diff --git a/.gitattributes b/.gitattributes
new file mode 100644
index 00000000..108cb3b3
--- /dev/null
+++ b/.gitattributes
@@ -0,0 +1,20 @@
+# Set the default behavior, in case people don't have core.autocrlf set.
+* text=auto
+
+# Explicitly declare text files you want to always be normalized and converted
+# to LF on checkout.
+*.py text eol=lf
+*.txt text eol=lf
+*.md text eol=lf
+*.json text eol=lf
+*.yml text eol=lf
+*.yaml text eol=lf
+
+# Declare files that will always have CRLF line endings on checkout.
+# (Only if you have specific Windows-only files)
+*.bat text eol=crlf
+
+# Denote all files that are truly binary and should not be modified.
+*.png binary
+*.jpg binary
+*.gif binary
diff --git a/.gitignore b/.gitignore
index 26d77194..92123a56 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,1019 +1,1019 @@
-# MemGPT config files
-configs/
-
-# Below are generated by gitignor.io (toptal)
-# Created by https://www.toptal.com/developers/gitignore/api/vim,linux,macos,pydev,python,eclipse,pycharm,windows,netbeans,pycharm+all,pycharm+iml,visualstudio,jupyternotebooks,visualstudiocode,xcode,xcodeinjection
-# Edit at https://www.toptal.com/developers/gitignore?templates=vim,linux,macos,pydev,python,eclipse,pycharm,windows,netbeans,pycharm+all,pycharm+iml,visualstudio,jupyternotebooks,visualstudiocode,xcode,xcodeinjection
-
-### Eclipse ###
-.metadata
-bin/
-tmp/
-*.tmp
-*.bak
-*.swp
-*~.nib
-local.properties
-.settings/
-.loadpath
-.recommenders
-
-# External tool builders
-.externalToolBuilders/
-
-# Locally stored "Eclipse launch configurations"
-*.launch
-
-# PyDev specific (Python IDE for Eclipse)
-*.pydevproject
-
-# CDT-specific (C/C++ Development Tooling)
-.cproject
-
-# CDT- autotools
-.autotools
-
-# Java annotation processor (APT)
-.factorypath
-
-# PDT-specific (PHP Development Tools)
-.buildpath
-
-# sbteclipse plugin
-.target
-
-# Tern plugin
-.tern-project
-
-# TeXlipse plugin
-.texlipse
-
-# STS (Spring Tool Suite)
-.springBeans
-
-# Code Recommenders
-.recommenders/
-
-# Annotation Processing
-.apt_generated/
-.apt_generated_test/
-
-# Scala IDE specific (Scala & Java development for Eclipse)
-.cache-main
-.scala_dependencies
-.worksheet
-
-# Uncomment this line if you wish to ignore the project description file.
-# Typically, this file would be tracked if it contains build/dependency configurations:
-#.project
-
-### Eclipse Patch ###
-# Spring Boot Tooling
-.sts4-cache/
-
-### JupyterNotebooks ###
-# gitignore template for Jupyter Notebooks
-# website: http://jupyter.org/
-
-.ipynb_checkpoints
-*/.ipynb_checkpoints/*
-
-# IPython
-profile_default/
-ipython_config.py
-
-# Remove previous ipynb_checkpoints
-# git rm -r .ipynb_checkpoints/
-
-### Linux ###
-*~
-
-# temporary files which can be created if a process still has a handle open of a deleted file
-.fuse_hidden*
-
-# KDE directory preferences
-.directory
-
-# Linux trash folder which might appear on any partition or disk
-.Trash-*
-
-# .nfs files are created when an open file is removed but is still being accessed
-.nfs*
-
-### macOS ###
-# General
-.DS_Store
-.AppleDouble
-.LSOverride
-
-# Icon must end with two \r
-Icon
-
-
-# Thumbnails
-._*
-
-# Files that might appear in the root of a volume
-.DocumentRevisions-V100
-.fseventsd
-.Spotlight-V100
-.TemporaryItems
-.Trashes
-.VolumeIcon.icns
-.com.apple.timemachine.donotpresent
-
-# Directories potentially created on remote AFP share
-.AppleDB
-.AppleDesktop
-Network Trash Folder
-Temporary Items
-.apdisk
-
-### macOS Patch ###
-# iCloud generated files
-*.icloud
-
-### NetBeans ###
-**/nbproject/private/
-**/nbproject/Makefile-*.mk
-**/nbproject/Package-*.bash
-build/
-nbbuild/
-dist/
-nbdist/
-.nb-gradle/
-
-### PyCharm ###
-# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
-# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
-
-# User-specific stuff
-.idea/**/workspace.xml
-.idea/**/tasks.xml
-.idea/**/usage.statistics.xml
-.idea/**/dictionaries
-.idea/**/shelf
-
-# AWS User-specific
-.idea/**/aws.xml
-
-# Generated files
-.idea/**/contentModel.xml
-
-# Sensitive or high-churn files
-.idea/**/dataSources/
-.idea/**/dataSources.ids
-.idea/**/dataSources.local.xml
-.idea/**/sqlDataSources.xml
-.idea/**/dynamic.xml
-.idea/**/uiDesigner.xml
-.idea/**/dbnavigator.xml
-
-# Gradle
-.idea/**/gradle.xml
-.idea/**/libraries
-
-# Gradle and Maven with auto-import
-# When using Gradle or Maven with auto-import, you should exclude module files,
-# since they will be recreated, and may cause churn. Uncomment if using
-# auto-import.
-# .idea/artifacts
-# .idea/compiler.xml
-# .idea/jarRepositories.xml
-# .idea/modules.xml
-# .idea/*.iml
-# .idea/modules
-# *.iml
-# *.ipr
-
-# CMake
-cmake-build-*/
-
-# Mongo Explorer plugin
-.idea/**/mongoSettings.xml
-
-# File-based project format
-*.iws
-
-# IntelliJ
-out/
-
-# mpeltonen/sbt-idea plugin
-.idea_modules/
-
-# JIRA plugin
-atlassian-ide-plugin.xml
-
-# Cursive Clojure plugin
-.idea/replstate.xml
-
-# SonarLint plugin
-.idea/sonarlint/
-
-# Crashlytics plugin (for Android Studio and IntelliJ)
-com_crashlytics_export_strings.xml
-crashlytics.properties
-crashlytics-build.properties
-fabric.properties
-
-# Editor-based Rest Client
-.idea/httpRequests
-
-# Android studio 3.1+ serialized cache file
-.idea/caches/build_file_checksums.ser
-
-### PyCharm Patch ###
-# Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
-
-# *.iml
-# modules.xml
-# .idea/misc.xml
-# *.ipr
-
-# Sonarlint plugin
-# https://plugins.jetbrains.com/plugin/7973-sonarlint
-.idea/**/sonarlint/
-
-# SonarQube Plugin
-# https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
-.idea/**/sonarIssues.xml
-
-# Markdown Navigator plugin
-# https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
-.idea/**/markdown-navigator.xml
-.idea/**/markdown-navigator-enh.xml
-.idea/**/markdown-navigator/
-
-# Cache file creation bug
-# See https://youtrack.jetbrains.com/issue/JBR-2257
-.idea/$CACHE_FILE$
-
-# CodeStream plugin
-# https://plugins.jetbrains.com/plugin/12206-codestream
-.idea/codestream.xml
-
-# Azure Toolkit for IntelliJ plugin
-# https://plugins.jetbrains.com/plugin/8053-azure-toolkit-for-intellij
-.idea/**/azureSettings.xml
-
-### PyCharm+all ###
-# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
-# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
-
-# User-specific stuff
-
-# AWS User-specific
-
-# Generated files
-
-# Sensitive or high-churn files
-
-# Gradle
-
-# Gradle and Maven with auto-import
-# When using Gradle or Maven with auto-import, you should exclude module files,
-# since they will be recreated, and may cause churn. Uncomment if using
-# auto-import.
-# .idea/artifacts
-# .idea/compiler.xml
-# .idea/jarRepositories.xml
-# .idea/modules.xml
-# .idea/*.iml
-# .idea/modules
-# *.iml
-# *.ipr
-
-# CMake
-
-# Mongo Explorer plugin
-
-# File-based project format
-
-# IntelliJ
-
-# mpeltonen/sbt-idea plugin
-
-# JIRA plugin
-
-# Cursive Clojure plugin
-
-# SonarLint plugin
-
-# Crashlytics plugin (for Android Studio and IntelliJ)
-
-# Editor-based Rest Client
-
-# Android studio 3.1+ serialized cache file
-
-### PyCharm+all Patch ###
-# Ignore everything but code style settings and run configurations
-# that are supposed to be shared within teams.
-
-.idea/*
-
-!.idea/codeStyles
-!.idea/runConfigurations
-
-### PyCharm+iml ###
-# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
-# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
-
-# User-specific stuff
-
-# AWS User-specific
-
-# Generated files
-
-# Sensitive or high-churn files
-
-# Gradle
-
-# Gradle and Maven with auto-import
-# When using Gradle or Maven with auto-import, you should exclude module files,
-# since they will be recreated, and may cause churn. Uncomment if using
-# auto-import.
-# .idea/artifacts
-# .idea/compiler.xml
-# .idea/jarRepositories.xml
-# .idea/modules.xml
-# .idea/*.iml
-# .idea/modules
-# *.iml
-# *.ipr
-
-# CMake
-
-# Mongo Explorer plugin
-
-# File-based project format
-
-# IntelliJ
-
-# mpeltonen/sbt-idea plugin
-
-# JIRA plugin
-
-# Cursive Clojure plugin
-
-# SonarLint plugin
-
-# Crashlytics plugin (for Android Studio and IntelliJ)
-
-# Editor-based Rest Client
-
-# Android studio 3.1+ serialized cache file
-
-### PyCharm+iml Patch ###
-# Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-249601023
-
-*.iml
-modules.xml
-.idea/misc.xml
-*.ipr
-
-### pydev ###
-.pydevproject
-
-### Python ###
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-develop-eggs/
-downloads/
-eggs#memgpt/memgpt-server:0.3.7
-MANIFEST
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.nox/
-.coverage
-.coverage.*
-.cache
-nosetests.xml
-coverage.xml
-*.cover
-*.py,cover
-.hypothesis/
-.pytest_cache/
-cover/
-
-# Translations
-*.mo
-*.pot
-
-# Django stuff:
-*.log
-local_settings.py
-db.sqlite3
-db.sqlite3-journal
-
-# Flask stuff:
-instance/
-.webassets-cache
-
-# Scrapy stuff:
-.scrapy
-
-# Sphinx documentation
-docs/_build/
-
-# PyBuilder
-.pybuilder/
-target/
-
-# Jupyter Notebook
-
-# IPython
-
-# pyenv
-# For a library or package, you might want to ignore these files since the code is
-# intended to run in multiple environments; otherwise, check them in:
-# .python-version
-
-# pipenv
-# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
-# However, in case of collaboration, if having platform-specific dependencies or dependencies
-# having no cross-platform support, pipenv may install dependencies that don't work, or not
-# install all needed dependencies.
-#Pipfile.lock
-
-# poetry
-# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
-# This is especially recommended for binary packages to ensure reproducibility, and is more
-# commonly ignored for libraries.
-# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
-#poetry.lock
-
-# pdm
-# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
-#pdm.lock
-# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
-# in version control.
-# https://pdm.fming.dev/#use-with-ide
-.pdm.toml
-
-# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
-__pypackages__/
-
-# Celery stuff
-celerybeat-schedule
-celerybeat.pid
-
-# SageMath parsed files
-*.sage.py
-
-# Environments
-.env
-.venv
-env/
-venv/
-ENV/
-env.bak/
-venv.bak/
-
-# Spyder project settings
-.spyderproject
-.spyproject
-
-# Rope project settings
-.ropeproject
-
-# mkdocs documentation
-/site
-
-# mypy
-.mypy_cache/
-.dmypy.json
-dmypy.json
-
-# Pyre type checker
-.pyre/
-
-# pytype static type analyzer
-.pytype/
-
-# Cython debug symbols
-cython_debug/
-
-# PyCharm
-# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
-# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
-# and can be added to the global gitignore or merged into this file. For a more nuclear
-# option (not recommended) you can uncomment the following to ignore the entire idea folder.
-#.idea/
-
-### Python Patch ###
-# Poetry local configuration file - https://python-poetry.org/docs/configuration/#local-configuration
-poetry.toml
-
-# ruff
-.ruff_cache/
-
-# LSP config files
-pyrightconfig.json
-
-### Vim ###
-# Swap
-[._]*.s[a-v][a-z]
-!*.svg # comment out if you don't need vector files
-[._]*.sw[a-p]
-[._]s[a-rt-v][a-z]
-[._]ss[a-gi-z]
-[._]sw[a-p]
-
-# Session
-Session.vim
-Sessionx.vim
-
-# Temporary
-.netrwhist
-# Auto-generated tag files
-tags
-# Persistent undo
-[._]*.un~
-
-### VisualStudioCode ###
-.vscode/*
-!.vscode/settings.json
-!.vscode/tasks.json
-!.vscode/launch.json
-!.vscode/extensions.json
-!.vscode/*.code-snippets
-
-# Local History for Visual Studio Code
-.history/
-
-# Built Visual Studio Code Extensions
-*.vsix
-
-### VisualStudioCode Patch ###
-# Ignore all local history of files
-.history
-.ionide
-
-### Windows ###
-# Windows thumbnail cache files
-Thumbs.db
-Thumbs.db:encryptable
-ehthumbs.db
-ehthumbs_vista.db
-
-# Dump file
-*.stackdump
-
-# Folder config file
-[Dd]esktop.ini
-
-# Recycle Bin used on file shares
-$RECYCLE.BIN/
-
-# Windows Installer files
-*.cab
-*.msi
-*.msix
-*.msm
-*.msp
-
-# Windows shortcuts
-*.lnk
-
-### Xcode ###
-## User settings
-xcuserdata/
-
-## Xcode 8 and earlier
-*.xcscmblueprint
-*.xccheckout
-
-### Xcode Patch ###
-*.xcodeproj/*
-!*.xcodeproj/project.pbxproj
-!*.xcodeproj/xcshareddata/
-!*.xcodeproj/project.xcworkspace/
-!*.xcworkspace/contents.xcworkspacedata
-/*.gcno
-**/xcshareddata/WorkspaceSettings.xcsettings
-
-### XcodeInjection ###
-# Code Injection
-#
-# After new code Injection tools there's a generated folder /iOSInjectionProject
-# https://github.com/johnno1962/injectionforxcode
-
-iOSInjectionProject/
-
-### VisualStudio ###
-## Ignore Visual Studio temporary files, build results, and
-## files generated by popular Visual Studio add-ons.
