sleep-time agent is invoked with data containing new messages in the primary agent's message history.
+
+ +
+### Configuring the frequency of sleep-time updates
+The sleep-time agent will be triggered every N-steps (default `5`) to update the memory blocks of the primary agent. You can configure the frequency of updates by setting the `sleeptime_agent_frequency` parameter when creating the agent.
+
+
+
+### Configuring the frequency of sleep-time updates
+The sleep-time agent will be triggered every N-steps (default `5`) to update the memory blocks of the primary agent. You can configure the frequency of updates by setting the `sleeptime_agent_frequency` parameter when creating the agent.
+
+ +
+ +
+Sleep-time-enabled agents will spawn additional ephemeral sleep-time agents when you add data into data sources of the primary agent to process the data sources in the background. These ephemeral agents will create and write to a block specific to the data source, and be deleted once they are finished processing the data sources.
+
+When a file is uploaded to a data source, it is parsed into passages (chunks of text) which are embedded and saved into the main agent's archival memory. If sleeptime is enabled, the sleep-time agent will also process each passage's text to update the memory block corresponding to the data source. The sleep-time agent will create an `instructions` block that contains the data source description, to help guide the learned context generation.
+
+
+
+Sleep-time-enabled agents will spawn additional ephemeral sleep-time agents when you add data into data sources of the primary agent to process the data sources in the background. These ephemeral agents will create and write to a block specific to the data source, and be deleted once they are finished processing the data sources.
+
+When a file is uploaded to a data source, it is parsed into passages (chunks of text) which are embedded and saved into the main agent's archival memory. If sleeptime is enabled, the sleep-time agent will also process each passage's text to update the memory block corresponding to the data source. The sleep-time agent will create an `instructions` block that contains the data source description, to help guide the learned context generation.
+
+ +
+
+
+ +
+Once in the **Environment Variables** viewer, click **+** to add a new tool variable if one does not exist.
+
+
+
+## Assigning tool variables in the API / SDK
+
+You can also assign tool variables on agent creation in the API with the `tool_exec_environment_variables` parameter:
+
+
+Once in the **Environment Variables** viewer, click **+** to add a new tool variable if one does not exist.
+
+
+
+## Assigning tool variables in the API / SDK
+
+You can also assign tool variables on agent creation in the API with the `tool_exec_environment_variables` parameter:
+ +
+## Using your API key
+
+Once you've created an API key, you can use it with any of the Letta SDKs or framework integrations.
+For example, if you're using the Python or TypeScript (Node.js) SDK, you should set the `token` in the client to be your key (replace `LETTA_API_KEY` with your actual API key):
+
+
+## Using your API key
+
+Once you've created an API key, you can use it with any of the Letta SDKs or framework integrations.
+For example, if you're using the Python or TypeScript (Node.js) SDK, you should set the `token` in the client to be your key (replace `LETTA_API_KEY` with your actual API key):
+ +
+ +
+Monitor your agents across four key dashboards:
+
+##
+
+
+Track key metrics across four dashboards:
+- **Overview**: Message count, API/tool errors, LLM/tool latency
+- **Activity & Usage**: Usage patterns and resource consumption
+- **Performance**: Response times and throughput
+- **Errors**: Detailed error analysis and debugging info
+
+## [Responses & Tracing](/guides/observability/responses)
+
+
+
+Monitor your agents across four key dashboards:
+
+##
+
+
+Track key metrics across four dashboards:
+- **Overview**: Message count, API/tool errors, LLM/tool latency
+- **Activity & Usage**: Usage patterns and resource consumption
+- **Performance**: Response times and throughput
+- **Errors**: Detailed error analysis and debugging info
+
+## [Responses & Tracing](/guides/observability/responses)
+
+ +
+ +
+Inspect API responses and agent execution:
+- **API Responses**: List of all responses with duration and status
+- **Message Inspection**: Click "Inspect Message" to see the full POST request and agent loop execution sequence
diff --git a/fern/pages/cloud/overview.mdx b/fern/pages/cloud/overview.mdx
new file mode 100644
index 00000000..12fcdb0d
--- /dev/null
+++ b/fern/pages/cloud/overview.mdx
@@ -0,0 +1,37 @@
+---
+title: Letta Cloud
+subtitle: Deploy stateful agents at scale in the cloud
+slug: guides/cloud/overview
+---
+Letta Cloud is our fully-managed service for stateful agents. While Letta can be self-hosted, Letta Cloud eliminates all infrastructure management, server optimization, and system administration so you can focus entirely on building agents.
+
+## The fastest way to bring stateful agents to production
+
+**Develop faster with any model and 24/7 agent uptime**: Access to OpenAI, Anthropic Claude, and Google Gemini with high rate limits. Our platform automatically scales to meet demand and ensures 24/7 uptime of your agents. Your agents' state, memory, and conversation history are securely persisted.
+
+**Features designed to help you scale to hundreds of agents**: Letta Cloud includes features designed for applications managing large numbers of agents: agent templates, template versioning, memory variables injected on agent creation, and advanced tooling for managing thousands of agents across many users.
+
+## Model agnostic with zero provider lock-in
+
+Your agent state is stored in a model-agnostic format, allowing you to easily migrate your agents (and their memories, message history, reasoning traces, tool execution traces, etc.) from one model provider to another.
+
+Letta Cloud also supports [agent file](/guides/agents/agent-file), which allows you to move your agents freely between self-hosted instances of Letta and Letta Cloud.
+
+You can upload local agents to Cloud by importing their `.af` files, and run Cloud agents locally by downloading and importing them into your self-hosted server.
+
+## Next steps
+
+
+
+
+Debug and analyze your agent's execution with detailed tracing.
+
+##
+
+Inspect API responses and agent execution:
+- **API Responses**: List of all responses with duration and status
+- **Message Inspection**: Click "Inspect Message" to see the full POST request and agent loop execution sequence
diff --git a/fern/pages/cloud/overview.mdx b/fern/pages/cloud/overview.mdx
new file mode 100644
index 00000000..12fcdb0d
--- /dev/null
+++ b/fern/pages/cloud/overview.mdx
@@ -0,0 +1,37 @@
+---
+title: Letta Cloud
+subtitle: Deploy stateful agents at scale in the cloud
+slug: guides/cloud/overview
+---
+Letta Cloud is our fully-managed service for stateful agents. While Letta can be self-hosted, Letta Cloud eliminates all infrastructure management, server optimization, and system administration so you can focus entirely on building agents.
+
+## The fastest way to bring stateful agents to production
+
+**Develop faster with any model and 24/7 agent uptime**: Access to OpenAI, Anthropic Claude, and Google Gemini with high rate limits. Our platform automatically scales to meet demand and ensures 24/7 uptime of your agents. Your agents' state, memory, and conversation history are securely persisted.
+
+**Features designed to help you scale to hundreds of agents**: Letta Cloud includes features designed for applications managing large numbers of agents: agent templates, template versioning, memory variables injected on agent creation, and advanced tooling for managing thousands of agents across many users.
+
+## Model agnostic with zero provider lock-in
+
+Your agent state is stored in a model-agnostic format, allowing you to easily migrate your agents (and their memories, message history, reasoning traces, tool execution traces, etc.) from one model provider to another.
+
+Letta Cloud also supports [agent file](/guides/agents/agent-file), which allows you to move your agents freely between self-hosted instances of Letta and Letta Cloud.
+
+You can upload local agents to Cloud by importing their `.af` files, and run Cloud agents locally by downloading and importing them into your self-hosted server.
+
+## Next steps
+
+
+
+
+Debug and analyze your agent's execution with detailed tracing.
+
+##  +
+ +
+Click **"Inspect Message"** to trace agent execution:
+
+### Request Details
+- Original POST request that triggered the agent
+- All parameters and context information
+
+### Agent Loop Trace
+Step-by-step execution flow:
+1. **Input Processing**: How the server interpreted the request
+3. **Tool Invocations**: Each tool called with parameters, timing, and results
+5. **Memory Updates**: How agent memory was modified
+4. **Agent Messages**: Prompts, responses, and token usage
+6. **Response Completion**: Final response construction
+
+### Debugging Features
+- **Performance**: Identify bottlenecks and optimization opportunities
+- **Errors**: Pinpoint failure points with stack traces
+- **Behavior**: Understand agent decision-making process
diff --git a/fern/pages/cloud/templates.mdx b/fern/pages/cloud/templates.mdx
new file mode 100644
index 00000000..ec7da2ee
--- /dev/null
+++ b/fern/pages/cloud/templates.mdx
@@ -0,0 +1,131 @@
+---
+title: Introduction to Agent Templates
+slug: guides/templates/overview
+---
+
+
+
+Click **"Inspect Message"** to trace agent execution:
+
+### Request Details
+- Original POST request that triggered the agent
+- All parameters and context information
+
+### Agent Loop Trace
+Step-by-step execution flow:
+1. **Input Processing**: How the server interpreted the request
+3. **Tool Invocations**: Each tool called with parameters, timing, and results
+5. **Memory Updates**: How agent memory was modified
+4. **Agent Messages**: Prompts, responses, and token usage
+6. **Response Completion**: Final response construction
+
+### Debugging Features
+- **Performance**: Identify bottlenecks and optimization opportunities
+- **Errors**: Pinpoint failure points with stack traces
+- **Behavior**: Understand agent decision-making process
diff --git a/fern/pages/cloud/templates.mdx b/fern/pages/cloud/templates.mdx
new file mode 100644
index 00000000..ec7da2ee
--- /dev/null
+++ b/fern/pages/cloud/templates.mdx
@@ -0,0 +1,131 @@
+---
+title: Introduction to Agent Templates
+slug: guides/templates/overview
+---
+
+
+
+
+
+ Join our developer community on Discord
+
+
+ Browse and contribute to Letta's open source code
+
+
+
+## Developer Events
+
+
+ Come and hang out with the Letta dev team to chat about the Letta roadmap and upcoming features!
+
+
+ Attend our Bay Area / SF meetups to meet other developers interested in AI research and open source!
+
+
+
+
diff --git a/fern/pages/concepts.mdx b/fern/pages/concepts.mdx
new file mode 100644
index 00000000..5a9de543
--- /dev/null
+++ b/fern/pages/concepts.mdx
@@ -0,0 +1,58 @@
+---
+title: Key concepts
+subtitle: Learn about the key ideas behind Letta
+slug: concepts
+---
+
+
+## MemGPT
+
+**[Letta](https://letta.com)** was created by the same team that created **[MemGPT](https://research.memgpt.ai)**.
+
+**MemGPT a _research paper_** that introduced the idea of self-editing memory in LLMs as well as other "LLM OS" concepts.
+To understand the key ideas behind the MemGPT paper, see our [MemGPT concepts guide](/letta_memgpt).
+
+MemGPT also refers to a particular **agent architecture** popularized by the research paper and open source, where the agent has a particular set of memory tools that make the agent particularly useful for long-range chat applications and document search.
+
+**Letta is a _framework_** that allows you to build complex agents (such as MemGPT agents, or even more complex agent architectures) and run them as **services** behind REST APIs.
+
+The **Letta Cloud platform** allows you easily build and scale agent deployments to power production applications.
+The **Letta ADE** (Agent Developer Environment) is an application for agent developers that makes it easy to design and debug complex agents.
+
+## Agents ("LLM agents")
+Agents are LLM processes which can:
+
+1. Have internal **state** (i.e. memory)
+
+2. Can take **actions** to modify their state
+
+3. Run **autonomously**
+
+Agents have existed as a concept in [reinforcement learning](https://en.wikipedia.org/wiki/Reinforcement_learning) for a long time (as well as in other fields, such as [economics](https://en.wikipedia.org/wiki/Agent_(economics))). In Letta, LLM tool calling is used to both allow agents to run autonomously (by having the LLM determine whether to continue executing) as well as to edit state (by leveraging LLM tool calling.)
+Letta uses a database (DB) backend to manage the internal state of the agent, represented in the `AgentState` object.