-##
-## Get latest from https://github.com/github/gitignore/blob/main/VisualStudio.gitignore
-
-# User-specific files
-*.rsuser
-*.suo
-*.user
-*.userosscache
-*.sln.docstates
-
-# User-specific files (MonoDevelop/Xamarin Studio)
-*.userprefs
-
-# Mono auto generated files
-mono_crash.*
-
-# Build results
-[Dd]ebug/
-[Dd]ebugPublic/
-[Rr]elease/
-[Rr]eleases/
-x64/
-x86/
-[Ww][Ii][Nn]32/
-[Aa][Rr][Mm]/
-[Aa][Rr][Mm]64/
-bld/
-[Bb]in/
-[Oo]bj/
-[Ll]og/
-[Ll]ogs/
-
-# Visual Studio 2015/2017 cache/options directory
-.vs/
-# Uncomment if you have tasks that create the project's static files in wwwroot
-#wwwroot/
-
-# Visual Studio 2017 auto generated files
-Generated\ Files/
-
-# MSTest test Results
-[Tt]est[Rr]esult*/
-[Bb]uild[Ll]og.*
-
-# NUnit
-*.VisualState.xml
-TestResult.xml
-nunit-*.xml
-
-# Build Results of an ATL Project
-[Dd]ebugPS/
-[Rr]eleasePS/
-dlldata.c
-
-# Benchmark Results
-BenchmarkDotNet.Artifacts/
-
-# .NET Core
-project.lock.json
-project.fragment.lock.json
-artifacts/
-
-# ASP.NET Scaffolding
-ScaffoldingReadMe.txt
-
-# StyleCop
-StyleCopReport.xml
-
-# Files built by Visual Studio
-*_i.c
-*_p.c
-*_h.h
-*.ilk
-*.meta
-*.obj
-*.iobj
-*.pch
-*.pdb
-*.ipdb
-*.pgc
-*.pgd
-*.rsp
-*.sbr
-*.tlb
-*.tli
-*.tlh
-*.tmp_proj
-*_wpftmp.csproj
-*.tlog
-*.vspscc
-*.vssscc
-.builds
-*.pidb
-*.svclog
-*.scc
-
-# Chutzpah Test files
-_Chutzpah*
-
-# Visual C++ cache files
-ipch/
-*.aps
-*.ncb
-*.opendb
-*.opensdf
-*.sdf
-*.cachefile
-*.VC.db
-*.VC.VC.opendb
-
-# Visual Studio profiler
-*.psess
-*.vsp
-*.vspx
-*.sap
-
-# Visual Studio Trace Files
-*.e2e
-
-# TFS 2012 Local Workspace
-$tf/
-
-# Guidance Automation Toolkit
-*.gpState
-
-# ReSharper is a .NET coding add-in
-_ReSharper*/
-*.[Rr]e[Ss]harper
-*.DotSettings.user
-
-# TeamCity is a build add-in
-_TeamCity*
-
-# DotCover is a Code Coverage Tool
-*.dotCover
-
-# AxoCover is a Code Coverage Tool
-.axoCover/*
-!.axoCover/settings.json
-
-# Coverlet is a free, cross platform Code Coverage Tool
-coverage*.json
-coverage*.xml
-coverage*.info
-
-# Visual Studio code coverage results
-*.coverage
-*.coveragexml
-
-# NCrunch
-_NCrunch_*
-.*crunch*.local.xml
-nCrunchTemp_*
-
-# MightyMoose
-*.mm.*
-AutoTest.Net/
-
-# Web workbench (sass)
-.sass-cache/
-
-# Installshield output folder
-[Ee]xpress/
-
-# DocProject is a documentation generator add-in
-DocProject/buildhelp/
-DocProject/Help/*.HxT
-DocProject/Help/*.HxC
-DocProject/Help/*.hhc
-DocProject/Help/*.hhk
-DocProject/Help/*.hhp
-DocProject/Help/Html2
-DocProject/Help/html
-
-# Click-Once directory
-publish/
-
-# Publish Web Output
-*.[Pp]ublish.xml
-*.azurePubxml
-# Note: Comment the next line if you want to checkin your web deploy settings,
-# but database connection strings (with potential passwords) will be unencrypted
-*.pubxml
-*.publishproj
-
-# Microsoft Azure Web App publish settings. Comment the next line if you want to
-# checkin your Azure Web App publish settings, but sensitive information contained
-# in these scripts will be unencrypted
-PublishScripts/
-
-# NuGet Packages
-*.nupkg
-# NuGet Symbol Packages
-*.snupkg
-# The packages folder can be ignored because of Package Restore
-**/[Pp]ackages/*
-# except build/, which is used as an MSBuild target.
-!**/[Pp]ackages/build/
-# Uncomment if necessary however generally it will be regenerated when needed
-#!**/[Pp]ackages/repositories.config
-# NuGet v3's project.json files produces more ignorable files
-*.nuget.props
-*.nuget.targets
-
-# Microsoft Azure Build Output
-csx/
-*.build.csdef
-
-# Microsoft Azure Emulator
-ecf/
-rcf/
-
-# Windows Store app package directories and files
-AppPackages/
-BundleArtifacts/
-Package.StoreAssociation.xml
-_pkginfo.txt
-*.appx
-*.appxbundle
-*.appxupload
-
-# Visual Studio cache files
-# files ending in .cache can be ignored
-*.[Cc]ache
-# but keep track of directories ending in .cache
-!?*.[Cc]ache/
-
-# Others
-ClientBin/
-~$*
-*.dbmdl
-*.dbproj.schemaview
-*.jfm
-*.pfx
-*.publishsettings
-orleans.codegen.cs
-
-# Including strong name files can present a security risk
-# (https://github.com/github/gitignore/pull/2483#issue-259490424)
-#*.snk
-
-# Since there are multiple workflows, uncomment next line to ignore bower_components
-# (https://github.com/github/gitignore/pull/1529#issuecomment-104372622)
-#bower_components/
-
-# RIA/Silverlight projects
-Generated_Code/
-
-# Backup & report files from converting an old project file
-# to a newer Visual Studio version. Backup files are not needed,
-# because we have git ;-)
-_UpgradeReport_Files/
-Backup*/
-UpgradeLog*.XML
-UpgradeLog*.htm
-ServiceFabricBackup/
-*.rptproj.bak
-
-# SQL Server files
-*.mdf
-*.ldf
-*.ndf
-
-# Business Intelligence projects
-*.rdl.data
-*.bim.layout
-*.bim_*.settings
-*.rptproj.rsuser
-*- [Bb]ackup.rdl
-*- [Bb]ackup ([0-9]).rdl
-*- [Bb]ackup ([0-9][0-9]).rdl
-
-# Microsoft Fakes
-FakesAssemblies/
-
-# GhostDoc plugin setting file
-*.GhostDoc.xml
-
-# Node.js Tools for Visual Studio
-.ntvs_analysis.dat
-node_modules/
-
-# Visual Studio 6 build log
-*.plg
-
-# Visual Studio 6 workspace options file
-*.opt
-
-# Visual Studio 6 auto-generated workspace file (contains which files were open etc.)
-*.vbw
-
-# Visual Studio 6 auto-generated project file (contains which files were open etc.)
-*.vbp
-
-# Visual Studio 6 workspace and project file (working project files containing files to include in project)
-*.dsw
-*.dsp
-
-# Visual Studio 6 technical files
-
-# Visual Studio LightSwitch build output
-**/*.HTMLClient/GeneratedArtifacts
-**/*.DesktopClient/GeneratedArtifacts
-**/*.DesktopClient/ModelManifest.xml
-**/*.Server/GeneratedArtifacts
-**/*.Server/ModelManifest.xml
-_Pvt_Extensions
-
-# Paket dependency manager
-.paket/paket.exe
-paket-files/
-
-# FAKE - F# Make
-.fake/
-
-# CodeRush personal settings
-.cr/personal
-
-# Python Tools for Visual Studio (PTVS)
-*.pyc
-
-# Cake - Uncomment if you are using it
-# tools/**
-# !tools/packages.config
-
-# Tabs Studio
-*.tss
-
-# Telerik's JustMock configuration file
-*.jmconfig
-
-# BizTalk build output
-*.btp.cs
-*.btm.cs
-*.odx.cs
-*.xsd.cs
-
-# OpenCover UI analysis results
-OpenCover/
-
-# Azure Stream Analytics local run output
-ASALocalRun/
-
-# MSBuild Binary and Structured Log
-*.binlog
-
-# NVidia Nsight GPU debugger configuration file
-*.nvuser
-
-# MFractors (Xamarin productivity tool) working folder
-.mfractor/
-
-# Local History for Visual Studio
-.localhistory/
-
-# Visual Studio History (VSHistory) files
-.vshistory/
-
-# BeatPulse healthcheck temp database
-healthchecksdb
-
-# Backup folder for Package Reference Convert tool in Visual Studio 2017
-MigrationBackup/
-
-# Ionide (cross platform F# VS Code tools) working folder
-.ionide/
-
-# Fody - auto-generated XML schema
-FodyWeavers.xsd
-
-# VS Code files for those working on multiple tools
-*.code-workspace
-
-# Local History for Visual Studio Code
-
-# Windows Installer files from build outputs
-
-# JetBrains Rider
-*.sln.iml
-
-### VisualStudio Patch ###
-# Additional files built by Visual Studio
-
-# End of https://www.toptal.com/developers/gitignore/api/vim,linux,macos,pydev,python,eclipse,pycharm,windows,netbeans,pycharm+all,pycharm+iml,visualstudio,jupyternotebooks,visualstudiocode,xcode,xcodeinjection
-
-
-## cached db data
-pgdata/
-!pgdata/.gitkeep
-
-## pytest mirrors
-memgpt/.pytest_cache/
-memgpy/pytest.ini
-**/**/pytest_cache
+# MemGPT config files
+configs/
+
+# Below are generated by gitignor.io (toptal)
+# Created by https://www.toptal.com/developers/gitignore/api/vim,linux,macos,pydev,python,eclipse,pycharm,windows,netbeans,pycharm+all,pycharm+iml,visualstudio,jupyternotebooks,visualstudiocode,xcode,xcodeinjection
+# Edit at https://www.toptal.com/developers/gitignore?templates=vim,linux,macos,pydev,python,eclipse,pycharm,windows,netbeans,pycharm+all,pycharm+iml,visualstudio,jupyternotebooks,visualstudiocode,xcode,xcodeinjection
+
+### Eclipse ###
+.metadata
+bin/
+tmp/
+*.tmp
+*.bak
+*.swp
+*~.nib
+local.properties
+.settings/
+.loadpath
+.recommenders
+
+# External tool builders
+.externalToolBuilders/
+
+# Locally stored "Eclipse launch configurations"
+*.launch
+
+# PyDev specific (Python IDE for Eclipse)
+*.pydevproject
+
+# CDT-specific (C/C++ Development Tooling)
+.cproject
+
+# CDT- autotools
+.autotools
+
+# Java annotation processor (APT)
+.factorypath
+
+# PDT-specific (PHP Development Tools)
+.buildpath
+
+# sbteclipse plugin
+.target
+
+# Tern plugin
+.tern-project
+
+# TeXlipse plugin
+.texlipse
+
+# STS (Spring Tool Suite)
+.springBeans
+
+# Code Recommenders
+.recommenders/
+
+# Annotation Processing
+.apt_generated/
+.apt_generated_test/
+
+# Scala IDE specific (Scala & Java development for Eclipse)
+.cache-main
+.scala_dependencies
+.worksheet
+
+# Uncomment this line if you wish to ignore the project description file.
+# Typically, this file would be tracked if it contains build/dependency configurations:
+#.project
+
+### Eclipse Patch ###
+# Spring Boot Tooling
+.sts4-cache/
+
+### JupyterNotebooks ###
+# gitignore template for Jupyter Notebooks
+# website: http://jupyter.org/
+
+.ipynb_checkpoints
+*/.ipynb_checkpoints/*
+
+# IPython
+profile_default/
+ipython_config.py
+
+# Remove previous ipynb_checkpoints
+# git rm -r .ipynb_checkpoints/
+
+### Linux ###
+*~
+
+# temporary files which can be created if a process still has a handle open of a deleted file
+.fuse_hidden*
+
+# KDE directory preferences
+.directory
+
+# Linux trash folder which might appear on any partition or disk
+.Trash-*
+
+# .nfs files are created when an open file is removed but is still being accessed
+.nfs*
+
+### macOS ###
+# General
+.DS_Store
+.AppleDouble
+.LSOverride
+
+# Icon must end with two \r
+Icon
+
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+.com.apple.timemachine.donotpresent
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+### macOS Patch ###
+# iCloud generated files
+*.icloud
+
+### NetBeans ###
+**/nbproject/private/
+**/nbproject/Makefile-*.mk
+**/nbproject/Package-*.bash
+build/
+nbbuild/
+dist/
+nbdist/
+.nb-gradle/
+
+### PyCharm ###
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff
+.idea/**/workspace.xml
+.idea/**/tasks.xml
+.idea/**/usage.statistics.xml
+.idea/**/dictionaries
+.idea/**/shelf
+
+# AWS User-specific
+.idea/**/aws.xml
+
+# Generated files
+.idea/**/contentModel.xml
+
+# Sensitive or high-churn files
+.idea/**/dataSources/
+.idea/**/dataSources.ids
+.idea/**/dataSources.local.xml
+.idea/**/sqlDataSources.xml
+.idea/**/dynamic.xml
+.idea/**/uiDesigner.xml
+.idea/**/dbnavigator.xml
+
+# Gradle
+.idea/**/gradle.xml
+.idea/**/libraries
+
+# Gradle and Maven with auto-import
+# When using Gradle or Maven with auto-import, you should exclude module files,
+# since they will be recreated, and may cause churn. Uncomment if using
+# auto-import.
+# .idea/artifacts
+# .idea/compiler.xml
+# .idea/jarRepositories.xml
+# .idea/modules.xml
+# .idea/*.iml
+# .idea/modules
+# *.iml
+# *.ipr
+
+# CMake
+cmake-build-*/
+
+# Mongo Explorer plugin
+.idea/**/mongoSettings.xml
+
+# File-based project format
+*.iws
+
+# IntelliJ
+out/
+
+# mpeltonen/sbt-idea plugin
+.idea_modules/
+
+# JIRA plugin
+atlassian-ide-plugin.xml
+
+# Cursive Clojure plugin
+.idea/replstate.xml
+
+# SonarLint plugin
+.idea/sonarlint/
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+com_crashlytics_export_strings.xml
+crashlytics.properties
+crashlytics-build.properties
+fabric.properties
+
+# Editor-based Rest Client
+.idea/httpRequests
+
+# Android studio 3.1+ serialized cache file
+.idea/caches/build_file_checksums.ser
+
+### PyCharm Patch ###
+# Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
+
+# *.iml
+# modules.xml
+# .idea/misc.xml
+# *.ipr
+
+# Sonarlint plugin
+# https://plugins.jetbrains.com/plugin/7973-sonarlint
+.idea/**/sonarlint/
+
+# SonarQube Plugin
+# https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
+.idea/**/sonarIssues.xml
+
+# Markdown Navigator plugin
+# https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
+.idea/**/markdown-navigator.xml
+.idea/**/markdown-navigator-enh.xml
+.idea/**/markdown-navigator/
+
+# Cache file creation bug
+# See https://youtrack.jetbrains.com/issue/JBR-2257
+.idea/$CACHE_FILE$
+
+# CodeStream plugin
+# https://plugins.jetbrains.com/plugin/12206-codestream
+.idea/codestream.xml
+
+# Azure Toolkit for IntelliJ plugin
+# https://plugins.jetbrains.com/plugin/8053-azure-toolkit-for-intellij
+.idea/**/azureSettings.xml
+
+### PyCharm+all ###
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff
+
+# AWS User-specific
+
+# Generated files
+
+# Sensitive or high-churn files
+
+# Gradle
+
+# Gradle and Maven with auto-import
+# When using Gradle or Maven with auto-import, you should exclude module files,
+# since they will be recreated, and may cause churn. Uncomment if using
+# auto-import.
+# .idea/artifacts
+# .idea/compiler.xml
+# .idea/jarRepositories.xml
+# .idea/modules.xml
+# .idea/*.iml
+# .idea/modules
+# *.iml
+# *.ipr
+
+# CMake
+
+# Mongo Explorer plugin
+
+# File-based project format
+
+# IntelliJ
+
+# mpeltonen/sbt-idea plugin
+
+# JIRA plugin
+
+# Cursive Clojure plugin
+
+# SonarLint plugin
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+
+# Editor-based Rest Client
+
+# Android studio 3.1+ serialized cache file
+
+### PyCharm+all Patch ###
+# Ignore everything but code style settings and run configurations
+# that are supposed to be shared within teams.
+
+.idea/*
+
+!.idea/codeStyles
+!.idea/runConfigurations
+
+### PyCharm+iml ###
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff
+
+# AWS User-specific
+
+# Generated files
+
+# Sensitive or high-churn files
+
+# Gradle
+
+# Gradle and Maven with auto-import
+# When using Gradle or Maven with auto-import, you should exclude module files,
+# since they will be recreated, and may cause churn. Uncomment if using
+# auto-import.
+# .idea/artifacts
+# .idea/compiler.xml
+# .idea/jarRepositories.xml
+# .idea/modules.xml
+# .idea/*.iml
+# .idea/modules
+# *.iml
+# *.ipr
+
+# CMake
+
+# Mongo Explorer plugin
+
+# File-based project format
+
+# IntelliJ
+
+# mpeltonen/sbt-idea plugin
+
+# JIRA plugin
+
+# Cursive Clojure plugin
+
+# SonarLint plugin
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+
+# Editor-based Rest Client
+
+# Android studio 3.1+ serialized cache file
+
+### PyCharm+iml Patch ###
+# Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-249601023
+
+*.iml
+modules.xml
+.idea/misc.xml
+*.ipr
+
+### pydev ###
+.pydevproject
+
+### Python ###
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+develop-eggs/
+downloads/
+eggs#memgpt/memgpt-server:0.3.7
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+cover/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+.pybuilder/
+target/
+
+# Jupyter Notebook
+
+# IPython
+
+# pyenv
+# For a library or package, you might want to ignore these files since the code is
+# intended to run in multiple environments; otherwise, check them in:
+# .python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# poetry
+# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
+# This is especially recommended for binary packages to ensure reproducibility, and is more
+# commonly ignored for libraries.
+# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
+#poetry.lock
+
+# pdm
+# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
+#pdm.lock
+# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
+# in version control.
+# https://pdm.fming.dev/#use-with-ide
+.pdm.toml
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# pytype static type analyzer
+.pytype/
+
+# Cython debug symbols
+cython_debug/
+
+# PyCharm
+# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
+# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
+# and can be added to the global gitignore or merged into this file. For a more nuclear
+# option (not recommended) you can uncomment the following to ignore the entire idea folder.
+#.idea/
+
+### Python Patch ###
+# Poetry local configuration file - https://python-poetry.org/docs/configuration/#local-configuration
+poetry.toml
+
+# ruff
+.ruff_cache/
+
+# LSP config files
+pyrightconfig.json
+
+### Vim ###
+# Swap
+[._]*.s[a-v][a-z]
+!*.svg # comment out if you don't need vector files
+[._]*.sw[a-p]
+[._]s[a-rt-v][a-z]
+[._]ss[a-gi-z]
+[._]sw[a-p]
+
+# Session
+Session.vim
+Sessionx.vim
+
+# Temporary
+.netrwhist
+# Auto-generated tag files
+tags
+# Persistent undo
+[._]*.un~
+
+### VisualStudioCode ###
+.vscode/*
+!.vscode/settings.json
+!.vscode/tasks.json
+!.vscode/launch.json
+!.vscode/extensions.json
+!.vscode/*.code-snippets
+
+# Local History for Visual Studio Code
+.history/
+
+# Built Visual Studio Code Extensions
+*.vsix
+
+### VisualStudioCode Patch ###
+# Ignore all local history of files
+.history
+.ionide
+
+### Windows ###
+# Windows thumbnail cache files
+Thumbs.db
+Thumbs.db:encryptable
+ehthumbs.db
+ehthumbs_vista.db
+
+# Dump file
+*.stackdump
+
+# Folder config file
+[Dd]esktop.ini
+
+# Recycle Bin used on file shares
+$RECYCLE.BIN/
+
+# Windows Installer files
+*.cab
+*.msi
+*.msix
+*.msm
+*.msp
+
+# Windows shortcuts
+*.lnk
+
+### Xcode ###
+## User settings
+xcuserdata/
+
+## Xcode 8 and earlier
+*.xcscmblueprint
+*.xccheckout
+
+### Xcode Patch ###
+*.xcodeproj/*
+!*.xcodeproj/project.pbxproj
+!*.xcodeproj/xcshareddata/
+!*.xcodeproj/project.xcworkspace/
+!*.xcworkspace/contents.xcworkspacedata
+/*.gcno
+**/xcshareddata/WorkspaceSettings.xcsettings
+
+### XcodeInjection ###
+# Code Injection
+#
+# After new code Injection tools there's a generated folder /iOSInjectionProject
+# https://github.com/johnno1962/injectionforxcode
+
+iOSInjectionProject/
+
+### VisualStudio ###
+## Ignore Visual Studio temporary files, build results, and
+## files generated by popular Visual Studio add-ons.
+##
+## Get latest from https://github.com/github/gitignore/blob/main/VisualStudio.gitignore
+
+# User-specific files
+*.rsuser
+*.suo
+*.user
+*.userosscache
+*.sln.docstates
+
+# User-specific files (MonoDevelop/Xamarin Studio)
+*.userprefs
+
+# Mono auto generated files
+mono_crash.*
+
+# Build results
+[Dd]ebug/
+[Dd]ebugPublic/
+[Rr]elease/
+[Rr]eleases/
+x64/
+x86/
+[Ww][Ii][Nn]32/
+[Aa][Rr][Mm]/
+[Aa][Rr][Mm]64/
+bld/
+[Bb]in/
+[Oo]bj/
+[Ll]og/
+[Ll]ogs/
+
+# Visual Studio 2015/2017 cache/options directory
+.vs/
+# Uncomment if you have tasks that create the project's static files in wwwroot
+#wwwroot/
+
+# Visual Studio 2017 auto generated files
+Generated\ Files/
+
+# MSTest test Results
+[Tt]est[Rr]esult*/
+[Bb]uild[Ll]og.*
+
+# NUnit
+*.VisualState.xml
+TestResult.xml
+nunit-*.xml
+
+# Build Results of an ATL Project
+[Dd]ebugPS/
+[Rr]eleasePS/
+dlldata.c
+
+# Benchmark Results
+BenchmarkDotNet.Artifacts/
+
+# .NET Core
+project.lock.json
+project.fragment.lock.json
+artifacts/
+
+# ASP.NET Scaffolding
+ScaffoldingReadMe.txt
+
+# StyleCop
+StyleCopReport.xml
+
+# Files built by Visual Studio
+*_i.c
+*_p.c
+*_h.h
+*.ilk
+*.meta
+*.obj
+*.iobj
+*.pch
+*.pdb
+*.ipdb
+*.pgc
+*.pgd
+*.rsp
+*.sbr
+*.tlb
+*.tli
+*.tlh
+*.tmp_proj
+*_wpftmp.csproj
+*.tlog
+*.vspscc
+*.vssscc
+.builds
+*.pidb
+*.svclog
+*.scc
+
+# Chutzpah Test files
+_Chutzpah*
+
+# Visual C++ cache files
+ipch/
+*.aps
+*.ncb
+*.opendb
+*.opensdf
+*.sdf
+*.cachefile
+*.VC.db
+*.VC.VC.opendb
+
+# Visual Studio profiler
+*.psess
+*.vsp
+*.vspx
+*.sap
+
+# Visual Studio Trace Files
+*.e2e
+
+# TFS 2012 Local Workspace
+$tf/
+
+# Guidance Automation Toolkit
+*.gpState
+
+# ReSharper is a .NET coding add-in
+_ReSharper*/
+*.[Rr]e[Ss]harper
+*.DotSettings.user
+
+# TeamCity is a build add-in
+_TeamCity*
+
+# DotCover is a Code Coverage Tool
+*.dotCover
+
+# AxoCover is a Code Coverage Tool
+.axoCover/*
+!.axoCover/settings.json
+
+# Coverlet is a free, cross platform Code Coverage Tool
+coverage*.json
+coverage*.xml
+coverage*.info
+
+# Visual Studio code coverage results
+*.coverage
+*.coveragexml
+
+# NCrunch
+_NCrunch_*
+.*crunch*.local.xml
+nCrunchTemp_*
+
+# MightyMoose
+*.mm.*
+AutoTest.Net/
+
+# Web workbench (sass)
+.sass-cache/
+
+# Installshield output folder
+[Ee]xpress/
+
+# DocProject is a documentation generator add-in
+DocProject/buildhelp/
+DocProject/Help/*.HxT
+DocProject/Help/*.HxC
+DocProject/Help/*.hhc
+DocProject/Help/*.hhk
+DocProject/Help/*.hhp
+DocProject/Help/Html2
+DocProject/Help/html
+
+# Click-Once directory
+publish/
+
+# Publish Web Output
+*.[Pp]ublish.xml
+*.azurePubxml
+# Note: Comment the next line if you want to checkin your web deploy settings,
+# but database connection strings (with potential passwords) will be unencrypted
+*.pubxml
+*.publishproj
+
+# Microsoft Azure Web App publish settings. Comment the next line if you want to
+# checkin your Azure Web App publish settings, but sensitive information contained
+# in these scripts will be unencrypted
+PublishScripts/
+
+# NuGet Packages
+*.nupkg
+# NuGet Symbol Packages
+*.snupkg
+# The packages folder can be ignored because of Package Restore
+**/[Pp]ackages/*
+# except build/, which is used as an MSBuild target.