+
+## Self-editing memory
+The MemGPT paper introduced the idea of implementing self-editing memory in LLMs. The basic idea is to use LLM tools to allow an agent to both edit its own context window ("core memory"), as well as edit external storage (i.e. "archival memory").
+
+## LLM OS ("operating systems for LLMs")
+The LLM OS is the code that manages the inputs and outputs to the LLM and manages the program state.
+We refer to this code as the "stateful layer" or "memory layer".
+It includes the "agent runtime", which manages the execution of functions requested by the agent, as well as the "agentic loop" which enables multi-step reasoning.
+
+## Persistence ("statefulness")
+In Letta, all state is *persisted* by default. This means that each time the LLM is run, the state of the agent such as its memories, message history, and tools are all persisted to a DB backend.
+
+Because all state is persisted, you can always re-load agents, tools, sources, etc. at a later point in time.
+You can also load the same agent accross multiple machines or services, as long as they can can connect to the same DB backend.
+
+## Agent microservices ("agents-as-a-service")
+Letta follows the model of treating agents as individual services. That is, you interact with agents through a REST API:
+```
+POST /agents/{agent_id}/messages
+```
+Since agents are designed to be services, they can be *deployed* and connected to external applications.
+
+For example, you want to create a personalizated chatbot, you can create an agent per-user, where each agent has its own custom memory about the individual user.
+
+## Stateful vs stateless APIs
+`ChatCompletions` is the standard for interacting with LLMs as a service. Since it is a stateless API (no notion of sessions or identify accross requests, and no state management on the server-side), client-side applications must manage things like agent memory, user personalization, and message history, and translate this state back into the `ChatCompletions` API format. Letta's APIs are designed to be *stateful*, so that this state management is done on the server, not the client.
diff --git a/fern/pages/concepts/letta.mdx b/fern/pages/concepts/letta.mdx
new file mode 100644
index 00000000..0d559b25
--- /dev/null
+++ b/fern/pages/concepts/letta.mdx
@@ -0,0 +1,58 @@
+---
+title: Key concepts
+subtitle: Learn about the key ideas behind Letta
+slug: concepts/letta
+---
+
+
+## MemGPT
+
+**[Letta](https://letta.com)** was created by the same team that created **[MemGPT](https://research.memgpt.ai)**.
+
+**MemGPT a _research paper_** that introduced the idea of self-editing memory in LLMs as well as other "LLM OS" concepts.
+To understand the key ideas behind the MemGPT paper, see our [MemGPT concepts guide](/letta_memgpt).
+
+MemGPT also refers to a particular **agent architecture** popularized by the research paper and open source, where the agent has a particular set of memory tools that make the agent particularly useful for long-range chat applications and document search.
+
+**Letta is a _framework_** that allows you to build complex agents (such as MemGPT agents, or even more complex agent architectures) and run them as **services** behind REST APIs.
+
+The **Letta Cloud platform** allows you easily build and scale agent deployments to power production applications.
+The **Letta ADE** (Agent Developer Environment) is an application for agent developers that makes it easy to design and debug complex agents.
+
+## Agents ("LLM agents")
+Agents are LLM processes which can:
+
+1. Have internal **state** (i.e. memory)
+
+2. Can take **actions** to modify their state
+
+3. Run **autonomously**
+
+Agents have existed as a concept in [reinforcement learning](https://en.wikipedia.org/wiki/Reinforcement_learning) for a long time (as well as in other fields, such as [economics](https://en.wikipedia.org/wiki/Agent_(economics))). In Letta, LLM tool calling is used to both allow agents to run autonomously (by having the LLM determine whether to continue executing) as well as to edit state (by leveraging LLM tool calling.)
+Letta uses a database (DB) backend to manage the internal state of the agent, represented in the `AgentState` object.
+
+## Self-editing memory
+The MemGPT paper introduced the idea of implementing self-editing memory in LLMs. The basic idea is to use LLM tools to allow an agent to both edit its own context window ("core memory"), as well as edit external storage (i.e. "archival memory").
+
+## LLM OS ("operating systems for LLMs")
+The LLM OS is the code that manages the inputs and outputs to the LLM and manages the program state.
+We refer to this code as the "stateful layer" or "memory layer".
+It includes the "agent runtime", which manages the execution of functions requested by the agent, as well as the "agentic loop" which enables multi-step reasoning.
+
+## Persistence ("statefulness")
+In Letta, all state is *persisted* by default. This means that each time the LLM is run, the state of the agent such as its memories, message history, and tools are all persisted to a DB backend.
+
+Because all state is persisted, you can always re-load agents, tools, sources, etc. at a later point in time.
+You can also load the same agent accross multiple machines or services, as long as they can can connect to the same DB backend.
+
+## Agent microservices ("agents-as-a-service")
+Letta follows the model of treating agents as individual services. That is, you interact with agents through a REST API:
+```
+POST /agents/{agent_id}/messages
+```
+Since agents are designed to be services, they can be *deployed* and connected to external applications.
+
+For example, you want to create a personalizated chatbot, you can create an agent per-user, where each agent has its own custom memory about the individual user.
+
+## Stateful vs stateless APIs
+`ChatCompletions` is the standard for interacting with LLMs as a service. Since it is a stateless API (no notion of sessions or identify accross requests, and no state management on the server-side), client-side applications must manage things like agent memory, user personalization, and message history, and translate this state back into the `ChatCompletions` API format. Letta's APIs are designed to be *stateful*, so that this state management is done on the server, not the client.
diff --git a/fern/pages/concepts/memgpt.mdx b/fern/pages/concepts/memgpt.mdx
new file mode 100644
index 00000000..e3285be4
--- /dev/null
+++ b/fern/pages/concepts/memgpt.mdx
@@ -0,0 +1,37 @@
+---
+title: MemGPT
+subtitle: Learn about the key ideas behind MemGPT
+slug: concepts/memgpt
+---
+
+
+
+Meet other developers and AI enthusiasts interested in building agents!
+
+
+ +
+
+**MemGPT** is the name of a [**research paper**](https://arxiv.org/abs/2310.08560) that popularized several of the key concepts behind the "LLM Operating System (OS)":
+1. **Memory management**: In MemGPT, an LLM OS moves data in and out of the context window of the LLM to manage its memory.
+2. **Memory hierarchy**: The "LLM OS" divides the LLM's memory (aka its "virtual context", similar to "[virtual memory](https://en.wikipedia.org/wiki/Virtual_memory)" in computer systems) into two parts: the in-context memory, and out-of-context memory.
+3. **Self-editing memory via tool calling**: In MemGPT, the "OS" that manages memory is itself an LLM. The LLM moves data in and out of the context window using designated memory-editing tools.
+4. **Multi-step reasoning using heartbeats**: MemGPT supports multi-step reasoning (allowing the agent to take multiple steps in sequence) via the concept of "heartbeats". Whenever the LLM outputs a tool call, it has to option to request a heartbeat by setting the keyword argument `request_heartbeat` to `true`. If the LLM requests a heartbeat, the LLM OS continues execution in a loop, allowing the LLM to "think" again.
+
+You can read more about the MemGPT memory hierarchy and memory management system in our [memory concepts guide](/advanced/memory_management).
+
+## MemGPT - the agent architecture
+
+**MemGPT** also refers to a particular **agent architecture** that was popularized by the paper and adopted widely by other LLM chatbots:
+1. **Chat-focused core memory**: The core memory of a MemGPT agent is split into two parts - the agent's own persona, and the user information. Because the MemGPT agent has self-editing memory, it can update its own personality over time, as well as update the user information as it learns new facts about the user.
+2. **Vector database archival memory**: By default, the archival memory connected to a MemGPT agent is backed by a vector database, such as [Chroma](https://www.trychroma.com/) or [pgvector](https://github.com/pgvector/pgvector). Because in MemGPT all connections to memory are driven by tools, it's simple to exchange archival memory to be powered by a more traditional database (you can even make archival memory a flatfile if you want!).
+
+## Creating MemGPT agents in the Letta framework
+
+Because **Letta** was created out of the original MemGPT open source project, it's extremely easy to make MemGPT agents inside of Letta (the default Letta agent architecture is a MemGPT agent).
+See our [agents overview](/agents/overview) for a tutorial on how to create MemGPT agents with Letta.
+
+**The Letta framework also allow you to make agent architectures beyond MemGPT** that differ significantly from the architecture proposed in the research paper - for example, agents with multiple logical threads (e.g. a "concious" and a "subconcious"), or agents with more advanced memory types (e.g. task memory).
+
+Additionally, **the Letta framework also allows you to expose your agents as *services*** (over REST APIs) - so you can use the Letta framework to power your AI applications.
diff --git a/fern/pages/concepts/memory.mdx b/fern/pages/concepts/memory.mdx
new file mode 100644
index 00000000..bcd3b120
--- /dev/null
+++ b/fern/pages/concepts/memory.mdx
@@ -0,0 +1,101 @@
+---
+title: Understanding memory management
+subtitle: Understanding the concept of LLM memory management introduced in MemGPT
+slug: concepts/memory-management
+---
+
+
+Letta uses the MemGPT memory management technique to control the context window of the LLM.
+
+The behavior of an agent is determine by two things: the underlying LLM model, and the context window that is passed to that model.
+Letta provides a framework for "programming" how the context is compiled at each reasoning step, a process which we refer to as memory management for agents.
+
+Unlike existing RAG-based frameworks for long-running memory, MemGPT provides a more flexible, powerful framework for memory management by enabling the agent to self-manage memory via tool calls.
+Essentially, the agent itself gets to decide what information to place into its context at any given time. We reserve a section of the context, which we call the in-context memory, which is agent as the ability to directly write to.
+In addition, the agent is given tools to access external storage (i.e. database tables) to enable a larger memory store.
+Combining tools to write to both its in-context and external memory, as well as tools to search external memory and place results into the LLM context, is what allows MemGPT agents to perform memory management.
+
+## In-context memory
+
+The in-context memory is a section of the LLM context window that is reserved to be editable by the agent.
+You can think of this like a system prompt, except the system prompt it editable (MemGPT also has an actual system prompt which is not editable by the agent).
+
+In MemGPT, the in-context memory is defined by extending the BaseMemory class. The memory class consists of:
+* A self.memory dictionary that maps labeled sections of memory (e.g. "human", "persona") to a MemoryModuleobject, which contains the data for that section of memory as well as the character limit (default: 2k)
+* A set of class functions which can be used to edit the data in each MemoryModulecontained in self.memory
+
+We'll show each of these components in the default ChatMemory class described below.
+
+## ChatMemory Memory
+By default, agents have a ChatMemory memory class, which is designed for a 1:1 chat between a human and agent. The ChatMemory class consists of:
+* A "human" and "persona" memory sections each with a 2k character limit
+* Memory editing functions: memory_insert, memory_replace, memory_rethink, and memory_finish_edits
+* Legacy functions (deprecated): core_memory_replace and core_memory_append
+
+We show the implementation of ChatMemory below:
+```python
+from memgpt.memory import BaseMemory
+
+class ChatMemory(BaseMemory):
+
+ def __init__(self, persona: str, human: str, limit: int = 2000):
+ self.memory = {
+ "persona": MemoryModule(name="persona", value=persona, limit=limit),
+ "human": MemoryModule(name="human", value=human, limit=limit),
+ }
+
+ def core_memory_append(self, name: str, content: str) -> Optional[str]:
+ """
+ Append to the contents of core memory.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value += "\n" + content
+ return None
+
+ def core_memory_replace(self, name: str, old_content: str, new_content: str) -> Optional[str]:
+ """
+ Replace the contents of core memory. To delete memories, use an empty string for new_content.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ old_content (str): String to replace. Must be an exact match.
+ new_content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value = self.memory[name].value.replace(old_content, new_content)
+ return None
+```
+
+To customize memory, you can implement extensions of the BaseMemory class that customize the memory dictionary and the memory editing functions.
+
+## External memory
+
+In-context memory is inherently limited in size, as all its state must be included in the context window.
+To allow additional memory in external storage, MemGPT by default stores two external tables: archival memory (for long running memories that do not fit into the context) and recall memory (for conversation history).
+
+### Archival memory
+Archival memory is a table in a vector DB that can be used to store long running memories of the agent, as well external data that the agent needs access too (referred to as a "Data Source"). The agent is by default provided with a read and write tool to archival memory:
+* archival_memory_search
+* archival_memory_insert
+
+### Recall memory
+Recall memory is a table which MemGPT logs all the conversational history with an agent. The agent is by default provided with date search and text search tools to retrieve conversational history.
+* conversation_search
+* conversation_search_date
+
+(Note: a tool to insert data is not provided since chat histories are automatically inserted.)
+
+## Orchestrating Tools for Memory Management
+
+We provide the agent with a list of default tools for interacting with both in-context and external memory.
+The way these tools are used to manage memory is controlled by the tool descriptions as well as the MemGPT system prompt.
+None of these tools are required for MemGPT to work, so you can remove or override tools to customize memory.
+We encourage developers to extend the BaseMemory class to customize the in-context memory management for their own applications.
diff --git a/fern/pages/cookbooks.mdx b/fern/pages/cookbooks.mdx
new file mode 100644
index 00000000..c5f24d91
--- /dev/null
+++ b/fern/pages/cookbooks.mdx
@@ -0,0 +1,141 @@
+---
+title: Letta Cookbooks
+# layout: page
+# hide-feedback: true
+# no-image-zoom: true
+slug: cookbooks
+---
+
+
+
+
+
+
+**MemGPT** is the name of a [**research paper**](https://arxiv.org/abs/2310.08560) that popularized several of the key concepts behind the "LLM Operating System (OS)":
+1. **Memory management**: In MemGPT, an LLM OS moves data in and out of the context window of the LLM to manage its memory.
+2. **Memory hierarchy**: The "LLM OS" divides the LLM's memory (aka its "virtual context", similar to "[virtual memory](https://en.wikipedia.org/wiki/Virtual_memory)" in computer systems) into two parts: the in-context memory, and out-of-context memory.
+3. **Self-editing memory via tool calling**: In MemGPT, the "OS" that manages memory is itself an LLM. The LLM moves data in and out of the context window using designated memory-editing tools.
+4. **Multi-step reasoning using heartbeats**: MemGPT supports multi-step reasoning (allowing the agent to take multiple steps in sequence) via the concept of "heartbeats". Whenever the LLM outputs a tool call, it has to option to request a heartbeat by setting the keyword argument `request_heartbeat` to `true`. If the LLM requests a heartbeat, the LLM OS continues execution in a loop, allowing the LLM to "think" again.
+
+You can read more about the MemGPT memory hierarchy and memory management system in our [memory concepts guide](/advanced/memory_management).
+
+## MemGPT - the agent architecture
+
+**MemGPT** also refers to a particular **agent architecture** that was popularized by the paper and adopted widely by other LLM chatbots:
+1. **Chat-focused core memory**: The core memory of a MemGPT agent is split into two parts - the agent's own persona, and the user information. Because the MemGPT agent has self-editing memory, it can update its own personality over time, as well as update the user information as it learns new facts about the user.
+2. **Vector database archival memory**: By default, the archival memory connected to a MemGPT agent is backed by a vector database, such as [Chroma](https://www.trychroma.com/) or [pgvector](https://github.com/pgvector/pgvector). Because in MemGPT all connections to memory are driven by tools, it's simple to exchange archival memory to be powered by a more traditional database (you can even make archival memory a flatfile if you want!).
+
+## Creating MemGPT agents in the Letta framework
+
+Because **Letta** was created out of the original MemGPT open source project, it's extremely easy to make MemGPT agents inside of Letta (the default Letta agent architecture is a MemGPT agent).
+See our [agents overview](/agents/overview) for a tutorial on how to create MemGPT agents with Letta.
+
+**The Letta framework also allow you to make agent architectures beyond MemGPT** that differ significantly from the architecture proposed in the research paper - for example, agents with multiple logical threads (e.g. a "concious" and a "subconcious"), or agents with more advanced memory types (e.g. task memory).
+
+Additionally, **the Letta framework also allows you to expose your agents as *services*** (over REST APIs) - so you can use the Letta framework to power your AI applications.
diff --git a/fern/pages/concepts/memory.mdx b/fern/pages/concepts/memory.mdx
new file mode 100644
index 00000000..bcd3b120
--- /dev/null
+++ b/fern/pages/concepts/memory.mdx
@@ -0,0 +1,101 @@
+---
+title: Understanding memory management
+subtitle: Understanding the concept of LLM memory management introduced in MemGPT
+slug: concepts/memory-management
+---
+
+
+Letta uses the MemGPT memory management technique to control the context window of the LLM.
+
+The behavior of an agent is determine by two things: the underlying LLM model, and the context window that is passed to that model.
+Letta provides a framework for "programming" how the context is compiled at each reasoning step, a process which we refer to as memory management for agents.
+
+Unlike existing RAG-based frameworks for long-running memory, MemGPT provides a more flexible, powerful framework for memory management by enabling the agent to self-manage memory via tool calls.
+Essentially, the agent itself gets to decide what information to place into its context at any given time. We reserve a section of the context, which we call the in-context memory, which is agent as the ability to directly write to.
+In addition, the agent is given tools to access external storage (i.e. database tables) to enable a larger memory store.
+Combining tools to write to both its in-context and external memory, as well as tools to search external memory and place results into the LLM context, is what allows MemGPT agents to perform memory management.
+
+## In-context memory
+
+The in-context memory is a section of the LLM context window that is reserved to be editable by the agent.
+You can think of this like a system prompt, except the system prompt it editable (MemGPT also has an actual system prompt which is not editable by the agent).
+
+In MemGPT, the in-context memory is defined by extending the BaseMemory class. The memory class consists of:
+* A self.memory dictionary that maps labeled sections of memory (e.g. "human", "persona") to a MemoryModuleobject, which contains the data for that section of memory as well as the character limit (default: 2k)
+* A set of class functions which can be used to edit the data in each MemoryModulecontained in self.memory
+
+We'll show each of these components in the default ChatMemory class described below.
+
+## ChatMemory Memory
+By default, agents have a ChatMemory memory class, which is designed for a 1:1 chat between a human and agent. The ChatMemory class consists of:
+* A "human" and "persona" memory sections each with a 2k character limit
+* Memory editing functions: memory_insert, memory_replace, memory_rethink, and memory_finish_edits
+* Legacy functions (deprecated): core_memory_replace and core_memory_append
+
+We show the implementation of ChatMemory below:
+```python
+from memgpt.memory import BaseMemory
+
+class ChatMemory(BaseMemory):
+
+ def __init__(self, persona: str, human: str, limit: int = 2000):
+ self.memory = {
+ "persona": MemoryModule(name="persona", value=persona, limit=limit),
+ "human": MemoryModule(name="human", value=human, limit=limit),
+ }
+
+ def core_memory_append(self, name: str, content: str) -> Optional[str]:
+ """
+ Append to the contents of core memory.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value += "\n" + content
+ return None
+
+ def core_memory_replace(self, name: str, old_content: str, new_content: str) -> Optional[str]:
+ """
+ Replace the contents of core memory. To delete memories, use an empty string for new_content.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ old_content (str): String to replace. Must be an exact match.
+ new_content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value = self.memory[name].value.replace(old_content, new_content)
+ return None
+```
+
+To customize memory, you can implement extensions of the BaseMemory class that customize the memory dictionary and the memory editing functions.
+
+## External memory
+
+In-context memory is inherently limited in size, as all its state must be included in the context window.
+To allow additional memory in external storage, MemGPT by default stores two external tables: archival memory (for long running memories that do not fit into the context) and recall memory (for conversation history).
+
+### Archival memory
+Archival memory is a table in a vector DB that can be used to store long running memories of the agent, as well external data that the agent needs access too (referred to as a "Data Source"). The agent is by default provided with a read and write tool to archival memory:
+* archival_memory_search
+* archival_memory_insert
+
+### Recall memory
+Recall memory is a table which MemGPT logs all the conversational history with an agent. The agent is by default provided with date search and text search tools to retrieve conversational history.
+* conversation_search
+* conversation_search_date
+
+(Note: a tool to insert data is not provided since chat histories are automatically inserted.)
+
+## Orchestrating Tools for Memory Management
+
+We provide the agent with a list of default tools for interacting with both in-context and external memory.
+The way these tools are used to manage memory is controlled by the tool descriptions as well as the MemGPT system prompt.
+None of these tools are required for MemGPT to work, so you can remove or override tools to customize memory.
+We encourage developers to extend the BaseMemory class to customize the in-context memory management for their own applications.
diff --git a/fern/pages/cookbooks.mdx b/fern/pages/cookbooks.mdx
new file mode 100644
index 00000000..c5f24d91
--- /dev/null
+++ b/fern/pages/cookbooks.mdx
@@ -0,0 +1,141 @@
+---
+title: Letta Cookbooks
+# layout: page
+# hide-feedback: true
+# no-image-zoom: true
+slug: cookbooks
+---
+
+
+
+
+
+
+
+A chatbot application (using Next.js) where each user can chat with their own agents with long-term memory.
+
+
+Use Letta to create a Discord bot that can chat with users and perform tasks.
+
+
+
+
+## Basic SDK Examples
+
+
+A basic example script using the Letta TypeScript SDK
+
+
+A basic example script using the Letta Python SDK
+
+
+
+## Multi-Agent Examples
+
+
+Connect two independent agents together to allow them to chat with each other (as well as with a user).
+
+
+Create a multi-agent system where a supervisor (aka orchestrator) agent directs multiple worker agents.
+
+
+Create a multi-agent system where a supervisor (aka orchestrator) agent directs multiple worker agents.
+
+
+
+## Advanced Integrations
+
+
+Chat with your Letta agents using voice mode using our native voice integration.
+
+
+
+
diff --git a/fern/pages/cookbooks_simple.mdx b/fern/pages/cookbooks_simple.mdx
new file mode 100644
index 00000000..f457fc49
--- /dev/null
+++ b/fern/pages/cookbooks_simple.mdx
@@ -0,0 +1,98 @@
+---
+title: Letta Cookbooks
+# layout: page
+# hide-feedback: true
+# no-image-zoom: true
+slug: cookbooks
+---
+
+Explore what you can build with stateful agents.
+Explore what you can build with stateful agents.
+If you're just starting out, check out our
+Further documentation on the Letta API can be found in our
+
+## Ready-to-go Applications
++If you're just starting out, check out our
+Further documentation on the Letta API can be found in our
+Open source projects that can be used as a starting point for your own application.
+
+
+
+Read some example code to learn how to use the Letta SDKs.
+
+
+
+Letta makes it easy to build powerful multi-agent systems with stateful agents.
+
+
++If you're just starting out, check out our
+Further documentation on the Letta API can be found in our
 +
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+## Accessing the deployment via the ADE
+
+Now that the Railway deployment is active, all we need to do to access it via the ADE is add it to as a new remote Letta server.
+The default password set in the template is `password`, which can be changed at the deployment stage or afterwards in the 'variables' page on the Railway deployment.
+
+Click "Add remote server", then enter the details from Railway (use the static IP address shown in the logs, and use the password set via the environment variables):
+
+
+
+
+## Accessing the deployment via the Letta API
+
+Accessing the deployment via the [Letta API](https://docs.letta.com/api-reference) is simple, we just need to swap the base URL of the endpoint with the IP address from the Railway deployment.
+
+For example if the Railway IP address is `https://MYSERVER.up.railway.app` and the password is `banana`, to create an agent on the deployment, we can use the following shell command:
+```sh
+curl --request POST \
+ --url https://MYSERVER.up.railway.app/v1/agents/ \
+ --header 'X-BARE-PASSWORD: password banana' \
+ --header 'Content-Type: application/json' \
+ --data '{
+ "memory_blocks": [
+ {
+ "label": "human",
+ "value": "The human'\''s name is Bob the Builder"
+ },
+ {
+ "label": "persona",
+ "value": "My name is Sam, the all-knowing sentient AI."