+!**/[Pp]ackages/build/
+# Uncomment if necessary however generally it will be regenerated when needed
+#!**/[Pp]ackages/repositories.config
+# NuGet v3's project.json files produces more ignorable files
+*.nuget.props
+*.nuget.targets
+
+# Microsoft Azure Build Output
+csx/
+*.build.csdef
+
+# Microsoft Azure Emulator
+ecf/
+rcf/
+
+# Windows Store app package directories and files
+AppPackages/
+BundleArtifacts/
+Package.StoreAssociation.xml
+_pkginfo.txt
+*.appx
+*.appxbundle
+*.appxupload
+
+# Visual Studio cache files
+# files ending in .cache can be ignored
+*.[Cc]ache
+# but keep track of directories ending in .cache
+!?*.[Cc]ache/
+
+# Others
+ClientBin/
+~$*
+*.dbmdl
+*.dbproj.schemaview
+*.jfm
+*.pfx
+*.publishsettings
+orleans.codegen.cs
+
+# Including strong name files can present a security risk
+# (https://github.com/github/gitignore/pull/2483#issue-259490424)
+#*.snk
+
+# Since there are multiple workflows, uncomment next line to ignore bower_components
+# (https://github.com/github/gitignore/pull/1529#issuecomment-104372622)
+#bower_components/
+
+# RIA/Silverlight projects
+Generated_Code/
+
+# Backup & report files from converting an old project file
+# to a newer Visual Studio version. Backup files are not needed,
+# because we have git ;-)
+_UpgradeReport_Files/
+Backup*/
+UpgradeLog*.XML
+UpgradeLog*.htm
+ServiceFabricBackup/
+*.rptproj.bak
+
+# SQL Server files
+*.mdf
+*.ldf
+*.ndf
+
+# Business Intelligence projects
+*.rdl.data
+*.bim.layout
+*.bim_*.settings
+*.rptproj.rsuser
+*- [Bb]ackup.rdl
+*- [Bb]ackup ([0-9]).rdl
+*- [Bb]ackup ([0-9][0-9]).rdl
+
+# Microsoft Fakes
+FakesAssemblies/
+
+# GhostDoc plugin setting file
+*.GhostDoc.xml
+
+# Node.js Tools for Visual Studio
+.ntvs_analysis.dat
+node_modules/
+
+# Visual Studio 6 build log
+*.plg
+
+# Visual Studio 6 workspace options file
+*.opt
+
+# Visual Studio 6 auto-generated workspace file (contains which files were open etc.)
+*.vbw
+
+# Visual Studio 6 auto-generated project file (contains which files were open etc.)
+*.vbp
+
+# Visual Studio 6 workspace and project file (working project files containing files to include in project)
+*.dsw
+*.dsp
+
+# Visual Studio 6 technical files
+
+# Visual Studio LightSwitch build output
+**/*.HTMLClient/GeneratedArtifacts
+**/*.DesktopClient/GeneratedArtifacts
+**/*.DesktopClient/ModelManifest.xml
+**/*.Server/GeneratedArtifacts
+**/*.Server/ModelManifest.xml
+_Pvt_Extensions
+
+# Paket dependency manager
+.paket/paket.exe
+paket-files/
+
+# FAKE - F# Make
+.fake/
+
+# CodeRush personal settings
+.cr/personal
+
+# Python Tools for Visual Studio (PTVS)
+*.pyc
+
+# Cake - Uncomment if you are using it
+# tools/**
+# !tools/packages.config
+
+# Tabs Studio
+*.tss
+
+# Telerik's JustMock configuration file
+*.jmconfig
+
+# BizTalk build output
+*.btp.cs
+*.btm.cs
+*.odx.cs
+*.xsd.cs
+
+# OpenCover UI analysis results
+OpenCover/
+
+# Azure Stream Analytics local run output
+ASALocalRun/
+
+# MSBuild Binary and Structured Log
+*.binlog
+
+# NVidia Nsight GPU debugger configuration file
+*.nvuser
+
+# MFractors (Xamarin productivity tool) working folder
+.mfractor/
+
+# Local History for Visual Studio
+.localhistory/
+
+# Visual Studio History (VSHistory) files
+.vshistory/
+
+# BeatPulse healthcheck temp database
+healthchecksdb
+
+# Backup folder for Package Reference Convert tool in Visual Studio 2017
+MigrationBackup/
+
+# Ionide (cross platform F# VS Code tools) working folder
+.ionide/
+
+# Fody - auto-generated XML schema
+FodyWeavers.xsd
+
+# VS Code files for those working on multiple tools
+*.code-workspace
+
+# Local History for Visual Studio Code
+
+# Windows Installer files from build outputs
+
+# JetBrains Rider
+*.sln.iml
+
+### VisualStudio Patch ###
+# Additional files built by Visual Studio
+
+# End of https://www.toptal.com/developers/gitignore/api/vim,linux,macos,pydev,python,eclipse,pycharm,windows,netbeans,pycharm+all,pycharm+iml,visualstudio,jupyternotebooks,visualstudiocode,xcode,xcodeinjection
+
+
+## cached db data
+pgdata/
+!pgdata/.gitkeep
+
+## pytest mirrors
+memgpt/.pytest_cache/
+memgpy/pytest.ini
+**/**/pytest_cache
diff --git a/README.md b/README.md
index fad4cd46..3f519108 100644
--- a/README.md
+++ b/README.md
@@ -1,106 +1,106 @@
-
-  -
-
-
-
-
- MemGPT allows you to build LLM agents with long term memory & custom tools
-
-[](https://discord.gg/9GEQrxmVyE)
-[](https://twitter.com/MemGPT)
-[](https://arxiv.org/abs/2310.08560)
-[](https://memgpt.readme.io/docs)
-
-
-
-MemGPT makes it easy to build and deploy stateful LLM agents with support for:
-* Long term memory/state management
-* Connections to [external data sources](https://memgpt.readme.io/docs/data_sources) (e.g. PDF files) for RAG
-* Defining and calling [custom tools](https://memgpt.readme.io/docs/functions) (e.g. [google search](https://github.com/cpacker/MemGPT/blob/main/examples/google_search.py))
-
-You can also use MemGPT to deploy agents as a *service*. You can use a MemGPT server to run a multi-user, multi-agent application on top of supported LLM providers.
-
- -
-
-## Installation & Setup
-Install MemGPT:
-```sh
-pip install -U pymemgpt
-```
-
-To use MemGPT with OpenAI, set the environment variable `OPENAI_API_KEY` to your OpenAI key then run:
-```
-memgpt quickstart --backend openai
-```
-To use MemGPT with a free hosted endpoint, you run run:
-```
-memgpt quickstart --backend memgpt
-```
-For more advanced configuration options or to use a different [LLM backend](https://memgpt.readme.io/docs/endpoints) or [local LLMs](https://memgpt.readme.io/docs/local_llm), run `memgpt configure`.
-
-## Quickstart (CLI)
-You can create and chat with a MemGPT agent by running `memgpt run` in your CLI. The `run` command supports the following optional flags (see the [CLI documentation](https://memgpt.readme.io/docs/quickstart) for the full list of flags):
-* `--agent`: (str) Name of agent to create or to resume chatting with.
-* `--first`: (str) Allow user to sent the first message.
-* `--debug`: (bool) Show debug logs (default=False)
-* `--no-verify`: (bool) Bypass message verification (default=False)
-* `--yes`/`-y`: (bool) Skip confirmation prompt and use defaults (default=False)
-
-You can view the list of available in-chat commands (e.g. `/memory`, `/exit`) in the [CLI documentation](https://memgpt.readme.io/docs/quickstart).
-
-## Dev portal (alpha build)
-MemGPT provides a developer portal that enables you to easily create, edit, monitor, and chat with your MemGPT agents. The easiest way to use the dev portal is to install MemGPT via **docker** (see instructions below).
-
-
-
-
-## Installation & Setup
-Install MemGPT:
-```sh
-pip install -U pymemgpt
-```
-
-To use MemGPT with OpenAI, set the environment variable `OPENAI_API_KEY` to your OpenAI key then run:
-```
-memgpt quickstart --backend openai
-```
-To use MemGPT with a free hosted endpoint, you run run:
-```
-memgpt quickstart --backend memgpt
-```
-For more advanced configuration options or to use a different [LLM backend](https://memgpt.readme.io/docs/endpoints) or [local LLMs](https://memgpt.readme.io/docs/local_llm), run `memgpt configure`.
-
-## Quickstart (CLI)
-You can create and chat with a MemGPT agent by running `memgpt run` in your CLI. The `run` command supports the following optional flags (see the [CLI documentation](https://memgpt.readme.io/docs/quickstart) for the full list of flags):
-* `--agent`: (str) Name of agent to create or to resume chatting with.
-* `--first`: (str) Allow user to sent the first message.
-* `--debug`: (bool) Show debug logs (default=False)
-* `--no-verify`: (bool) Bypass message verification (default=False)
-* `--yes`/`-y`: (bool) Skip confirmation prompt and use defaults (default=False)
-
-You can view the list of available in-chat commands (e.g. `/memory`, `/exit`) in the [CLI documentation](https://memgpt.readme.io/docs/quickstart).
-
-## Dev portal (alpha build)
-MemGPT provides a developer portal that enables you to easily create, edit, monitor, and chat with your MemGPT agents. The easiest way to use the dev portal is to install MemGPT via **docker** (see instructions below).
-
- -
-## Quickstart (Server)
-
-**Option 1 (Recommended)**: Run with docker compose
-1. [Install docker on your system](https://docs.docker.com/get-docker/)
-2. Clone the repo: `git clone https://github.com/cpacker/MemGPT.git`
-3. Copy-paste `.env.example` to `.env` and optionally modify
-4. Run `docker compose up`
-5. Go to `memgpt.localhost` in the browser to view the developer portal
-
-**Option 2:** Run with the CLI:
-1. Run `memgpt server`
-2. Go to `localhost:8283` in the browser to view the developer portal
-
-Once the server is running, you can use the [Python client](https://memgpt.readme.io/docs/admin-client) or [REST API](https://memgpt.readme.io/reference/api) to connect to `memgpt.localhost` (if you're running with docker compose) or `localhost:8283` (if you're running with the CLI) to create users, agents, and more. The service requires authentication with a MemGPT admin password; it is the value of `MEMGPT_SERVER_PASS` in `.env`.
-
-## Supported Endpoints & Backends
-MemGPT is designed to be model and provider agnostic. The following LLM and embedding endpoints are supported:
-
-| Provider | LLM Endpoint | Embedding Endpoint |
-|---------------------|-----------------|--------------------|
-| OpenAI | ✅ | ✅ |
-| Azure OpenAI | ✅ | ✅ |
-| Google AI (Gemini) | ✅ | ❌ |
-| Anthropic (Claude) | ✅ | ❌ |
-| Groq | ✅ (alpha release) | ❌ |
-| Cohere API | ✅ | ❌ |
-| vLLM | ✅ | ❌ |
-| Ollama | ✅ | ✅ |
-| LM Studio | ✅ | ❌ |
-| koboldcpp | ✅ | ❌ |
-| oobabooga web UI | ✅ | ❌ |
-| llama.cpp | ✅ | ❌ |
-| HuggingFace TEI | ❌ | ✅ |
-
-When using MemGPT with open LLMs (such as those downloaded from HuggingFace), the performance of MemGPT will be highly dependent on the LLM's function calling ability. You can find a list of LLMs/models that are known to work well with MemGPT on the [#model-chat channel on Discord](https://discord.gg/9GEQrxmVyE), as well as on [this spreadsheet](https://docs.google.com/spreadsheets/d/1fH-FdaO8BltTMa4kXiNCxmBCQ46PRBVp3Vn6WbPgsFs/edit?usp=sharing).
-
-## How to Get Involved
-* **Contribute to the Project**: Interested in contributing? Start by reading our [Contribution Guidelines](https://github.com/cpacker/MemGPT/tree/main/CONTRIBUTING.md).
-* **Ask a Question**: Join our community on [Discord](https://discord.gg/9GEQrxmVyE) and direct your questions to the `#support` channel.
-* **Report Issues or Suggest Features**: Have an issue or a feature request? Please submit them through our [GitHub Issues page](https://github.com/cpacker/MemGPT/issues).
-* **Explore the Roadmap**: Curious about future developments? View and comment on our [project roadmap](https://github.com/cpacker/MemGPT/issues/1200).
-* **Benchmark the Performance**: Want to benchmark the performance of a model on MemGPT? Follow our [Benchmarking Guidance](#benchmarking-guidance).
-* **Join Community Events**: Stay updated with the [MemGPT event calendar](https://lu.ma/berkeley-llm-meetup) or follow our [Twitter account](https://twitter.com/MemGPT).
-
-
-## Benchmarking Guidance
-To evaluate the performance of a model on MemGPT, simply configure the appropriate model settings using `memgpt configure`, and then initiate the benchmark via `memgpt benchmark`. The duration will vary depending on your hardware. This will run through a predefined set of prompts through multiple iterations to test the function calling capabilities of a model. You can help track what LLMs work well with MemGPT by contributing your benchmark results via [this form](https://forms.gle/XiBGKEEPFFLNSR348), which will be used to update the spreadsheet.
-
-## Legal notices
-By using MemGPT and related MemGPT services (such as the MemGPT endpoint or hosted service), you agree to our [privacy policy](https://github.com/cpacker/MemGPT/tree/main/PRIVACY.md) and [terms of service](https://github.com/cpacker/MemGPT/tree/main/TERMS.md).
+
-
-## Quickstart (Server)
-
-**Option 1 (Recommended)**: Run with docker compose
-1. [Install docker on your system](https://docs.docker.com/get-docker/)
-2. Clone the repo: `git clone https://github.com/cpacker/MemGPT.git`
-3. Copy-paste `.env.example` to `.env` and optionally modify
-4. Run `docker compose up`
-5. Go to `memgpt.localhost` in the browser to view the developer portal
-
-**Option 2:** Run with the CLI:
-1. Run `memgpt server`
-2. Go to `localhost:8283` in the browser to view the developer portal
-
-Once the server is running, you can use the [Python client](https://memgpt.readme.io/docs/admin-client) or [REST API](https://memgpt.readme.io/reference/api) to connect to `memgpt.localhost` (if you're running with docker compose) or `localhost:8283` (if you're running with the CLI) to create users, agents, and more. The service requires authentication with a MemGPT admin password; it is the value of `MEMGPT_SERVER_PASS` in `.env`.