+ }
+ ],
+ "llm_config": {
+ "model": "gpt-4o-mini",
+ "model_endpoint_type": "openai",
+ "model_endpoint": "https://api.openai.com/v1",
+ "context_window": 16000
+ },
+ "embedding_config": {
+ "embedding_endpoint_type": "openai",
+ "embedding_endpoint": "https://api.openai.com/v1",
+ "embedding_model": "text-embedding-3-small",
+ "embedding_dim": 8191
+ },
+ "tools": [
+ "send_message",
+ "core_memory_append",
+ "core_memory_replace",
+ "archival_memory_search",
+ "archival_memory_insert",
+ "conversation_search"
+ ]
+}'
+```
+
+This will create an agent with two memory blocks, configured to use `gpt-4o-mini` as the LLM model, and `text-embedding-3-small` as the embedding model. We also include the base Letta tools in the request.
+
+If the Letta server is not password protected, we can omit the `X-BARE-PASSWORD` header.
+
+
+
+
+## Accessing the deployment via the ADE
+
+Now that the Railway deployment is active, all we need to do to access it via the ADE is add it to as a new remote Letta server.
+The default password set in the template is `password`, which can be changed at the deployment stage or afterwards in the 'variables' page on the Railway deployment.
+
+Click "Add remote server", then enter the details from Railway (use the static IP address shown in the logs, and use the password set via the environment variables):
+
+
+
+
+## Accessing the deployment via the Letta API
+
+Accessing the deployment via the [Letta API](https://docs.letta.com/api-reference) is simple, we just need to swap the base URL of the endpoint with the IP address from the Railway deployment.
+
+For example if the Railway IP address is `https://MYSERVER.up.railway.app` and the password is `banana`, to create an agent on the deployment, we can use the following shell command:
+```sh
+curl --request POST \
+ --url https://MYSERVER.up.railway.app/v1/agents/ \
+ --header 'X-BARE-PASSWORD: password banana' \
+ --header 'Content-Type: application/json' \
+ --data '{
+ "memory_blocks": [
+ {
+ "label": "human",
+ "value": "The human'\''s name is Bob the Builder"
+ },
+ {
+ "label": "persona",
+ "value": "My name is Sam, the all-knowing sentient AI."
+ }
+ ],
+ "llm_config": {
+ "model": "gpt-4o-mini",
+ "model_endpoint_type": "openai",
+ "model_endpoint": "https://api.openai.com/v1",
+ "context_window": 16000
+ },
+ "embedding_config": {
+ "embedding_endpoint_type": "openai",
+ "embedding_endpoint": "https://api.openai.com/v1",
+ "embedding_model": "text-embedding-3-small",
+ "embedding_dim": 8191
+ },
+ "tools": [
+ "send_message",
+ "core_memory_append",
+ "core_memory_replace",
+ "archival_memory_search",
+ "archival_memory_insert",
+ "conversation_search"
+ ]
+}'
+```
+
+This will create an agent with two memory blocks, configured to use `gpt-4o-mini` as the LLM model, and `text-embedding-3-small` as the embedding model. We also include the base Letta tools in the request.
+
+If the Letta server is not password protected, we can omit the `X-BARE-PASSWORD` header.
+
+ +
+## Connecting to Grafana
+We recommend connecting ClickHouse to Grafana to query and view traces. Grafana can be run [locally](https://grafana.com/oss/grafana/), or via [Grafana Cloud](https://grafana.com/grafana/).
+
+
+# Other Integrations
+
+Letta also supports other exporters when running in a containerized environment. To request support for another exporter, please open an issue on [GitHub](https://github.com/letta-ai/letta/issues/new/choose).
+
+## Configuring Signoz
+
+You can configure Signoz by passing the required enviornment variables:
+```sh
+docker run \
+ -v ~/.letta/.persist/pgdata:/var/lib/postgresql/data \
+ -p 8283:8283 \
+ ...
+ -e SIGNOZ_ENDPOINT=${SIGNOZ_ENDPOINT} \
+ -e SIGNOZ_INGESTION_KEY=${SIGNOZ_INGESTION_KEY} \
+ -e LETTA_OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317 \
+ letta/letta:latest
+```
diff --git a/fern/pages/desktop/install.mdx b/fern/pages/desktop/install.mdx
new file mode 100644
index 00000000..2b20e355
--- /dev/null
+++ b/fern/pages/desktop/install.mdx
@@ -0,0 +1,185 @@
+---
+title: Installing Letta Desktop
+subtitle: Install Letta Desktop on your MacOS, Windows, or Linux machine
+slug: guides/ade/desktop
+---
+
+
+
+
+**Letta Desktop** allows you to run the ADE (Agent Development Environment) as a local application.
+Letta Desktop also bundles a built-in Letta server, so can run Letta Desktop standalone, or you can connect it to a self-hosted Letta server.
+
+## Download Letta Desktop
+
+
+
+You can also edit the environment variable file directly, located at `~/.letta/env`.
+
+For this quickstart demo, we'll add an OpenAI API key (once we enter our key and **click confirm**, the Letta server will automatically restart):
+
+
+
+## Configuration Modes
+
+Letta Desktop can run in two primary modes, which can be configured from the settings menu in the app, or by manually editing the `~/.letta/desktop_config.json` file.
+
+
+
+## Connecting to Grafana
+We recommend connecting ClickHouse to Grafana to query and view traces. Grafana can be run [locally](https://grafana.com/oss/grafana/), or via [Grafana Cloud](https://grafana.com/grafana/).
+
+
+# Other Integrations
+
+Letta also supports other exporters when running in a containerized environment. To request support for another exporter, please open an issue on [GitHub](https://github.com/letta-ai/letta/issues/new/choose).
+
+## Configuring Signoz
+
+You can configure Signoz by passing the required enviornment variables:
+```sh
+docker run \
+ -v ~/.letta/.persist/pgdata:/var/lib/postgresql/data \
+ -p 8283:8283 \
+ ...
+ -e SIGNOZ_ENDPOINT=${SIGNOZ_ENDPOINT} \
+ -e SIGNOZ_INGESTION_KEY=${SIGNOZ_INGESTION_KEY} \
+ -e LETTA_OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317 \
+ letta/letta:latest
+```
diff --git a/fern/pages/desktop/install.mdx b/fern/pages/desktop/install.mdx
new file mode 100644
index 00000000..2b20e355
--- /dev/null
+++ b/fern/pages/desktop/install.mdx
@@ -0,0 +1,185 @@
+---
+title: Installing Letta Desktop
+subtitle: Install Letta Desktop on your MacOS, Windows, or Linux machine
+slug: guides/ade/desktop
+---
+
+
+
+
+**Letta Desktop** allows you to run the ADE (Agent Development Environment) as a local application.
+Letta Desktop also bundles a built-in Letta server, so can run Letta Desktop standalone, or you can connect it to a self-hosted Letta server.
+
+## Download Letta Desktop
+
+
+
+You can also edit the environment variable file directly, located at `~/.letta/env`.
+
+For this quickstart demo, we'll add an OpenAI API key (once we enter our key and **click confirm**, the Letta server will automatically restart):
+
+
+
+## Configuration Modes
+
+Letta Desktop can run in two primary modes, which can be configured from the settings menu in the app, or by manually editing the `~/.letta/desktop_config.json` file.
+
++For additional support please visit our [Discord server](https://discord.gg/letta) and post in the support channel. +
+
+
+Unlike simple chatbot interfaces, the ADE gives you complete control over your agent's state across its entire lifecycle:
+- Create and customize agents without writing code
+- Visualize your agent's memory and context window in real-time
+- Add and test custom tools in a sandboxed environment
+- Monitor agent behavior and performance
+
+The ADE provides a graphical interface to agents running in your Letta server.
+These same agents can be accessed via the [Letta APIs](/api-reference/overview), allowing you to integrate them into your applications.
+
+## Read our ADE guide
+Learn more about the ADE in our ADE guide:
+- [Explore the ADEs components in detail](/guides/ade/overview)
+- [Connecting the ADE to local and remote deployments](/guides/ade/setup)
+- [Read our ADE FAQs](/faq#agent-development-environment-ade)
+
+If you have additional questions, feedback, or feature requests, reach out on [Discord](https://discord.gg/letta)!
diff --git a/fern/pages/getting-started/faq.mdx b/fern/pages/getting-started/faq.mdx
new file mode 100644
index 00000000..7e4b7276
--- /dev/null
+++ b/fern/pages/getting-started/faq.mdx
@@ -0,0 +1,89 @@
+---
+title: Letta FAQs
+slug: faq
+---
+
+Can't find the answer to your question?
+Feel free to reach out to the Letta development team and community on [Discord](https://discord.gg/letta) or [GitHub](https://github.com/letta-ai/letta/issues)!
+
+## Letta Platform
++If you are deploying Letta via Docker and want to use the ADE, you can connect the web ADE to your Docker deployment. +To connect the ADE to your deployed Letta server, simply run your Letta server (if running locally, make sure you can access `localhost:8283`) and go to [https://app.letta.com](https://app.letta.com). +
 +
+ +
+## Build agents with intelligent memory, not limited context
+
+Letta's advanced context management system - built by the [researchers behind MemGPT](https://www.letta.com/research) - transforms how agents remember and learn. Unlike basic agents that forget when their context window fills up, Letta agents maintain memories across sessions and continuously improve, even while they [sleep](/guides/agents/sleep-time-agents)
+
+
+## Run agents as services, not libraries
+
+**Letta is fundamentally different from other agent frameworks.** While most frameworks are *libraries* that wrap model APIs, Letta provides a dedicated *service* where agents live and operate autonomously. Agents continue to exist and maintain state even when your application isn't running, with computation happening on the server and all memory, context, and tool connections handled by the Letta server.
+
+
+
+## Build agents with intelligent memory, not limited context
+
+Letta's advanced context management system - built by the [researchers behind MemGPT](https://www.letta.com/research) - transforms how agents remember and learn. Unlike basic agents that forget when their context window fills up, Letta agents maintain memories across sessions and continuously improve, even while they [sleep](/guides/agents/sleep-time-agents)
+
+
+## Run agents as services, not libraries
+
+**Letta is fundamentally different from other agent frameworks.** While most frameworks are *libraries* that wrap model APIs, Letta provides a dedicated *service* where agents live and operate autonomously. Agents continue to exist and maintain state even when your application isn't running, with computation happening on the server and all memory, context, and tool connections handled by the Letta server.
+
+ +
+ +
+## Everything you need for production agents
+
+Letta provides a complete suite of capabilities for building and deploying advanced AI agents:
+
+*
+
+
+
+ [Read our ADE setup guide →](/guides/ade/setup)
+
+
+## Projects
+
+In Letta Cloud, your workspace is organized into projects.
+When you create agents directly (instead of via [templates](/guides/templates/overview)), your agents will get placed in the "Default Project".
+
+## Creating an agent with the Letta API
+Let's create an agent via the Letta API, which we can then view in the ADE (you can also use the ADE to create agents).
+
+To create an agent we'll send a POST request to the Letta server ([API docs](/api-reference/agents/create)).
+In this example, we'll use `gpt-4o-mini` as the base LLM model, and `text-embedding-3-small` as the embedding model (this requires having configured both `OPENAI_API_KEY` on our Letta server).
+
+We'll also artificially set the context window limit to 16k, instead of the 128k default for `gpt-4o-mini` (this can improve stability and performance):
+
+
+## Everything you need for production agents
+
+Letta provides a complete suite of capabilities for building and deploying advanced AI agents:
+
+*
+
+
+
+ [Read our ADE setup guide →](/guides/ade/setup)
+
+
+## Projects
+
+In Letta Cloud, your workspace is organized into projects.
+When you create agents directly (instead of via [templates](/guides/templates/overview)), your agents will get placed in the "Default Project".
+
+## Creating an agent with the Letta API
+Let's create an agent via the Letta API, which we can then view in the ADE (you can also use the ADE to create agents).
+
+To create an agent we'll send a POST request to the Letta server ([API docs](/api-reference/agents/create)).
+In this example, we'll use `gpt-4o-mini` as the base LLM model, and `text-embedding-3-small` as the embedding model (this requires having configured both `OPENAI_API_KEY` on our Letta server).
+
+We'll also artificially set the context window limit to 16k, instead of the 128k default for `gpt-4o-mini` (this can improve stability and performance):
+ +
+## Send a message to the agent with the Letta API
+
+
+## Next steps
+
+Congratulations! 🎉 You just created and messaged your first stateful agent with Letta, using both the Letta ADE, API, and Python/Typescript SDKs.
+
+Now that you've succesfully created a basic agent with Letta, you're ready to start building more complex agents and AI applications.
+
+
+
+## Send a message to the agent with the Letta API
+
+
+## Next steps
+
+Congratulations! 🎉 You just created and messaged your first stateful agent with Letta, using both the Letta ADE, API, and Python/Typescript SDKs.
+
+Now that you've succesfully created a basic agent with Letta, you're ready to start building more complex agents and AI applications.
+
++For bug reports and feature requests, please [join our Discord](https://discord.gg/letta). +
+
+If Desktop is not available for your platform you can still use [Letta via Docker](/quickstart/docker) or [pip](/guides/server/pip).
+
+## Run Letta Desktop
+**Letta agents** live inside a **Letta server**, which persists them to a database.
+You can interact with the Letta agents inside your Letta server with the [ADE](/agent-development-environment) (a visual interface), and connect your agents to external application via the [REST API](https://docs.letta.com/api-reference) and Python & TypeScript SDKs.
+
+Letta Desktop bundles together the Letta server and the Agent Development Environment (ADE) into a single application.
+
+ +
+When you launch Letta Desktop, you'll be prompted to wait while the Letta server starts up.
+You can monitor the server startup process by opening the server logs (clicking the
+
+When you launch Letta Desktop, you'll be prompted to wait while the Letta server starts up.
+You can monitor the server startup process by opening the server logs (clicking the  +
+## Next steps
+
+Congratulations! 🎉 You just created and messaged your first stateful agent with Letta, using both the Letta ADE, API, and Python/Typescript SDKs.
+
+Now that you've succesfully created a basic agent with Letta, you're ready to start building more complex agents and AI applications.
+
+
+
+
+Large Language Models have given us powerful building blocks for intelligent systems.
+By connecting these models to external tools, we can create AI agents that take actions and affect the real world.
+
+Most LLM agents today are held back by a fundamental limitation: while LLMs provide the intelligence, they are inherently stateless - processing each input without memory of past interactions.
+Simply accumulating conversation history leads to agents that lose track of important information or need their memory regularly cleared to continue functioning.
+
+Building truly intelligent agents requires sophisticated context management - the missing piece that transforms stateless LLMs into agents that can intelligently process vast knowledge bases and continuously learn from their experiences.
+
+## Stateful Agents
+
+When an LLM agent interacts with the world, it accumulates state - learned behaviors, facts about its environment, and memories of past interactions.
+A stateful agent is one that can effectively manage this growing knowledge, maintaining consistent behavior while incorporating new experiences.
+
+```mermaid
+graph TD
+ subgraph basic["Basic Agent"]
+ direction LR
+ c1["Context Window:
+ Growing History → Context Limit!"] --> llm1[LLM]
+ llm1 --> action1[/"Agent Action"/]
+ action1 -->|"Append to History"| c1
+ end
+
+ basic --> stateful
+
+ subgraph stateful["Stateful Agent"]
+ direction LR
+ db[(Persistent State
+ All Memory & History)] --> cms["Context Management
+ System"]
+ cms -->|"Compile Context"| cw["Context Window
+ ---------------
+ Relevant State"]
+ cw --> llm2[LLM]
+ llm2 --> action2[/"Agent Action"/]
+ action2 -->|"Persist New State"| db
+ end
+
+ class c1,cw context
+ class action1,action2 action
+```
+
+Stateful agents use intelligent context management to organize and prioritize information, enabling them to process large amounts of data while maintaining focus on what's relevant.
+This is a fundamental shift from traditional approaches that simply accumulate information until the agent becomes overwhelmed.
+
+Letta provides the foundation for building stateful agents through its context management system.
+By handling the complexity of state management, Letta lets you (the developer) focus on building agents that can truly learn and evolve through their interactions with the world.
diff --git a/fern/pages/getting-started/troubleshooting_ade.mdx b/fern/pages/getting-started/troubleshooting_ade.mdx
new file mode 100644
index 00000000..e69de29b
diff --git a/fern/pages/getting-started/troubleshooting_desktop.mdx b/fern/pages/getting-started/troubleshooting_desktop.mdx
new file mode 100644
index 00000000..e69de29b
diff --git a/fern/pages/index.mdx b/fern/pages/index.mdx
new file mode 100644
index 00000000..98294a16
--- /dev/null
+++ b/fern/pages/index.mdx
@@ -0,0 +1,97 @@
+---
+title: Home
+layout: custom
+hide-feedback: true
+no-image-zoom: true
+slug: /
+---
+
+
+
+
+
+## Next steps
+
+Congratulations! 🎉 You just created and messaged your first stateful agent with Letta, using both the Letta ADE, API, and Python/Typescript SDKs.
+
+Now that you've succesfully created a basic agent with Letta, you're ready to start building more complex agents and AI applications.
+
+
+
+
+Large Language Models have given us powerful building blocks for intelligent systems.
+By connecting these models to external tools, we can create AI agents that take actions and affect the real world.
+
+Most LLM agents today are held back by a fundamental limitation: while LLMs provide the intelligence, they are inherently stateless - processing each input without memory of past interactions.
+Simply accumulating conversation history leads to agents that lose track of important information or need their memory regularly cleared to continue functioning.
+
+Building truly intelligent agents requires sophisticated context management - the missing piece that transforms stateless LLMs into agents that can intelligently process vast knowledge bases and continuously learn from their experiences.
+
+## Stateful Agents
+
+When an LLM agent interacts with the world, it accumulates state - learned behaviors, facts about its environment, and memories of past interactions.
+A stateful agent is one that can effectively manage this growing knowledge, maintaining consistent behavior while incorporating new experiences.
+
+```mermaid
+graph TD
+ subgraph basic["Basic Agent"]
+ direction LR
+ c1["Context Window:
+ Growing History → Context Limit!"] --> llm1[LLM]
+ llm1 --> action1[/"Agent Action"/]
+ action1 -->|"Append to History"| c1
+ end
+
+ basic --> stateful
+
+ subgraph stateful["Stateful Agent"]
+ direction LR
+ db[(Persistent State
+ All Memory & History)] --> cms["Context Management
+ System"]
+ cms -->|"Compile Context"| cw["Context Window
+ ---------------
+ Relevant State"]
+ cw --> llm2[LLM]
+ llm2 --> action2[/"Agent Action"/]
+ action2 -->|"Persist New State"| db
+ end
+
+ class c1,cw context
+ class action1,action2 action
+```
+
+Stateful agents use intelligent context management to organize and prioritize information, enabling them to process large amounts of data while maintaining focus on what's relevant.
+This is a fundamental shift from traditional approaches that simply accumulate information until the agent becomes overwhelmed.
+
+Letta provides the foundation for building stateful agents through its context management system.
+By handling the complexity of state management, Letta lets you (the developer) focus on building agents that can truly learn and evolve through their interactions with the world.
diff --git a/fern/pages/getting-started/troubleshooting_ade.mdx b/fern/pages/getting-started/troubleshooting_ade.mdx
new file mode 100644
index 00000000..e69de29b
diff --git a/fern/pages/getting-started/troubleshooting_desktop.mdx b/fern/pages/getting-started/troubleshooting_desktop.mdx
new file mode 100644
index 00000000..e69de29b
diff --git a/fern/pages/index.mdx b/fern/pages/index.mdx
new file mode 100644
index 00000000..98294a16
--- /dev/null
+++ b/fern/pages/index.mdx
@@ -0,0 +1,97 @@
+---
+title: Home
+layout: custom
+hide-feedback: true
+no-image-zoom: true
+slug: /
+---
+
+
+
+
+
diff --git a/fern/pages/install.mdx b/fern/pages/install.mdx
new file mode 100644
index 00000000..4636950e
--- /dev/null
+++ b/fern/pages/install.mdx
@@ -0,0 +1,253 @@
+---
+title: Home
+layout: custom
+hide-feedback: true
+no-image-zoom: true
+slug: /install
+---
+
+
+
+
+
+ {/* Main Content */}
+
+
+
+
+
+  +
+  +
+
+
+
+ Build with Letta
++ Learn how to build and deploy stateful agents +
+ +
+
+
+ Create your first stateful agent in a few minutes
+
+
+ Learn how to use the Agent Development Environment (ADE)
+
+
+ Integrate Letta into your application with a few lines of code
+
+
+ Connect Letta agents to tool libraries via Model Context Protocol (MCP)
+
+
+ Learn how to build with Letta using tutorials and pre-made apps
+
+
+ Take our free DeepLearning.AI course on agent memory
+
+
+
+
+
+
+
+{/* Main Content */}
+
+
+
+
+
+
+
+
+ Letta Desktop is currently in **alpha**. View known issues and FAQ [here](/guides/desktop/troubleshooting).
+ For bug reports and feature requests, contact us on [Discord](https://discord.gg/letta). +
+
+ Letta Desktop
++ AI agents that learn, completely local. +
+The easiest way to build stateful agents on your own computer.
+Letta Desktop combines the Letta server and ADE into a single application.
+
+
+
+
+
+
+ + For bug reports and feature requests, contact us on [Discord](https://discord.gg/letta). +
+
+
+
+
+
+
+
diff --git a/fern/pages/introduction.mdx b/fern/pages/introduction.mdx
new file mode 100644
index 00000000..dc222f6f
--- /dev/null
+++ b/fern/pages/introduction.mdx
@@ -0,0 +1,100 @@
+---
+title: Welcome to Letta
+subtitle: Letta is an AI platform for building stateful LLM applications.
+slug: introduction
+---
+
+
++Letta software is provided under our [Privacy Policy](https://letta.com/privacy-policy) and [Terms of Service](https://letta.com/terms-of-service). +
+ +
+
+## Who is Letta for?
+
+Letta is for developers building stateful LLM applications that require advanced memory, such as:
+* **personalized chatbots** that require long-term memory and personas that should be updated (self-edited) over time (e.g. companions)
+* **agents connected to external data sources**, e.g. private enterprise deployments of ChatGPT-like applications (connected to your company's data), or a medical assistant connected to a patient's medical records
+* **agents connected to custom tools**, e.g. a chatbot that can answer questions about the latest news by searching the web
+* **automated AI workflows**, e.g. an agent that monitors your email inbox and sends you text alerts for urgent emails and a daily email summary
+
+... and countless other use cases!
+
+### [Letta ADE](https://app.letta.com) (Agent Development Environment)
+
+
+
+
+
+
+
+
+## Who is Letta for?
+
+Letta is for developers building stateful LLM applications that require advanced memory, such as:
+* **personalized chatbots** that require long-term memory and personas that should be updated (self-edited) over time (e.g. companions)
+* **agents connected to external data sources**, e.g. private enterprise deployments of ChatGPT-like applications (connected to your company's data), or a medical assistant connected to a patient's medical records
+* **agents connected to custom tools**, e.g. a chatbot that can answer questions about the latest news by searching the web
+* **automated AI workflows**, e.g. an agent that monitors your email inbox and sends you text alerts for urgent emails and a daily email summary
+
+... and countless other use cases!