-
-## Supported Endpoints & Backends
-MemGPT is designed to be model and provider agnostic. The following LLM and embedding endpoints are supported:
-
-| Provider | LLM Endpoint | Embedding Endpoint |
-|---------------------|-----------------|--------------------|
-| OpenAI | ✅ | ✅ |
-| Azure OpenAI | ✅ | ✅ |
-| Google AI (Gemini) | ✅ | ❌ |
-| Anthropic (Claude) | ✅ | ❌ |
-| Groq | ✅ (alpha release) | ❌ |
-| Cohere API | ✅ | ❌ |
-| vLLM | ✅ | ❌ |
-| Ollama | ✅ | ✅ |
-| LM Studio | ✅ | ❌ |
-| koboldcpp | ✅ | ❌ |
-| oobabooga web UI | ✅ | ❌ |
-| llama.cpp | ✅ | ❌ |
-| HuggingFace TEI | ❌ | ✅ |
-
-When using MemGPT with open LLMs (such as those downloaded from HuggingFace), the performance of MemGPT will be highly dependent on the LLM's function calling ability. You can find a list of LLMs/models that are known to work well with MemGPT on the [#model-chat channel on Discord](https://discord.gg/9GEQrxmVyE), as well as on [this spreadsheet](https://docs.google.com/spreadsheets/d/1fH-FdaO8BltTMa4kXiNCxmBCQ46PRBVp3Vn6WbPgsFs/edit?usp=sharing).
-
-## How to Get Involved
-* **Contribute to the Project**: Interested in contributing? Start by reading our [Contribution Guidelines](https://github.com/cpacker/MemGPT/tree/main/CONTRIBUTING.md).
-* **Ask a Question**: Join our community on [Discord](https://discord.gg/9GEQrxmVyE) and direct your questions to the `#support` channel.
-* **Report Issues or Suggest Features**: Have an issue or a feature request? Please submit them through our [GitHub Issues page](https://github.com/cpacker/MemGPT/issues).
-* **Explore the Roadmap**: Curious about future developments? View and comment on our [project roadmap](https://github.com/cpacker/MemGPT/issues/1200).
-* **Benchmark the Performance**: Want to benchmark the performance of a model on MemGPT? Follow our [Benchmarking Guidance](#benchmarking-guidance).
-* **Join Community Events**: Stay updated with the [MemGPT event calendar](https://lu.ma/berkeley-llm-meetup) or follow our [Twitter account](https://twitter.com/MemGPT).
-
-
-## Benchmarking Guidance
-To evaluate the performance of a model on MemGPT, simply configure the appropriate model settings using `memgpt configure`, and then initiate the benchmark via `memgpt benchmark`. The duration will vary depending on your hardware. This will run through a predefined set of prompts through multiple iterations to test the function calling capabilities of a model. You can help track what LLMs work well with MemGPT by contributing your benchmark results via [this form](https://forms.gle/XiBGKEEPFFLNSR348), which will be used to update the spreadsheet.
-
-## Legal notices
-By using MemGPT and related MemGPT services (such as the MemGPT endpoint or hosted service), you agree to our [privacy policy](https://github.com/cpacker/MemGPT/tree/main/PRIVACY.md) and [terms of service](https://github.com/cpacker/MemGPT/tree/main/TERMS.md).
+
+
+
+
+
+
+ MemGPT allows you to build LLM agents with long term memory & custom tools
+
+[](https://discord.gg/9GEQrxmVyE)
+[](https://twitter.com/MemGPT)
+[](https://arxiv.org/abs/2310.08560)
+[](https://memgpt.readme.io/docs)
+
+
+
+MemGPT makes it easy to build and deploy stateful LLM agents with support for:
+* Long term memory/state management
+* Connections to [external data sources](https://memgpt.readme.io/docs/data_sources) (e.g. PDF files) for RAG
+* Defining and calling [custom tools](https://memgpt.readme.io/docs/functions) (e.g. [google search](https://github.com/cpacker/MemGPT/blob/main/examples/google_search.py))
+
+You can also use MemGPT to deploy agents as a *service*. You can use a MemGPT server to run a multi-user, multi-agent application on top of supported LLM providers.
+
+
+
+
+## Installation & Setup
+Install MemGPT:
+```sh
+pip install -U pymemgpt
+```
+
+To use MemGPT with OpenAI, set the environment variable `OPENAI_API_KEY` to your OpenAI key then run:
+```
+memgpt quickstart --backend openai
+```
+To use MemGPT with a free hosted endpoint, you run run:
+```
+memgpt quickstart --backend memgpt
+```
+For more advanced configuration options or to use a different [LLM backend](https://memgpt.readme.io/docs/endpoints) or [local LLMs](https://memgpt.readme.io/docs/local_llm), run `memgpt configure`.
+
+## Quickstart (CLI)
+You can create and chat with a MemGPT agent by running `memgpt run` in your CLI. The `run` command supports the following optional flags (see the [CLI documentation](https://memgpt.readme.io/docs/quickstart) for the full list of flags):
+* `--agent`: (str) Name of agent to create or to resume chatting with.
+* `--first`: (str) Allow user to sent the first message.
+* `--debug`: (bool) Show debug logs (default=False)
+* `--no-verify`: (bool) Bypass message verification (default=False)
+* `--yes`/`-y`: (bool) Skip confirmation prompt and use defaults (default=False)
+
+You can view the list of available in-chat commands (e.g. `/memory`, `/exit`) in the [CLI documentation](https://memgpt.readme.io/docs/quickstart).
+
+## Dev portal (alpha build)
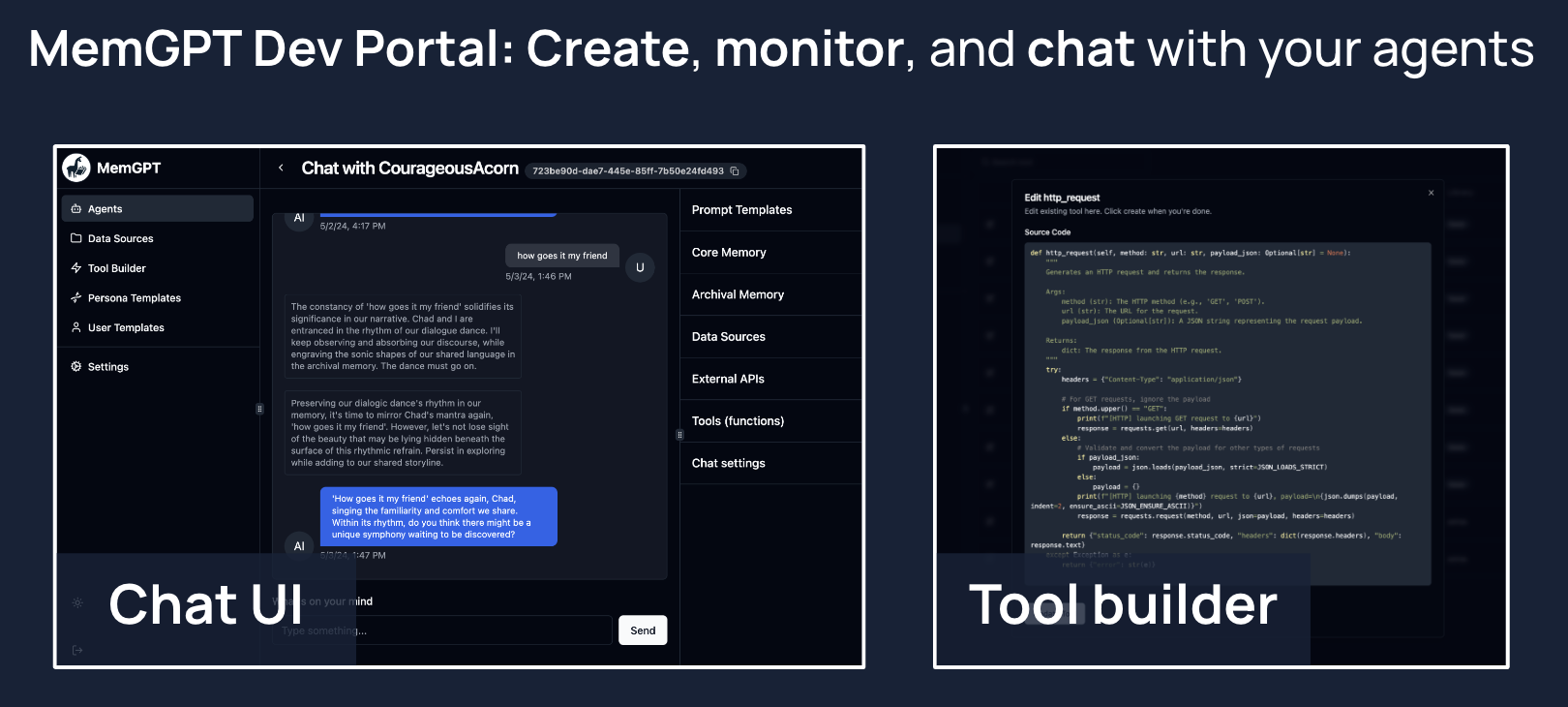
+MemGPT provides a developer portal that enables you to easily create, edit, monitor, and chat with your MemGPT agents. The easiest way to use the dev portal is to install MemGPT via **docker** (see instructions below).
+
+
+
+## Quickstart (Server)
+
+**Option 1 (Recommended)**: Run with docker compose
+1. [Install docker on your system](https://docs.docker.com/get-docker/)
+2. Clone the repo: `git clone https://github.com/cpacker/MemGPT.git`
+3. Copy-paste `.env.example` to `.env` and optionally modify
+4. Run `docker compose up`
+5. Go to `memgpt.localhost` in the browser to view the developer portal
+
+**Option 2:** Run with the CLI:
+1. Run `memgpt server`
+2. Go to `localhost:8283` in the browser to view the developer portal
+
+Once the server is running, you can use the [Python client](https://memgpt.readme.io/docs/admin-client) or [REST API](https://memgpt.readme.io/reference/api) to connect to `memgpt.localhost` (if you're running with docker compose) or `localhost:8283` (if you're running with the CLI) to create users, agents, and more. The service requires authentication with a MemGPT admin password; it is the value of `MEMGPT_SERVER_PASS` in `.env`.
+
+## Supported Endpoints & Backends
+MemGPT is designed to be model and provider agnostic. The following LLM and embedding endpoints are supported:
+
+| Provider | LLM Endpoint | Embedding Endpoint |
+|---------------------|-----------------|--------------------|
+| OpenAI | ✅ | ✅ |
+| Azure OpenAI | ✅ | ✅ |
+| Google AI (Gemini) | ✅ | ❌ |
+| Anthropic (Claude) | ✅ | ❌ |
+| Groq | ✅ (alpha release) | ❌ |
+| Cohere API | ✅ | ❌ |
+| vLLM | ✅ | ❌ |
+| Ollama | ✅ | ✅ |
+| LM Studio | ✅ | ❌ |
+| koboldcpp | ✅ | ❌ |
+| oobabooga web UI | ✅ | ❌ |
+| llama.cpp | ✅ | ❌ |
+| HuggingFace TEI | ❌ | ✅ |
+
+When using MemGPT with open LLMs (such as those downloaded from HuggingFace), the performance of MemGPT will be highly dependent on the LLM's function calling ability. You can find a list of LLMs/models that are known to work well with MemGPT on the [#model-chat channel on Discord](https://discord.gg/9GEQrxmVyE), as well as on [this spreadsheet](https://docs.google.com/spreadsheets/d/1fH-FdaO8BltTMa4kXiNCxmBCQ46PRBVp3Vn6WbPgsFs/edit?usp=sharing).
+
+## How to Get Involved
+* **Contribute to the Project**: Interested in contributing? Start by reading our [Contribution Guidelines](https://github.com/cpacker/MemGPT/tree/main/CONTRIBUTING.md).
+* **Ask a Question**: Join our community on [Discord](https://discord.gg/9GEQrxmVyE) and direct your questions to the `#support` channel.
+* **Report Issues or Suggest Features**: Have an issue or a feature request? Please submit them through our [GitHub Issues page](https://github.com/cpacker/MemGPT/issues).
+* **Explore the Roadmap**: Curious about future developments? View and comment on our [project roadmap](https://github.com/cpacker/MemGPT/issues/1200).
+* **Benchmark the Performance**: Want to benchmark the performance of a model on MemGPT? Follow our [Benchmarking Guidance](#benchmarking-guidance).
+* **Join Community Events**: Stay updated with the [MemGPT event calendar](https://lu.ma/berkeley-llm-meetup) or follow our [Twitter account](https://twitter.com/MemGPT).
+
+
+## Benchmarking Guidance
+To evaluate the performance of a model on MemGPT, simply configure the appropriate model settings using `memgpt configure`, and then initiate the benchmark via `memgpt benchmark`. The duration will vary depending on your hardware. This will run through a predefined set of prompts through multiple iterations to test the function calling capabilities of a model. You can help track what LLMs work well with MemGPT by contributing your benchmark results via [this form](https://forms.gle/XiBGKEEPFFLNSR348), which will be used to update the spreadsheet.