+
+### [Letta ADE](https://app.letta.com) (Agent Development Environment)
+
+
+
+
+
+
+
+
+
+| Model | +Overall Score | +Core Memory | +Archival Memory | +
|---|
+
+
+
+| Model | +Core Read | +Core Write | +Archival Read | +
|---|
+
+
+
+| Model | +Overall Score | +Cost | +
|---|
+
+
+
+| Model | +Overall Score | +Cost | +
|---|
+[Model recommendations →](#main-results-and-recommendations) + +
+
+
+
+
+
+
+
+
+
+ | Model | +Overall Score | +Cost | +
|---|
 +
+
+**MemGPT** is the name of a [**research paper**](https://arxiv.org/abs/2310.08560) that popularized several of the key concepts behind the "LLM Operating System (OS)":
+1. **Memory management**: In MemGPT, an LLM OS moves data in and out of the context window of the LLM to manage its memory.
+2. **Memory hierarchy**: The "LLM OS" divides the LLM's memory (aka its "virtual context", similar to "[virtual memory](https://en.wikipedia.org/wiki/Virtual_memory)" in computer systems) into two parts: the in-context memory, and out-of-context memory.
+3. **Self-editing memory via tool calling**: In MemGPT, the "OS" that manages memory is itself an LLM. The LLM moves data in and out of the context window using designated memory-editing tools.
+4. **Multi-step reasoning using heartbeats**: MemGPT supports multi-step reasoning (allowing the agent to take multiple steps in sequence) via the concept of "heartbeats". Whenever the LLM outputs a tool call, it has to option to request a heartbeat by setting the keyword argument `request_heartbeat` to `true`. If the LLM requests a heartbeat, the LLM OS continues execution in a loop, allowing the LLM to "think" again.
+
+You can read more about the MemGPT memory hierarchy and memory management system in our [memory concepts guide](/advanced/memory_management).
+
+## MemGPT - the agent architecture
+
+**MemGPT** also refers to a particular **agent architecture** that was popularized by the paper and adopted widely by other LLM chatbots:
+1. **Chat-focused core memory**: The core memory of a MemGPT agent is split into two parts - the agent's own persona, and the user information. Because the MemGPT agent has self-editing memory, it can update its own personality over time, as well as update the user information as it learns new facts about the user.
+2. **Vector database archival memory**: By default, the archival memory connected to a MemGPT agent is backed by a vector database, such as [Chroma](https://www.trychroma.com/) or [pgvector](https://github.com/pgvector/pgvector). Because in MemGPT all connections to memory are driven by tools, it's simple to exchange archival memory to be powered by a more traditional database (you can even make archival memory a flatfile if you want!).
+
+## Creating MemGPT agents in the Letta framework
+
+Because **Letta** was created out of the original MemGPT open source project, it's extremely easy to make MemGPT agents inside of Letta (the default Letta agent architecture is a MemGPT agent).
+See our [agents overview](/guides/agents/overview) for a tutorial on how to create MemGPT agents with Letta.
+
+**The Letta framework also allow you to make agent architectures beyond MemGPT** that differ significantly from the architecture proposed in the research paper - for example, agents with multiple logical threads (e.g. a "concious" and a "subconcious"), or agents with more advanced memory types (e.g. task memory).
+
+Additionally, **the Letta framework also allows you to expose your agents as *services*** (over REST APIs) - so you can use the Letta framework to power your AI applications.
diff --git a/fern/pages/mcp/overview.mdx b/fern/pages/mcp/overview.mdx
new file mode 100644
index 00000000..55612ecc
--- /dev/null
+++ b/fern/pages/mcp/overview.mdx
@@ -0,0 +1,65 @@
+---
+title: What is Model Context Protocol (MCP)?
+subtitle: What is MCP, and how can it be combined with agents?
+slug: guides/mcp/overview
+---
+
+[Model Context Protocol (MCP)](https://modelcontextprotocol.io) is an open protocol that enables seamless integration between LLM applications and external data sources and tools.
+In Letta, you can create your own [custom tools](/guides/agents/custom-tools) that run in the Letta tool sandbox, or use MCP to connect to tools that run on external servers.
+
+**Already familiar with MCP?** Jump to the [setup guide](/guides/mcp/setup).
+
+## Architecture
+
+MCP uses a **host-client-server** model. Letta acts as the **host**, creating **clients** that connect to external **servers**. Each server exposes tools, resources, or prompts through the standardized MCP protocol.
+
+Letta's MCP integration connects your agents to external tools and data sources without requiring custom integrations.
+
+## Integration Flow
+
+```mermaid
+flowchart LR
+ subgraph L ["Letta"]
+ LH[Host] --> LC1[Client 1]
+ LH --> LC2[Client 2]
+ LH --> LC3[Client 3]
+ end
+
+ subgraph S ["MCP Servers"]
+ MS1[GitHub]
+ MS2[Database]
+ MS3[Files]
+ end
+
+ LC1 <--> MS1
+ LC2 <--> MS2
+ LC3 <--> MS3
+```
+
+Letta creates isolated clients for each MCP server, maintaining security boundaries while providing agents access to specialized capabilities.
+
+## Connection Methods
+
+- **ADE**: Point-and-click server management through Letta's web interface
+- **API/SDK**: Programmatic integration for production deployments
+
+
+
+
+**MemGPT** is the name of a [**research paper**](https://arxiv.org/abs/2310.08560) that popularized several of the key concepts behind the "LLM Operating System (OS)":
+1. **Memory management**: In MemGPT, an LLM OS moves data in and out of the context window of the LLM to manage its memory.
+2. **Memory hierarchy**: The "LLM OS" divides the LLM's memory (aka its "virtual context", similar to "[virtual memory](https://en.wikipedia.org/wiki/Virtual_memory)" in computer systems) into two parts: the in-context memory, and out-of-context memory.
+3. **Self-editing memory via tool calling**: In MemGPT, the "OS" that manages memory is itself an LLM. The LLM moves data in and out of the context window using designated memory-editing tools.
+4. **Multi-step reasoning using heartbeats**: MemGPT supports multi-step reasoning (allowing the agent to take multiple steps in sequence) via the concept of "heartbeats". Whenever the LLM outputs a tool call, it has to option to request a heartbeat by setting the keyword argument `request_heartbeat` to `true`. If the LLM requests a heartbeat, the LLM OS continues execution in a loop, allowing the LLM to "think" again.
+
+You can read more about the MemGPT memory hierarchy and memory management system in our [memory concepts guide](/advanced/memory_management).
+
+## MemGPT - the agent architecture
+
+**MemGPT** also refers to a particular **agent architecture** that was popularized by the paper and adopted widely by other LLM chatbots:
+1. **Chat-focused core memory**: The core memory of a MemGPT agent is split into two parts - the agent's own persona, and the user information. Because the MemGPT agent has self-editing memory, it can update its own personality over time, as well as update the user information as it learns new facts about the user.
+2. **Vector database archival memory**: By default, the archival memory connected to a MemGPT agent is backed by a vector database, such as [Chroma](https://www.trychroma.com/) or [pgvector](https://github.com/pgvector/pgvector). Because in MemGPT all connections to memory are driven by tools, it's simple to exchange archival memory to be powered by a more traditional database (you can even make archival memory a flatfile if you want!).
+
+## Creating MemGPT agents in the Letta framework
+
+Because **Letta** was created out of the original MemGPT open source project, it's extremely easy to make MemGPT agents inside of Letta (the default Letta agent architecture is a MemGPT agent).
+See our [agents overview](/guides/agents/overview) for a tutorial on how to create MemGPT agents with Letta.
+
+**The Letta framework also allow you to make agent architectures beyond MemGPT** that differ significantly from the architecture proposed in the research paper - for example, agents with multiple logical threads (e.g. a "concious" and a "subconcious"), or agents with more advanced memory types (e.g. task memory).
+
+Additionally, **the Letta framework also allows you to expose your agents as *services*** (over REST APIs) - so you can use the Letta framework to power your AI applications.
diff --git a/fern/pages/mcp/overview.mdx b/fern/pages/mcp/overview.mdx
new file mode 100644
index 00000000..55612ecc
--- /dev/null
+++ b/fern/pages/mcp/overview.mdx
@@ -0,0 +1,65 @@
+---
+title: What is Model Context Protocol (MCP)?
+subtitle: What is MCP, and how can it be combined with agents?
+slug: guides/mcp/overview
+---
+
+[Model Context Protocol (MCP)](https://modelcontextprotocol.io) is an open protocol that enables seamless integration between LLM applications and external data sources and tools.
+In Letta, you can create your own [custom tools](/guides/agents/custom-tools) that run in the Letta tool sandbox, or use MCP to connect to tools that run on external servers.
+
+**Already familiar with MCP?** Jump to the [setup guide](/guides/mcp/setup).
+
+## Architecture
+
+MCP uses a **host-client-server** model. Letta acts as the **host**, creating **clients** that connect to external **servers**. Each server exposes tools, resources, or prompts through the standardized MCP protocol.
+
+Letta's MCP integration connects your agents to external tools and data sources without requiring custom integrations.
+
+## Integration Flow
+
+```mermaid
+flowchart LR
+ subgraph L ["Letta"]
+ LH[Host] --> LC1[Client 1]
+ LH --> LC2[Client 2]
+ LH --> LC3[Client 3]
+ end
+
+ subgraph S ["MCP Servers"]
+ MS1[GitHub]
+ MS2[Database]
+ MS3[Files]
+ end
+
+ LC1 <--> MS1
+ LC2 <--> MS2
+ LC3 <--> MS3
+```
+
+Letta creates isolated clients for each MCP server, maintaining security boundaries while providing agents access to specialized capabilities.
+
+## Connection Methods
+
+- **ADE**: Point-and-click server management through Letta's web interface
+- **API/SDK**: Programmatic integration for production deployments
+
+ +
+**ADE**: Tool Manager → Add MCP Server → Streamable HTTP
+
+### Agent Id Header
+
+When Letta makes tool calls to an MCP server, it includes the following in the HTTP request header:
+
+- **`x-agent-id`**: The ID of the agent making the tool call
+
+If you're implementing your own MCP server, this can be used to make requests against your Letta Agent via our API/SDK.
+
+### Agent Scoped Variables
+
+Letta recognizes templated variables in the custom header and auth token fields to allow for agent-scoped parameters defined in your [tool variables](/guides/agents/tool-variables):
+- For example, **`{{ AGENT_API_KEY }}`** will use the `AGENT_API_KEY` tool variable if available.
+- To provide a default value, **`{{ AGENT_API_KEY | api_key }}`** will fallback to `api_key` if `AGENT_API_KEY` is not set.
+- This is supported in the ADE as well when configuring API key/access tokens and custom headers.
+
+
+
+**ADE**: Tool Manager → Add MCP Server → Streamable HTTP
+
+### Agent Id Header
+
+When Letta makes tool calls to an MCP server, it includes the following in the HTTP request header:
+
+- **`x-agent-id`**: The ID of the agent making the tool call
+
+If you're implementing your own MCP server, this can be used to make requests against your Letta Agent via our API/SDK.
+
+### Agent Scoped Variables
+
+Letta recognizes templated variables in the custom header and auth token fields to allow for agent-scoped parameters defined in your [tool variables](/guides/agents/tool-variables):
+- For example, **`{{ AGENT_API_KEY }}`** will use the `AGENT_API_KEY` tool variable if available.
+- To provide a default value, **`{{ AGENT_API_KEY | api_key }}`** will fallback to `api_key` if `AGENT_API_KEY` is not set.
+- This is supported in the ADE as well when configuring API key/access tokens and custom headers.
+
+ diff --git a/fern/pages/selfhosting/postgres.mdx b/fern/pages/selfhosting/postgres.mdx
new file mode 100644
index 00000000..839dcbb2
--- /dev/null
+++ b/fern/pages/selfhosting/postgres.mdx
@@ -0,0 +1,13 @@
+---
+title: Database Configuration
+subtitle: Configure Letta's Postgres DB backend
+slug: guides/selfhosting/postgres
+---
+
+## Connecting your own Postgres instance
+You can set `LETTA_PG_URI` to connect your own Postgres instance to Letta. Your database must have the `pgvector` vector extension installed.
+
+You can enable this extension by running the following SQL command:
+```sql
+CREATE EXTENSION IF NOT EXISTS vector;
+```
diff --git a/fern/pages/selfhosting/supported-models.mdx b/fern/pages/selfhosting/supported-models.mdx
new file mode 100644
index 00000000..819b58bb
--- /dev/null
+++ b/fern/pages/selfhosting/supported-models.mdx
@@ -0,0 +1,219 @@
+---
+title: Supported Models
+generated: 2025-06-27T14:10:15.033946
+---
+
+# Supported Models
+
+## Overview
+
+Letta routinely runs automated scans against available providers and models. These are the results of the latest scan.
+
+Ran 2512 tests against 157 models across 7 providers on June 27th, 2025
+
+
+## anthropic
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `claude-3-5-haiku-20241022` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-5-sonnet-20240620` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-5-sonnet-20241022` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-7-sonnet-20250219` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-opus-4-20250514` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-sonnet-4-20250514` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-opus-20240229` | ❌ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-haiku-20240307` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-sonnet-20240229` | ❌ | ❌ | ❌ | 200,000 | 2025-06-27 |
+
+---
+
+## openai
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `gpt-4-turbo` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4-turbo-2024-04-09` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4.1` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-2025-04-14` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-mini` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-mini-2025-04-14` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-nano` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-nano-2025-04-14` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4o` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-2024-05-13` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-2024-08-06` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-2024-11-20` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-mini` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-mini-2024-07-18` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4-0613` | ✅ | ✅ | ❌ | 8,192 | 2025-06-27 |
+| `gpt-4-1106-preview` | ✅ | ✅ | ❌ | 128,000 | 2025-06-27 |
+| `gpt-4-turbo-preview` | ✅ | ✅ | ❌ | 128,000 | 2025-06-27 |
+| `gpt-4-0125-preview` | ❌ | ✅ | ❌ | 128,000 | 2025-06-27 |
+| `o1` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o1-2024-12-17` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o3` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o3-2025-04-16` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o4-mini` | ❌ | ❌ | ✅ | 30,000 | 2025-06-27 |
+| `o4-mini-2025-04-16` | ❌ | ❌ | ✅ | 30,000 | 2025-06-27 |
+| `gpt-4` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `o3-mini` | ❌ | ❌ | ❌ | 200,000 | 2025-06-27 |
+| `o3-mini-2025-01-31` | ❌ | ❌ | ❌ | 200,000 | 2025-06-27 |
+| `o3-pro` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `o3-pro-2025-06-10` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+
+---
+
+## google_ai
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `gemini-1.5-pro` | ✅ | ✅ | ✅ | 2,000,000 | 2025-06-27 |
+| `gemini-1.5-pro-002` | ✅ | ✅ | ✅ | 2,000,000 | 2025-06-27 |
+| `gemini-1.5-pro-latest` | ✅ | ✅ | ✅ | 2,000,000 | 2025-06-27 |
+| `gemini-2.0-flash-thinking-exp` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-04-17` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro-preview-03-25` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro-preview-05-06` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash` | ✅ | ❌ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-thinking-exp-1219` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-04-17-thinking` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-05-20` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro-preview-06-05` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-thinking-exp-01-21` | ❌ | ❌ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-lite-preview-06-17` | ❌ | ❌ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-1.0-pro-vision-latest` | ❌ | ❌ | ❌ | 12,288 | 2025-06-27 |
+| `gemini-1.5-flash` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-002` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-8b` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-8b-001` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-8b-latest` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-latest` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-2.0-flash` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-001` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-exp` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-exp-image-generation` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite-001` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite-preview` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite-preview-02-05` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-preview-image-generation` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `gemini-2.0-pro-exp` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-pro-exp-02-05` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-tts` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `gemini-2.5-pro-preview-tts` | ❌ | ❌ | ❌ | 65,536 | 2025-06-27 |
+| `gemini-exp-1206` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-pro-vision` | ❌ | ❌ | ❌ | 12,288 | 2025-06-27 |
+
+---
+
+## together
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `arcee-ai/coder-large` | ✅ | ✅ | ✅ | 32,768 | 2025-06-27 |
+| `meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `Qwen/Qwen2.5-Coder-32B-Instruct` | ✅ | ✅ | ❌ | 32,768 | 2025-06-27 |
+| `meta-llama/Llama-3.3-70B-Instruct-Turbo` | ✅ | ✅ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-3.3-70B-Instruct-Turbo-Free` | ✅ | ✅ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo` | ✅ | ✅ | ❌ | 130,815 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo` | ✅ | ✅ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-V3` | ✅ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo` | ✅ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `Qwen/Qwen2.5-72B-Instruct-Turbo` | ❌ | ✅ | ✅ | 131,072 | 2025-06-27 |
+| `arcee-ai/virtuoso-large` | ❌ | ✅ | ✅ | 131,072 | 2025-06-27 |
+| `arcee-ai/virtuoso-medium-v2` | ❌ | ✅ | ✅ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-4-Scout-17B-16E-Instruct` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `Qwen/Qwen3-235B-A22B-fp8-tput` | ❌ | ✅ | ❌ | 40,960 | 2025-06-27 |
+| `nvidia/Llama-3.1-Nemotron-70B-Instruct-HF` | ❌ | ✅ | ❌ | 32,768 | 2025-06-27 |
+| `scb10x/scb10x-llama3-1-typhoon2-70b-instruct` | ❌ | ✅ | ❌ | 8,192 | 2025-06-27 |
+| `NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO` | ❌ | ❌ | ✅ | 32,768 | 2025-06-27 |
+| `Qwen/QwQ-32B` | ❌ | ❌ | ✅ | 131,072 | 2025-06-27 |
+| `google/gemma-3n-E4B-it` | ❌ | ❌ | ✅ | 32,768 | 2025-06-27 |
+| `mistralai/Mistral-7B-Instruct-v0.2` | ❌ | ❌ | ✅ | 32,768 | 2025-06-27 |
+| `perplexity-ai/r1-1776` | ❌ | ❌ | ✅ | 163,840 | 2025-06-27 |
+| `Qwen/Qwen2-72B-Instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `Qwen/Qwen2-VL-72B-Instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `Qwen/Qwen2.5-7B-Instruct-Turbo` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `Qwen/Qwen2.5-VL-72B-Instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `arcee-ai/AFM-4.5B-Preview` | ❌ | ❌ | ❌ | 65,536 | 2025-06-27 |
+| `arcee-ai/arcee-blitz` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `arcee-ai/caller` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `arcee-ai/maestro-reasoning` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `arcee_ai/arcee-spotlight` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1` | ❌ | ❌ | ❌ | 163,840 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-0528-tput` | ❌ | ❌ | ❌ | 163,840 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Llama-70B` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Llama-70B-free` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Qwen-14B` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-V3-p-dp` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `google/gemma-2-27b-it` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `lgai/exaone-3-5-32b-instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `lgai/exaone-deep-32b` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `meta-llama/Llama-3-70b-chat-hf` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `meta-llama/Llama-3-8b-chat-hf` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-3.2-3B-Instruct-Turbo` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-Vision-Free` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3-70B-Instruct-Turbo` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3-8B-Instruct-Lite` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `mistralai/Mistral-7B-Instruct-v0.1` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `mistralai/Mistral-7B-Instruct-v0.3` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `mistralai/Mistral-Small-24B-Instruct-2501` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `mistralai/Mixtral-8x7B-Instruct-v0.1` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `scb10x/scb10x-typhoon-2-1-gemma3-12b` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `togethercomputer/MoA-1` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `togethercomputer/MoA-1-Turbo` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `togethercomputer/Refuel-Llm-V2` | ❌ | ❌ | ❌ | 16,384 | 2025-06-27 |
+| `togethercomputer/Refuel-Llm-V2-Small` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+
+---
+
+## deepseek
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `deepseek-chat` | ❌ | ❌ | ❌ | 64,000 | 2025-06-27 |
+| `deepseek-reasoner` | ❌ | ❌ | ❌ | 64,000 | 2025-06-27 |
+
+---
+
+## groq
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `allam-2-7b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `compound-beta` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `compound-beta-mini` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `deepseek-r1-distill-llama-70b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `distil-whisper-large-v3-en` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `gemma2-9b-it` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama-3.1-8b-instant` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama-3.3-70b-versatile` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama3-70b-8192` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama3-8b-8192` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-4-maverick-17b-128e-instruct` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-4-scout-17b-16e-instruct` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-guard-4-12b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-prompt-guard-2-22m` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-prompt-guard-2-86m` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `mistral-saba-24b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `playai-tts` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `playai-tts-arabic` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `qwen-qwq-32b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `qwen/qwen3-32b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `whisper-large-v3` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `whisper-large-v3-turbo` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+
+---
+
+## letta
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `letta-free` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+
+---
diff --git a/fern/pages/selfhosting/tool_execution.mdx b/fern/pages/selfhosting/tool_execution.mdx
new file mode 100644
index 00000000..e69de29b
diff --git a/fern/pages/server/docker.mdx b/fern/pages/server/docker.mdx
new file mode 100644
index 00000000..cbadffa6
--- /dev/null
+++ b/fern/pages/server/docker.mdx
@@ -0,0 +1,119 @@
+---
+title: Run Letta with Docker
+slug: guides/server/docker
+---
+
+
+
diff --git a/fern/pages/selfhosting/postgres.mdx b/fern/pages/selfhosting/postgres.mdx
new file mode 100644
index 00000000..839dcbb2
--- /dev/null
+++ b/fern/pages/selfhosting/postgres.mdx
@@ -0,0 +1,13 @@
+---
+title: Database Configuration
+subtitle: Configure Letta's Postgres DB backend
+slug: guides/selfhosting/postgres
+---
+
+## Connecting your own Postgres instance
+You can set `LETTA_PG_URI` to connect your own Postgres instance to Letta. Your database must have the `pgvector` vector extension installed.
+
+You can enable this extension by running the following SQL command:
+```sql
+CREATE EXTENSION IF NOT EXISTS vector;
+```
diff --git a/fern/pages/selfhosting/supported-models.mdx b/fern/pages/selfhosting/supported-models.mdx
new file mode 100644
index 00000000..819b58bb
--- /dev/null
+++ b/fern/pages/selfhosting/supported-models.mdx
@@ -0,0 +1,219 @@
+---
+title: Supported Models
+generated: 2025-06-27T14:10:15.033946
+---
+
+# Supported Models
+
+## Overview
+
+Letta routinely runs automated scans against available providers and models. These are the results of the latest scan.