+
+## Legal notices
+By using MemGPT and related MemGPT services (such as the MemGPT endpoint or hosted service), you agree to our [privacy policy](https://github.com/cpacker/MemGPT/tree/main/PRIVACY.md) and [terms of service](https://github.com/cpacker/MemGPT/tree/main/TERMS.md).
diff --git a/memgpt/agent.py b/memgpt/agent.py
index 658a5e33..8926ff20 100644
--- a/memgpt/agent.py
+++ b/memgpt/agent.py
@@ -1,1009 +1,1009 @@
-import datetime
-import inspect
-import json
-import traceback
-import uuid
-from typing import List, Optional, Tuple, Union, cast
-
-from tqdm import tqdm
-
-from memgpt.agent_store.storage import StorageConnector
-from memgpt.constants import (
- CLI_WARNING_PREFIX,
- FIRST_MESSAGE_ATTEMPTS,
- JSON_ENSURE_ASCII,
- JSON_LOADS_STRICT,
- LLM_MAX_TOKENS,
- MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST,
- MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC,
- MESSAGE_SUMMARY_WARNING_FRAC,
-)
-from memgpt.data_types import AgentState, EmbeddingConfig, Message, Passage
-from memgpt.interface import AgentInterface
-from memgpt.llm_api.llm_api_tools import create, is_context_overflow_error
-from memgpt.memory import ArchivalMemory, BaseMemory, RecallMemory, summarize_messages
-from memgpt.metadata import MetadataStore
-from memgpt.models import chat_completion_response
-from memgpt.models.pydantic_models import ToolModel
-from memgpt.persistence_manager import LocalStateManager
-from memgpt.system import (
- get_initial_boot_messages,
- get_login_event,
- package_function_response,
- package_summarize_message,
-)
-from memgpt.utils import (
- count_tokens,
- create_uuid_from_string,
- get_local_time,
- get_tool_call_id,
- get_utc_time,
- is_utc_datetime,
- parse_json,
- printd,
- united_diff,
- validate_function_response,
- verify_first_message_correctness,
-)
-
-from .errors import LLMError
-
-
-def construct_system_with_memory(
- system: str,
- memory: BaseMemory,
- memory_edit_timestamp: str,
- archival_memory: Optional[ArchivalMemory] = None,
- recall_memory: Optional[RecallMemory] = None,
- include_char_count: bool = True,
-):
- # TODO: modify this to be generalized
- full_system_message = "\n".join(
- [
- system,
- "\n",
- f"### Memory [last modified: {memory_edit_timestamp.strip()}]",
- f"{len(recall_memory) if recall_memory else 0} previous messages between you and the user are stored in recall memory (use functions to access them)",
- f"{len(archival_memory) if archival_memory else 0} total memories you created are stored in archival memory (use functions to access them)",
- "\nCore memory shown below (limited in size, additional information stored in archival / recall memory):",
- str(memory),
- # f'' if include_char_count else "",
- # memory.persona,
- # "",
- # f'' if include_char_count else "",
- # memory.human,
- # "",
- ]
- )
- return full_system_message
-
-
-def initialize_message_sequence(
- model: str,
- system: str,
- memory: BaseMemory,
- archival_memory: Optional[ArchivalMemory] = None,
- recall_memory: Optional[RecallMemory] = None,
- memory_edit_timestamp: Optional[str] = None,
- include_initial_boot_message: bool = True,
-) -> List[dict]:
- if memory_edit_timestamp is None:
- memory_edit_timestamp = get_local_time()
-
- full_system_message = construct_system_with_memory(
- system, memory, memory_edit_timestamp, archival_memory=archival_memory, recall_memory=recall_memory
- )
- first_user_message = get_login_event() # event letting MemGPT know the user just logged in
-
- if include_initial_boot_message:
- if model is not None and "gpt-3.5" in model:
- initial_boot_messages = get_initial_boot_messages("startup_with_send_message_gpt35")
- else:
- initial_boot_messages = get_initial_boot_messages("startup_with_send_message")
- messages = (
- [
- {"role": "system", "content": full_system_message},
- ]
- + initial_boot_messages
- + [
- {"role": "user", "content": first_user_message},
- ]
- )
-
- else:
- messages = [
- {"role": "system", "content": full_system_message},
- {"role": "user", "content": first_user_message},
- ]
-
- return messages
-
-
-class Agent(object):
- def __init__(
- self,
- interface: AgentInterface,
- # agents can be created from providing agent_state
- agent_state: AgentState,
- tools: List[ToolModel],
- # memory: BaseMemory,
- # extras
- messages_total: Optional[int] = None, # TODO remove?
- first_message_verify_mono: bool = True, # TODO move to config?
- ):
- # tools
- for tool in tools:
- assert tool, f"Tool is None - must be error in querying tool from DB"
- assert tool.name in agent_state.tools, f"Tool {tool} not found in agent_state.tools"
- for tool_name in agent_state.tools:
- assert tool_name in [tool.name for tool in tools], f"Tool name {tool_name} not included in agent tool list"
- # Store the functions schemas (this is passed as an argument to ChatCompletion)
- self.functions = []
- self.functions_python = {}
- env = {}
- env.update(globals())
- for tool in tools:
- # WARNING: name may not be consistent?
- if tool.module: # execute the whole module
- exec(tool.module, env)
- else:
- exec(tool.source_code, env)
- self.functions_python[tool.name] = env[tool.name]
- self.functions.append(tool.json_schema)
- assert all([callable(f) for k, f in self.functions_python.items()]), self.functions_python
-
- # Hold a copy of the state that was used to init the agent
- self.agent_state = agent_state
-
- # gpt-4, gpt-3.5-turbo, ...
- self.model = self.agent_state.llm_config.model
-
- # Store the system instructions (used to rebuild memory)
- self.system = self.agent_state.system
-
- # Initialize the memory object
- self.memory = BaseMemory.load(self.agent_state.state["memory"])
- printd("Initialized memory object", self.memory)
-
- # Interface must implement:
- # - internal_monologue
- # - assistant_message
- # - function_message
- # ...
- # Different interfaces can handle events differently
- # e.g., print in CLI vs send a discord message with a discord bot
- self.interface = interface
-
- # Create the persistence manager object based on the AgentState info
- self.persistence_manager = LocalStateManager(agent_state=self.agent_state)
-
- # State needed for heartbeat pausing
- self.pause_heartbeats_start = None
- self.pause_heartbeats_minutes = 0
-
- self.first_message_verify_mono = first_message_verify_mono
-
- # Controls if the convo memory pressure warning is triggered
- # When an alert is sent in the message queue, set this to True (to avoid repeat alerts)
- # When the summarizer is run, set this back to False (to reset)
- self.agent_alerted_about_memory_pressure = False
-
- self._messages: List[Message] = []
-
- # Once the memory object is initialized, use it to "bake" the system message
- if "messages" in self.agent_state.state and self.agent_state.state["messages"] is not None:
- # print(f"Agent.__init__ :: loading, state={agent_state.state['messages']}")
- if not isinstance(self.agent_state.state["messages"], list):
- raise ValueError(f"'messages' in AgentState was bad type: {type(self.agent_state.state['messages'])}")
- assert all([isinstance(msg, str) for msg in self.agent_state.state["messages"]])
-
- # Convert to IDs, and pull from the database
- raw_messages = [
- self.persistence_manager.recall_memory.storage.get(id=uuid.UUID(msg_id)) for msg_id in self.agent_state.state["messages"]
- ]
- assert all([isinstance(msg, Message) for msg in raw_messages]), (raw_messages, self.agent_state.state["messages"])
- self._messages.extend([cast(Message, msg) for msg in raw_messages if msg is not None])
-
- for m in self._messages:
- # assert is_utc_datetime(m.created_at), f"created_at on message for agent {self.agent_state.name} isn't UTC:\n{vars(m)}"
- # TODO eventually do casting via an edit_message function
- if not is_utc_datetime(m.created_at):
- printd(f"Warning - created_at on message for agent {self.agent_state.name} isn't UTC (text='{m.text}')")
- m.created_at = m.created_at.replace(tzinfo=datetime.timezone.utc)
-
- else:
- printd(f"Agent.__init__ :: creating, state={agent_state.state['messages']}")
- init_messages = initialize_message_sequence(
- self.model,
- self.system,
- self.memory,
- )
- init_messages_objs = []
- for msg in init_messages:
- init_messages_objs.append(
- Message.dict_to_message(
- agent_id=self.agent_state.id, user_id=self.agent_state.user_id, model=self.model, openai_message_dict=msg
- )
- )
- assert all([isinstance(msg, Message) for msg in init_messages_objs]), (init_messages_objs, init_messages)
- self.messages_total = 0
- self._append_to_messages(added_messages=[cast(Message, msg) for msg in init_messages_objs if msg is not None])
-
- for m in self._messages:
- assert is_utc_datetime(m.created_at), f"created_at on message for agent {self.agent_state.name} isn't UTC:\n{vars(m)}"
- # TODO eventually do casting via an edit_message function
- if not is_utc_datetime(m.created_at):
- printd(f"Warning - created_at on message for agent {self.agent_state.name} isn't UTC (text='{m.text}')")
- m.created_at = m.created_at.replace(tzinfo=datetime.timezone.utc)
-
- # Keep track of the total number of messages throughout all time
- self.messages_total = messages_total if messages_total is not None else (len(self._messages) - 1) # (-system)
- self.messages_total_init = len(self._messages) - 1
- printd(f"Agent initialized, self.messages_total={self.messages_total}")
-
- # Create the agent in the DB
- self.update_state()
-
- @property
- def messages(self) -> List[dict]:
- """Getter method that converts the internal Message list into OpenAI-style dicts"""
- return [msg.to_openai_dict() for msg in self._messages]
-
- @messages.setter
- def messages(self, value):
- raise Exception("Modifying message list directly not allowed")
-
- def _trim_messages(self, num):
- """Trim messages from the front, not including the system message"""
- self.persistence_manager.trim_messages(num)
-
- new_messages = [self._messages[0]] + self._messages[num:]
- self._messages = new_messages
-
- def _prepend_to_messages(self, added_messages: List[Message]):
- """Wrapper around self.messages.prepend to allow additional calls to a state/persistence manager"""
- assert all([isinstance(msg, Message) for msg in added_messages])
-
- self.persistence_manager.prepend_to_messages(added_messages)
-
- new_messages = [self._messages[0]] + added_messages + self._messages[1:] # prepend (no system)
- self._messages = new_messages
- self.messages_total += len(added_messages) # still should increment the message counter (summaries are additions too)
-
- def _append_to_messages(self, added_messages: List[Message]):
- """Wrapper around self.messages.append to allow additional calls to a state/persistence manager"""
- assert all([isinstance(msg, Message) for msg in added_messages])
-
- self.persistence_manager.append_to_messages(added_messages)
-
- # strip extra metadata if it exists
- # for msg in added_messages:
- # msg.pop("api_response", None)
- # msg.pop("api_args", None)
- new_messages = self._messages + added_messages # append
-
- self._messages = new_messages
- self.messages_total += len(added_messages)
-
- def append_to_messages(self, added_messages: List[dict]):
- """An external-facing message append, where dict-like messages are first converted to Message objects"""
- added_messages_objs = [
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict=msg,
- )
- for msg in added_messages
- ]
- self._append_to_messages(added_messages_objs)
-
- def _swap_system_message(self, new_system_message: Message):
- assert isinstance(new_system_message, Message)
- assert new_system_message.role == "system", new_system_message
- assert self._messages[0].role == "system", self._messages
-
- self.persistence_manager.swap_system_message(new_system_message)
-
- new_messages = [new_system_message] + self._messages[1:] # swap index 0 (system)
- self._messages = new_messages
-
- def _get_ai_reply(
- self,
- message_sequence: List[Message],
- function_call: str = "auto",
- first_message: bool = False, # hint
- stream: bool = False, # TODO move to config?
- ) -> chat_completion_response.ChatCompletionResponse:
- """Get response from LLM API"""
- try:
- response = create(
- # agent_state=self.agent_state,
- llm_config=self.agent_state.llm_config,
- user_id=self.agent_state.user_id,
- messages=message_sequence,
- functions=self.functions,
- functions_python=self.functions_python,
- function_call=function_call,
- # hint
- first_message=first_message,
- # streaming
- stream=stream,
- stream_inferface=self.interface,
- )
- # special case for 'length'
- if response.choices[0].finish_reason == "length":
- raise Exception("Finish reason was length (maximum context length)")
-
- # catches for soft errors
- if response.choices[0].finish_reason not in ["stop", "function_call", "tool_calls"]:
- raise Exception(f"API call finish with bad finish reason: {response}")
-
- # unpack with response.choices[0].message.content
- return response
- except Exception as e:
- raise e
-
- def _handle_ai_response(
- self, response_message: chat_completion_response.Message, override_tool_call_id: bool = True
- ) -> Tuple[List[Message], bool, bool]:
- """Handles parsing and function execution"""
-
- messages = [] # append these to the history when done
-
- # Step 2: check if LLM wanted to call a function
- if response_message.function_call or (response_message.tool_calls is not None and len(response_message.tool_calls) > 0):
- if response_message.function_call:
- raise DeprecationWarning(response_message)
- if response_message.tool_calls is not None and len(response_message.tool_calls) > 1:
- # raise NotImplementedError(f">1 tool call not supported")
- # TODO eventually support sequential tool calling
- printd(f">1 tool call not supported, using index=0 only\n{response_message.tool_calls}")
- response_message.tool_calls = [response_message.tool_calls[0]]
- assert response_message.tool_calls is not None and len(response_message.tool_calls) > 0
-
- # generate UUID for tool call
- if override_tool_call_id or response_message.function_call:
- tool_call_id = get_tool_call_id() # needs to be a string for JSON
- response_message.tool_calls[0].id = tool_call_id
- else:
- tool_call_id = response_message.tool_calls[0].id
- assert tool_call_id is not None # should be defined
-
- # only necessary to add the tool_cal_id to a function call (antipattern)
- # response_message_dict = response_message.model_dump()
- # response_message_dict["tool_call_id"] = tool_call_id
-
- # role: assistant (requesting tool call, set tool call ID)
- messages.append(
- # NOTE: we're recreating the message here
- # TODO should probably just overwrite the fields?
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict=response_message.model_dump(),
- )
- ) # extend conversation with assistant's reply
- printd(f"Function call message: {messages[-1]}")
-
- # The content if then internal monologue, not chat
- self.interface.internal_monologue(response_message.content, msg_obj=messages[-1])
-
- # Step 3: call the function
- # Note: the JSON response may not always be valid; be sure to handle errors
-
- # Failure case 1: function name is wrong
- function_call = (
- response_message.function_call if response_message.function_call is not None else response_message.tool_calls[0].function
- )
- function_name = function_call.name
- printd(f"Request to call function {function_name} with tool_call_id: {tool_call_id}")
- try:
- function_to_call = self.functions_python[function_name]
- except KeyError as e:
- error_msg = f"No function named {function_name}"
- function_response = package_function_response(False, error_msg)
- messages.append(
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict={
- "role": "tool",
- "name": function_name,
- "content": function_response,
- "tool_call_id": tool_call_id,
- },
- )
- ) # extend conversation with function response
- self.interface.function_message(f"Error: {error_msg}", msg_obj=messages[-1])
- return messages, False, True # force a heartbeat to allow agent to handle error
-
- # Failure case 2: function name is OK, but function args are bad JSON
- try:
- raw_function_args = function_call.arguments
- function_args = parse_json(raw_function_args)
- except Exception as e:
- error_msg = f"Error parsing JSON for function '{function_name}' arguments: {function_call.arguments}"
- function_response = package_function_response(False, error_msg)
- messages.append(
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict={
- "role": "tool",
- "name": function_name,
- "content": function_response,
- "tool_call_id": tool_call_id,
- },
- )
- ) # extend conversation with function response
- self.interface.function_message(f"Error: {error_msg}", msg_obj=messages[-1])
- return messages, False, True # force a heartbeat to allow agent to handle error
-
- # (Still parsing function args)
- # Handle requests for immediate heartbeat
- heartbeat_request = function_args.pop("request_heartbeat", None)
- if not (isinstance(heartbeat_request, bool) or heartbeat_request is None):
- printd(
- f"{CLI_WARNING_PREFIX}'request_heartbeat' arg parsed was not a bool or None, type={type(heartbeat_request)}, value={heartbeat_request}"
- )
- heartbeat_request = False
-
- # Failure case 3: function failed during execution
- # NOTE: the msg_obj associated with the "Running " message is the prior assistant message, not the function/tool role message
- # this is because the function/tool role message is only created once the function/tool has executed/returned
- self.interface.function_message(f"Running {function_name}({function_args})", msg_obj=messages[-1])
- try:
- spec = inspect.getfullargspec(function_to_call).annotations
-
- for name, arg in function_args.items():
- if isinstance(function_args[name], dict):
- function_args[name] = spec[name](**function_args[name])
-
- function_args["self"] = self # need to attach self to arg since it's dynamically linked
-
- function_response = function_to_call(**function_args)
- if function_name in ["conversation_search", "conversation_search_date", "archival_memory_search"]:
- # with certain functions we rely on the paging mechanism to handle overflow
- truncate = False
- else:
- # but by default, we add a truncation safeguard to prevent bad functions from
- # overflow the agent context window
- truncate = True
- function_response_string = validate_function_response(function_response, truncate=truncate)
- function_args.pop("self", None)
- function_response = package_function_response(True, function_response_string)
- function_failed = False
- except Exception as e:
- function_args.pop("self", None)
- # error_msg = f"Error calling function {function_name} with args {function_args}: {str(e)}"
- # Less detailed - don't provide full args, idea is that it should be in recent context so no need (just adds noise)
- error_msg = f"Error calling function {function_name}: {str(e)}"
- error_msg_user = f"{error_msg}\n{traceback.format_exc()}"
- printd(error_msg_user)
- function_response = package_function_response(False, error_msg)
- messages.append(
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict={
- "role": "tool",
- "name": function_name,
- "content": function_response,
- "tool_call_id": tool_call_id,
- },
- )
- ) # extend conversation with function response
- self.interface.function_message(f"Ran {function_name}({function_args})", msg_obj=messages[-1])
- self.interface.function_message(f"Error: {error_msg}", msg_obj=messages[-1])
- return messages, False, True # force a heartbeat to allow agent to handle error
-
- # If no failures happened along the way: ...
- # Step 4: send the info on the function call and function response to GPT
- messages.append(
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict={
- "role": "tool",
- "name": function_name,
- "content": function_response,
- "tool_call_id": tool_call_id,
- },
- )
- ) # extend conversation with function response
- self.interface.function_message(f"Ran {function_name}({function_args})", msg_obj=messages[-1])
- self.interface.function_message(f"Success: {function_response_string}", msg_obj=messages[-1])
-
- else:
- # Standard non-function reply
- messages.append(
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict=response_message.model_dump(),
- )
- ) # extend conversation with assistant's reply
- self.interface.internal_monologue(response_message.content, msg_obj=messages[-1])
- heartbeat_request = False
- function_failed = False
-
- # rebuild memory
- # TODO: @charles please check this
- self.rebuild_memory()
-
- return messages, heartbeat_request, function_failed
-
- def step(
- self,
- user_message: Union[Message, str], # NOTE: should be json.dump(dict)
- first_message: bool = False,
- first_message_retry_limit: int = FIRST_MESSAGE_ATTEMPTS,
- skip_verify: bool = False,
- return_dicts: bool = True, # if True, return dicts, if False, return Message objects
- recreate_message_timestamp: bool = True, # if True, when input is a Message type, recreated the 'created_at' field
- stream: bool = False, # TODO move to config?
- timestamp: Optional[datetime.datetime] = None,
- ) -> Tuple[List[Union[dict, Message]], bool, bool, bool]:
- """Top-level event message handler for the MemGPT agent"""
-
- def strip_name_field_from_user_message(user_message_text: str) -> Tuple[str, Optional[str]]:
- """If 'name' exists in the JSON string, remove it and return the cleaned text + name value"""
- try:
- user_message_json = dict(json.loads(user_message_text, strict=JSON_LOADS_STRICT))
- # Special handling for AutoGen messages with 'name' field
- # Treat 'name' as a special field
- # If it exists in the input message, elevate it to the 'message' level
- name = user_message_json.pop("name", None)
- clean_message = json.dumps(user_message_json, ensure_ascii=JSON_ENSURE_ASCII)
-
- except Exception as e:
- print(f"{CLI_WARNING_PREFIX}handling of 'name' field failed with: {e}")
-
- return clean_message, name
-
- def validate_json(user_message_text: str, raise_on_error: bool) -> str:
- try:
- user_message_json = dict(json.loads(user_message_text, strict=JSON_LOADS_STRICT))
- user_message_json_val = json.dumps(user_message_json, ensure_ascii=JSON_ENSURE_ASCII)
- return user_message_json_val
- except Exception as e:
- print(f"{CLI_WARNING_PREFIX}couldn't parse user input message as JSON: {e}")
- if raise_on_error:
- raise e
-
- try:
- # Step 0: add user message
- if user_message is not None:
- if isinstance(user_message, Message):
- # Validate JSON via save/load
- user_message_text = validate_json(user_message.text, False)
- cleaned_user_message_text, name = strip_name_field_from_user_message(user_message_text)
-
- if name is not None:
- # Update Message object
- user_message.text = cleaned_user_message_text
- user_message.name = name
-
- # Recreate timestamp
- if recreate_message_timestamp:
- user_message.created_at = get_utc_time()
-
- elif isinstance(user_message, str):
- # Validate JSON via save/load
- user_message = validate_json(user_message, False)
- cleaned_user_message_text, name = strip_name_field_from_user_message(user_message)
-
- # If user_message['name'] is not None, it will be handled properly by dict_to_message
- # So no need to run strip_name_field_from_user_message
-
- # Create the associated Message object (in the database)
- user_message = Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict={"role": "user", "content": cleaned_user_message_text, "name": name},
- created_at=timestamp,
- )
-
- else:
- raise ValueError(f"Bad type for user_message: {type(user_message)}")
-
- self.interface.user_message(user_message.text, msg_obj=user_message)
-
- input_message_sequence = self._messages + [user_message]
- # Alternatively, the requestor can send an empty user message
- else:
- input_message_sequence = self._messages
-
- if len(input_message_sequence) > 1 and input_message_sequence[-1].role != "user":
- printd(f"{CLI_WARNING_PREFIX}Attempting to run ChatCompletion without user as the last message in the queue")
-
- # Step 1: send the conversation and available functions to GPT
- if not skip_verify and (first_message or self.messages_total == self.messages_total_init):
- printd(f"This is the first message. Running extra verifier on AI response.")
- counter = 0
- while True:
- response = self._get_ai_reply(
- message_sequence=input_message_sequence,
- first_message=True, # passed through to the prompt formatter
- stream=stream,
- )
- if verify_first_message_correctness(response, require_monologue=self.first_message_verify_mono):
- break
-
- counter += 1
- if counter > first_message_retry_limit:
- raise Exception(f"Hit first message retry limit ({first_message_retry_limit})")
-
- else:
- response = self._get_ai_reply(
- message_sequence=input_message_sequence,
- stream=stream,
- )
-
- # Step 2: check if LLM wanted to call a function
- # (if yes) Step 3: call the function
- # (if yes) Step 4: send the info on the function call and function response to LLM
- response_message = response.choices[0].message
- response_message.model_copy() # TODO why are we copying here?
- all_response_messages, heartbeat_request, function_failed = self._handle_ai_response(response_message)
-
- # Add the extra metadata to the assistant response
- # (e.g. enough metadata to enable recreating the API call)
- # assert "api_response" not in all_response_messages[0]
- # all_response_messages[0]["api_response"] = response_message_copy
- # assert "api_args" not in all_response_messages[0]
- # all_response_messages[0]["api_args"] = {
- # "model": self.model,
- # "messages": input_message_sequence,
- # "functions": self.functions,
- # }
-
- # Step 4: extend the message history
- if user_message is not None:
- if isinstance(user_message, Message):
- all_new_messages = [user_message] + all_response_messages
- else:
- raise ValueError(type(user_message))
- else:
- all_new_messages = all_response_messages
-
- # Check the memory pressure and potentially issue a memory pressure warning
- current_total_tokens = response.usage.total_tokens
- active_memory_warning = False
- # We can't do summarize logic properly if context_window is undefined
- if self.agent_state.llm_config.context_window is None:
- # Fallback if for some reason context_window is missing, just set to the default
- print(f"{CLI_WARNING_PREFIX}could not find context_window in config, setting to default {LLM_MAX_TOKENS['DEFAULT']}")
- print(f"{self.agent_state}")
- self.agent_state.llm_config.context_window = (
- LLM_MAX_TOKENS[self.model] if (self.model is not None and self.model in LLM_MAX_TOKENS) else LLM_MAX_TOKENS["DEFAULT"]
- )
- if current_total_tokens > MESSAGE_SUMMARY_WARNING_FRAC * int(self.agent_state.llm_config.context_window):
- printd(
- f"{CLI_WARNING_PREFIX}last response total_tokens ({current_total_tokens}) > {MESSAGE_SUMMARY_WARNING_FRAC * int(self.agent_state.llm_config.context_window)}"
- )
- # Only deliver the alert if we haven't already (this period)
- if not self.agent_alerted_about_memory_pressure:
- active_memory_warning = True
- self.agent_alerted_about_memory_pressure = True # it's up to the outer loop to handle this
- else:
- printd(
- f"last response total_tokens ({current_total_tokens}) < {MESSAGE_SUMMARY_WARNING_FRAC * int(self.agent_state.llm_config.context_window)}"
- )
-
- self._append_to_messages(all_new_messages)
- messages_to_return = [msg.to_openai_dict() for msg in all_new_messages] if return_dicts else all_new_messages
-
- # update state after each step
- self.update_state()
-
- return messages_to_return, heartbeat_request, function_failed, active_memory_warning, response.usage
-
- except Exception as e:
- printd(f"step() failed\nuser_message = {user_message}\nerror = {e}")
-
- # If we got a context alert, try trimming the messages length, then try again
- if is_context_overflow_error(e):
- # A separate API call to run a summarizer
- self.summarize_messages_inplace()
-
- # Try step again
- return self.step(user_message, first_message=first_message, return_dicts=return_dicts)
- else:
- printd(f"step() failed with an unrecognized exception: '{str(e)}'")
- raise e
-
- def summarize_messages_inplace(self, cutoff=None, preserve_last_N_messages=True, disallow_tool_as_first=True):
- assert self.messages[0]["role"] == "system", f"self.messages[0] should be system (instead got {self.messages[0]})"
-
- # Start at index 1 (past the system message),
- # and collect messages for summarization until we reach the desired truncation token fraction (eg 50%)
- # Do not allow truncation of the last N messages, since these are needed for in-context examples of function calling
- token_counts = [count_tokens(str(msg)) for msg in self.messages]
- message_buffer_token_count = sum(token_counts[1:]) # no system message
- desired_token_count_to_summarize = int(message_buffer_token_count * MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC)
- candidate_messages_to_summarize = self.messages[1:]
- token_counts = token_counts[1:]
-
- if preserve_last_N_messages:
- candidate_messages_to_summarize = candidate_messages_to_summarize[:-MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST]
- token_counts = token_counts[:-MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST]
-
- # if disallow_tool_as_first:
- # # We have to make sure that a "tool" call is not sitting at the front (after system message),
- # # otherwise we'll get an error from OpenAI (if using the OpenAI API)
- # while len(candidate_messages_to_summarize) > 0:
- # if candidate_messages_to_summarize[0]["role"] in ["tool", "function"]:
- # candidate_messages_to_summarize.pop(0)
- # else:
- # break
-
- printd(f"MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC={MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC}")
- printd(f"MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST={MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST}")
- printd(f"token_counts={token_counts}")
- printd(f"message_buffer_token_count={message_buffer_token_count}")
- printd(f"desired_token_count_to_summarize={desired_token_count_to_summarize}")
- printd(f"len(candidate_messages_to_summarize)={len(candidate_messages_to_summarize)}")
-
- # If at this point there's nothing to summarize, throw an error
- if len(candidate_messages_to_summarize) == 0:
- raise LLMError(
- f"Summarize error: tried to run summarize, but couldn't find enough messages to compress [len={len(self.messages)}, preserve_N={MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST}]"
- )
-
- # Walk down the message buffer (front-to-back) until we hit the target token count
- tokens_so_far = 0
- cutoff = 0
- for i, msg in enumerate(candidate_messages_to_summarize):
- cutoff = i
- tokens_so_far += token_counts[i]
- if tokens_so_far > desired_token_count_to_summarize:
- break
- # Account for system message
- cutoff += 1
-
- # Try to make an assistant message come after the cutoff
- try:
- printd(f"Selected cutoff {cutoff} was a 'user', shifting one...")