+
+Ran 2512 tests against 157 models across 7 providers on June 27th, 2025
+
+
+## anthropic
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `claude-3-5-haiku-20241022` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-5-sonnet-20240620` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-5-sonnet-20241022` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-7-sonnet-20250219` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-opus-4-20250514` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-sonnet-4-20250514` | ✅ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-opus-20240229` | ❌ | ✅ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-haiku-20240307` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `claude-3-sonnet-20240229` | ❌ | ❌ | ❌ | 200,000 | 2025-06-27 |
+
+---
+
+## openai
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `gpt-4-turbo` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4-turbo-2024-04-09` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4.1` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-2025-04-14` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-mini` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-mini-2025-04-14` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-nano` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4.1-nano-2025-04-14` | ✅ | ✅ | ✅ | 1,047,576 | 2025-06-27 |
+| `gpt-4o` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-2024-05-13` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-2024-08-06` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-2024-11-20` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-mini` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4o-mini-2024-07-18` | ✅ | ✅ | ✅ | 128,000 | 2025-06-27 |
+| `gpt-4-0613` | ✅ | ✅ | ❌ | 8,192 | 2025-06-27 |
+| `gpt-4-1106-preview` | ✅ | ✅ | ❌ | 128,000 | 2025-06-27 |
+| `gpt-4-turbo-preview` | ✅ | ✅ | ❌ | 128,000 | 2025-06-27 |
+| `gpt-4-0125-preview` | ❌ | ✅ | ❌ | 128,000 | 2025-06-27 |
+| `o1` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o1-2024-12-17` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o3` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o3-2025-04-16` | ❌ | ❌ | ✅ | 200,000 | 2025-06-27 |
+| `o4-mini` | ❌ | ❌ | ✅ | 30,000 | 2025-06-27 |
+| `o4-mini-2025-04-16` | ❌ | ❌ | ✅ | 30,000 | 2025-06-27 |
+| `gpt-4` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `o3-mini` | ❌ | ❌ | ❌ | 200,000 | 2025-06-27 |
+| `o3-mini-2025-01-31` | ❌ | ❌ | ❌ | 200,000 | 2025-06-27 |
+| `o3-pro` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `o3-pro-2025-06-10` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+
+---
+
+## google_ai
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `gemini-1.5-pro` | ✅ | ✅ | ✅ | 2,000,000 | 2025-06-27 |
+| `gemini-1.5-pro-002` | ✅ | ✅ | ✅ | 2,000,000 | 2025-06-27 |
+| `gemini-1.5-pro-latest` | ✅ | ✅ | ✅ | 2,000,000 | 2025-06-27 |
+| `gemini-2.0-flash-thinking-exp` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-04-17` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro-preview-03-25` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro-preview-05-06` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash` | ✅ | ❌ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-thinking-exp-1219` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-04-17-thinking` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-05-20` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-pro-preview-06-05` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-thinking-exp-01-21` | ❌ | ❌ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-lite-preview-06-17` | ❌ | ❌ | ✅ | 1,048,576 | 2025-06-27 |
+| `gemini-1.0-pro-vision-latest` | ❌ | ❌ | ❌ | 12,288 | 2025-06-27 |
+| `gemini-1.5-flash` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-002` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-8b` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-8b-001` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-8b-latest` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-1.5-flash-latest` | ❌ | ❌ | ❌ | 1,000,000 | 2025-06-27 |
+| `gemini-2.0-flash` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-001` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-exp` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-exp-image-generation` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite-001` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite-preview` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-lite-preview-02-05` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-flash-preview-image-generation` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `gemini-2.0-pro-exp` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.0-pro-exp-02-05` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-2.5-flash-preview-tts` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `gemini-2.5-pro-preview-tts` | ❌ | ❌ | ❌ | 65,536 | 2025-06-27 |
+| `gemini-exp-1206` | ❌ | ❌ | ❌ | 1,048,576 | 2025-06-27 |
+| `gemini-pro-vision` | ❌ | ❌ | ❌ | 12,288 | 2025-06-27 |
+
+---
+
+## together
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `arcee-ai/coder-large` | ✅ | ✅ | ✅ | 32,768 | 2025-06-27 |
+| `meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8` | ✅ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `Qwen/Qwen2.5-Coder-32B-Instruct` | ✅ | ✅ | ❌ | 32,768 | 2025-06-27 |
+| `meta-llama/Llama-3.3-70B-Instruct-Turbo` | ✅ | ✅ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-3.3-70B-Instruct-Turbo-Free` | ✅ | ✅ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo` | ✅ | ✅ | ❌ | 130,815 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo` | ✅ | ✅ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-V3` | ✅ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo` | ✅ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `Qwen/Qwen2.5-72B-Instruct-Turbo` | ❌ | ✅ | ✅ | 131,072 | 2025-06-27 |
+| `arcee-ai/virtuoso-large` | ❌ | ✅ | ✅ | 131,072 | 2025-06-27 |
+| `arcee-ai/virtuoso-medium-v2` | ❌ | ✅ | ✅ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-4-Scout-17B-16E-Instruct` | ❌ | ✅ | ✅ | 1,048,576 | 2025-06-27 |
+| `Qwen/Qwen3-235B-A22B-fp8-tput` | ❌ | ✅ | ❌ | 40,960 | 2025-06-27 |
+| `nvidia/Llama-3.1-Nemotron-70B-Instruct-HF` | ❌ | ✅ | ❌ | 32,768 | 2025-06-27 |
+| `scb10x/scb10x-llama3-1-typhoon2-70b-instruct` | ❌ | ✅ | ❌ | 8,192 | 2025-06-27 |
+| `NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO` | ❌ | ❌ | ✅ | 32,768 | 2025-06-27 |
+| `Qwen/QwQ-32B` | ❌ | ❌ | ✅ | 131,072 | 2025-06-27 |
+| `google/gemma-3n-E4B-it` | ❌ | ❌ | ✅ | 32,768 | 2025-06-27 |
+| `mistralai/Mistral-7B-Instruct-v0.2` | ❌ | ❌ | ✅ | 32,768 | 2025-06-27 |
+| `perplexity-ai/r1-1776` | ❌ | ❌ | ✅ | 163,840 | 2025-06-27 |
+| `Qwen/Qwen2-72B-Instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `Qwen/Qwen2-VL-72B-Instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `Qwen/Qwen2.5-7B-Instruct-Turbo` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `Qwen/Qwen2.5-VL-72B-Instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `arcee-ai/AFM-4.5B-Preview` | ❌ | ❌ | ❌ | 65,536 | 2025-06-27 |
+| `arcee-ai/arcee-blitz` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `arcee-ai/caller` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `arcee-ai/maestro-reasoning` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `arcee_ai/arcee-spotlight` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1` | ❌ | ❌ | ❌ | 163,840 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-0528-tput` | ❌ | ❌ | ❌ | 163,840 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Llama-70B` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Llama-70B-free` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-R1-Distill-Qwen-14B` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `deepseek-ai/DeepSeek-V3-p-dp` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `google/gemma-2-27b-it` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `lgai/exaone-3-5-32b-instruct` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `lgai/exaone-deep-32b` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `meta-llama/Llama-3-70b-chat-hf` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `meta-llama/Llama-3-8b-chat-hf` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-3.2-3B-Instruct-Turbo` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Llama-Vision-Free` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3-70B-Instruct-Turbo` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `meta-llama/Meta-Llama-3-8B-Instruct-Lite` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+| `mistralai/Mistral-7B-Instruct-v0.1` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `mistralai/Mistral-7B-Instruct-v0.3` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `mistralai/Mistral-Small-24B-Instruct-2501` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `mistralai/Mixtral-8x7B-Instruct-v0.1` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `scb10x/scb10x-typhoon-2-1-gemma3-12b` | ❌ | ❌ | ❌ | 131,072 | 2025-06-27 |
+| `togethercomputer/MoA-1` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `togethercomputer/MoA-1-Turbo` | ❌ | ❌ | ❌ | 32,768 | 2025-06-27 |
+| `togethercomputer/Refuel-Llm-V2` | ❌ | ❌ | ❌ | 16,384 | 2025-06-27 |
+| `togethercomputer/Refuel-Llm-V2-Small` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+
+---
+
+## deepseek
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `deepseek-chat` | ❌ | ❌ | ❌ | 64,000 | 2025-06-27 |
+| `deepseek-reasoner` | ❌ | ❌ | ❌ | 64,000 | 2025-06-27 |
+
+---
+
+## groq
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `allam-2-7b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `compound-beta` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `compound-beta-mini` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `deepseek-r1-distill-llama-70b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `distil-whisper-large-v3-en` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `gemma2-9b-it` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama-3.1-8b-instant` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama-3.3-70b-versatile` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama3-70b-8192` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `llama3-8b-8192` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-4-maverick-17b-128e-instruct` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-4-scout-17b-16e-instruct` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-guard-4-12b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-prompt-guard-2-22m` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `meta-llama/llama-prompt-guard-2-86m` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `mistral-saba-24b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `playai-tts` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `playai-tts-arabic` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `qwen-qwq-32b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `qwen/qwen3-32b` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `whisper-large-v3` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+| `whisper-large-v3-turbo` | ❌ | ❌ | ❌ | 30,000 | 2025-06-27 |
+
+---
+
+## letta
+
+| Model | Basic | Token Streaming | Multimodal | Context Window | Last Scanned |
+|---------------------------------------------------|:---:|:-------------:|:--------:|:-------:|:----------:|
+| `letta-free` | ❌ | ❌ | ❌ | 8,192 | 2025-06-27 |
+
+---
diff --git a/fern/pages/selfhosting/tool_execution.mdx b/fern/pages/selfhosting/tool_execution.mdx
new file mode 100644
index 00000000..e69de29b
diff --git a/fern/pages/server/docker.mdx b/fern/pages/server/docker.mdx
new file mode 100644
index 00000000..cbadffa6
--- /dev/null
+++ b/fern/pages/server/docker.mdx
@@ -0,0 +1,119 @@
+---
+title: Run Letta with Docker
+slug: guides/server/docker
+---
+
+
+ +
+Let's call agent 1 "Bob" and agent 2 "Alice" (these are just for us to help keep track of them - the agents themselves will communicate via agent IDs).
+To spice things up, let's make "Bob" (shown in light mode) powered by `gpt-4o-mini`, and "Alice" (shown in dark mode) powered by `claude-3.5-sonnet`.
+
+
+
+Let's call agent 1 "Bob" and agent 2 "Alice" (these are just for us to help keep track of them - the agents themselves will communicate via agent IDs).
+To spice things up, let's make "Bob" (shown in light mode) powered by `gpt-4o-mini`, and "Alice" (shown in dark mode) powered by `claude-3.5-sonnet`.
+
+ +
+ +
+
+
+ +
+### Step 2: Prepare agent 1 (Bob) to receive a message
+Now let's get the agents ready to talk to each other.
+Let's prime Bob to get ready for an incoming message from Alice.
+Without this additional context, Bob may become confused about what's going on (we could also provide this extra context via the memory blocks instead).
+
+> Hey - just letting you know I'm going to connect you with another one of my agent buddies. Hope you enjoy chatting with them (I think they'll reach out directly).
+
+
+
+### Step 2: Prepare agent 1 (Bob) to receive a message
+Now let's get the agents ready to talk to each other.
+Let's prime Bob to get ready for an incoming message from Alice.
+Without this additional context, Bob may become confused about what's going on (we could also provide this extra context via the memory blocks instead).
+
+> Hey - just letting you know I'm going to connect you with another one of my agent buddies. Hope you enjoy chatting with them (I think they'll reach out directly).
+
+ +
+### Step 3: Ask agent 2 (Alice) to send the first message
+Next, let's ask Alice to send a message to Bob.
+We'll copy Bob's agent ID and use it in the message.
+
+We'll also make sure to include a note to Alice to report her results back to us to - otherwise, we might have to wait a while for them to finish!
+
+> Hey, my other agent friend is lonely and needs someone to chat to. Can you give them a ring? Their ID is agent-af4f8b2b-cb46-4d22-b813-6b3f6659213a. If you can reach them, have a short conversation but let me know after a few messages how they're doing!
+
+### Step 4: Watch the two agents converse!
+As soon as we send the message to Alice, we can see Alice and Bob start to communicate with each other!
+To watch the communication happen live, you can open two tabs on the web ADE - one for each agent - and place them side-by-side.
+If you're using Letta Desktop, you can switch between the agents to monitor their conversation.
+
+
+
+### Step 3: Ask agent 2 (Alice) to send the first message
+Next, let's ask Alice to send a message to Bob.
+We'll copy Bob's agent ID and use it in the message.
+
+We'll also make sure to include a note to Alice to report her results back to us to - otherwise, we might have to wait a while for them to finish!
+
+> Hey, my other agent friend is lonely and needs someone to chat to. Can you give them a ring? Their ID is agent-af4f8b2b-cb46-4d22-b813-6b3f6659213a. If you can reach them, have a short conversation but let me know after a few messages how they're doing!
+
+### Step 4: Watch the two agents converse!
+As soon as we send the message to Alice, we can see Alice and Bob start to communicate with each other!
+To watch the communication happen live, you can open two tabs on the web ADE - one for each agent - and place them side-by-side.
+If you're using Letta Desktop, you can switch between the agents to monitor their conversation.
+
+ +
+ +
+
+
+ +
+  +
+  +
+
+
+
+
+