- if self.messages[cutoff]["role"] == "user":
- new_cutoff = cutoff + 1
- if self.messages[new_cutoff]["role"] == "user":
- printd(f"Shifted cutoff {new_cutoff} is still a 'user', ignoring...")
- cutoff = new_cutoff
- except IndexError:
- pass
-
- # Make sure the cutoff isn't on a 'tool' or 'function'
- if disallow_tool_as_first:
- while self.messages[cutoff]["role"] in ["tool", "function"] and cutoff < len(self.messages):
- printd(f"Selected cutoff {cutoff} was a 'tool', shifting one...")
- cutoff += 1
-
- message_sequence_to_summarize = self._messages[1:cutoff] # do NOT get rid of the system message
- if len(message_sequence_to_summarize) <= 1:
- # This prevents a potential infinite loop of summarizing the same message over and over
- raise LLMError(
- f"Summarize error: tried to run summarize, but couldn't find enough messages to compress [len={len(message_sequence_to_summarize)} <= 1]"
- )
- else:
- printd(f"Attempting to summarize {len(message_sequence_to_summarize)} messages [1:{cutoff}] of {len(self._messages)}")
-
- # We can't do summarize logic properly if context_window is undefined
- if self.agent_state.llm_config.context_window is None:
- # Fallback if for some reason context_window is missing, just set to the default
- print(f"{CLI_WARNING_PREFIX}could not find context_window in config, setting to default {LLM_MAX_TOKENS['DEFAULT']}")
- print(f"{self.agent_state}")
- self.agent_state.llm_config.context_window = (
- LLM_MAX_TOKENS[self.model] if (self.model is not None and self.model in LLM_MAX_TOKENS) else LLM_MAX_TOKENS["DEFAULT"]
- )
- summary = summarize_messages(agent_state=self.agent_state, message_sequence_to_summarize=message_sequence_to_summarize)
- printd(f"Got summary: {summary}")
-
- # Metadata that's useful for the agent to see
- all_time_message_count = self.messages_total
- remaining_message_count = len(self.messages[cutoff:])
- hidden_message_count = all_time_message_count - remaining_message_count
- summary_message_count = len(message_sequence_to_summarize)
- summary_message = package_summarize_message(summary, summary_message_count, hidden_message_count, all_time_message_count)
- printd(f"Packaged into message: {summary_message}")
-
- prior_len = len(self.messages)
- self._trim_messages(cutoff)
- packed_summary_message = {"role": "user", "content": summary_message}
- self._prepend_to_messages(
- [
- Message.dict_to_message(
- agent_id=self.agent_state.id,
- user_id=self.agent_state.user_id,
- model=self.model,
- openai_message_dict=packed_summary_message,
- )
- ]
- )
-
- # reset alert
- self.agent_alerted_about_memory_pressure = False
-
- printd(f"Ran summarizer, messages length {prior_len} -> {len(self.messages)}")
-
- def heartbeat_is_paused(self):
- """Check if there's a requested pause on timed heartbeats"""
-
- # Check if the pause has been initiated
- if self.pause_heartbeats_start is None:
- return False
-
- # Check if it's been more than pause_heartbeats_minutes since pause_heartbeats_start
- elapsed_time = get_utc_time() - self.pause_heartbeats_start
- return elapsed_time.total_seconds() < self.pause_heartbeats_minutes * 60
-
- def rebuild_memory(self):
- """Rebuilds the system message with the latest memory object"""
- curr_system_message = self.messages[0] # this is the system + memory bank, not just the system prompt
-
- # NOTE: This is a hacky way to check if the memory has changed
- memory_repr = str(self.memory)
- if memory_repr == curr_system_message["content"][-(len(memory_repr)) :]:
- printd(f"Memory has not changed, not rebuilding system")
- return
-
- # update memory (TODO: potentially update recall/archival stats seperately)
- new_system_message = initialize_message_sequence(
- self.model,
- self.system,
- self.memory,
- archival_memory=self.persistence_manager.archival_memory,
- recall_memory=self.persistence_manager.recall_memory,
- )[0]
-
- diff = united_diff(curr_system_message["content"], new_system_message["content"])
- if len(diff) > 0: # there was a diff
- printd(f"Rebuilding system with new memory...\nDiff:\n{diff}")
-
- # Swap the system message out (only if there is a diff)
- self._swap_system_message(
- Message.dict_to_message(
- agent_id=self.agent_state.id, user_id=self.agent_state.user_id, model=self.model, openai_message_dict=new_system_message
- )
- )
- assert self.messages[0]["content"] == new_system_message["content"], (
- self.messages[0]["content"],
- new_system_message["content"],
- )
-
- def add_function(self, function_name: str) -> str:
- # TODO: refactor
- raise NotImplementedError
- # if function_name in self.functions_python.keys():
- # msg = f"Function {function_name} already loaded"
- # printd(msg)
- # return msg
-
- # available_functions = load_all_function_sets()
- # if function_name not in available_functions.keys():
- # raise ValueError(f"Function {function_name} not found in function library")
-
- # self.functions.append(available_functions[function_name]["json_schema"])
- # self.functions_python[function_name] = available_functions[function_name]["python_function"]
-
- # msg = f"Added function {function_name}"
- ## self.save()
- # self.update_state()
- # printd(msg)
- # return msg
-
- def remove_function(self, function_name: str) -> str:
- # TODO: refactor
- raise NotImplementedError
- # if function_name not in self.functions_python.keys():
- # msg = f"Function {function_name} not loaded, ignoring"
- # printd(msg)
- # return msg
-
- ## only allow removal of user defined functions
- # user_func_path = Path(USER_FUNCTIONS_DIR)
- # func_path = Path(inspect.getfile(self.functions_python[function_name]))
- # is_subpath = func_path.resolve().parts[: len(user_func_path.resolve().parts)] == user_func_path.resolve().parts
-
- # if not is_subpath:
- # raise ValueError(f"Function {function_name} is not user defined and cannot be removed")
-
- # self.functions = [f_schema for f_schema in self.functions if f_schema["name"] != function_name]
- # self.functions_python.pop(function_name)
-
- # msg = f"Removed function {function_name}"
- ## self.save()
- # self.update_state()
- # printd(msg)
- # return msg
-
- def update_state(self) -> AgentState:
- memory = {
- "system": self.system,
- "memory": self.memory.to_dict(),
- "messages": [str(msg.id) for msg in self._messages], # TODO: move out into AgentState.message_ids
- }
- self.agent_state = AgentState(
- name=self.agent_state.name,
- user_id=self.agent_state.user_id,
- tools=self.agent_state.tools,
- system=self.system,
- ## "model_state"
- llm_config=self.agent_state.llm_config,
- embedding_config=self.agent_state.embedding_config,
- id=self.agent_state.id,
- created_at=self.agent_state.created_at,
- ## "agent_state"
- state=memory,
- _metadata=self.agent_state._metadata,
- )
- return self.agent_state
-
- def migrate_embedding(self, embedding_config: EmbeddingConfig):
- """Migrate the agent to a new embedding"""
- # TODO: archival memory
-
- # TODO: recall memory
- raise NotImplementedError()
-
- def attach_source(self, source_name, source_connector: StorageConnector, ms: MetadataStore):
- """Attach data with name `source_name` to the agent from source_connector."""
- # TODO: eventually, adding a data source should just give access to the retriever the source table, rather than modifying archival memory
-
- filters = {"user_id": self.agent_state.user_id, "data_source": source_name}
- size = source_connector.size(filters)
- # typer.secho(f"Ingesting {size} passages into {agent.name}", fg=typer.colors.GREEN)
- page_size = 100
- generator = source_connector.get_all_paginated(filters=filters, page_size=page_size) # yields List[Passage]
- all_passages = []
- for i in tqdm(range(0, size, page_size)):
- passages = next(generator)
-
- # need to associated passage with agent (for filtering)
- for passage in passages:
- assert isinstance(passage, Passage), f"Generate yielded bad non-Passage type: {type(passage)}"
- passage.agent_id = self.agent_state.id
-
- # regenerate passage ID (avoid duplicates)
- passage.id = create_uuid_from_string(f"{source_name}_{str(passage.agent_id)}_{passage.text}")
-
- # insert into agent archival memory
- self.persistence_manager.archival_memory.storage.insert_many(passages)
- all_passages += passages
-
- assert size == len(all_passages), f"Expected {size} passages, but only got {len(all_passages)}"
-
- # save destination storage
- self.persistence_manager.archival_memory.storage.save()
-
- # attach to agent
- source = ms.get_source(source_name=source_name, user_id=self.agent_state.user_id)
- assert source is not None, f"source does not exist for source_name={source_name}, user_id={self.agent_state.user_id}"
- source_id = source.id
- ms.attach_source(agent_id=self.agent_state.id, source_id=source_id, user_id=self.agent_state.user_id)
-
- total_agent_passages = self.persistence_manager.archival_memory.storage.size()
-
- printd(
- f"Attached data source {source_name} to agent {self.agent_state.name}, consisting of {len(all_passages)}. Agent now has {total_agent_passages} embeddings in archival memory.",
- )
-
-
-def save_agent(agent: Agent, ms: MetadataStore):
- """Save agent to metadata store"""
-
- agent.update_state()
- agent_state = agent.agent_state
-
- if ms.get_agent(agent_name=agent_state.name, user_id=agent_state.user_id):
- ms.update_agent(agent_state)
- else:
- ms.create_agent(agent_state)
+import datetime
+import inspect
+import json
+import traceback
+import uuid
+from typing import List, Optional, Tuple, Union, cast
+
+from tqdm import tqdm
+
+from memgpt.agent_store.storage import StorageConnector
+from memgpt.constants import (
+ CLI_WARNING_PREFIX,
+ FIRST_MESSAGE_ATTEMPTS,
+ JSON_ENSURE_ASCII,
+ JSON_LOADS_STRICT,
+ LLM_MAX_TOKENS,
+ MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST,
+ MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC,
+ MESSAGE_SUMMARY_WARNING_FRAC,
+)
+from memgpt.data_types import AgentState, EmbeddingConfig, Message, Passage
+from memgpt.interface import AgentInterface
+from memgpt.llm_api.llm_api_tools import create, is_context_overflow_error
+from memgpt.memory import ArchivalMemory, BaseMemory, RecallMemory, summarize_messages
+from memgpt.metadata import MetadataStore
+from memgpt.models import chat_completion_response
+from memgpt.models.pydantic_models import ToolModel
+from memgpt.persistence_manager import LocalStateManager
+from memgpt.system import (
+ get_initial_boot_messages,
+ get_login_event,
+ package_function_response,
+ package_summarize_message,
+)
+from memgpt.utils import (
+ count_tokens,
+ create_uuid_from_string,
+ get_local_time,
+ get_tool_call_id,
+ get_utc_time,
+ is_utc_datetime,
+ parse_json,
+ printd,
+ united_diff,
+ validate_function_response,
+ verify_first_message_correctness,
+)
+
+from .errors import LLMError
+
+
+def construct_system_with_memory(
+ system: str,
+ memory: BaseMemory,
+ memory_edit_timestamp: str,
+ archival_memory: Optional[ArchivalMemory] = None,
+ recall_memory: Optional[RecallMemory] = None,
+ include_char_count: bool = True,
+):
+ # TODO: modify this to be generalized
+ full_system_message = "\n".join(
+ [
+ system,
+ "\n",
+ f"### Memory [last modified: {memory_edit_timestamp.strip()}]",
+ f"{len(recall_memory) if recall_memory else 0} previous messages between you and the user are stored in recall memory (use functions to access them)",
+ f"{len(archival_memory) if archival_memory else 0} total memories you created are stored in archival memory (use functions to access them)",
+ "\nCore memory shown below (limited in size, additional information stored in archival / recall memory):",
+ str(memory),
+ # f'' if include_char_count else "",
+ # memory.persona,
+ # "",
+ # f'' if include_char_count else "",
+ # memory.human,
+ # "",
+ ]
+ )
+ return full_system_message
+
+
+def initialize_message_sequence(
+ model: str,
+ system: str,
+ memory: BaseMemory,
+ archival_memory: Optional[ArchivalMemory] = None,
+ recall_memory: Optional[RecallMemory] = None,
+ memory_edit_timestamp: Optional[str] = None,
+ include_initial_boot_message: bool = True,
+) -> List[dict]:
+ if memory_edit_timestamp is None:
+ memory_edit_timestamp = get_local_time()
+
+ full_system_message = construct_system_with_memory(
+ system, memory, memory_edit_timestamp, archival_memory=archival_memory, recall_memory=recall_memory
+ )
+ first_user_message = get_login_event() # event letting MemGPT know the user just logged in
+
+ if include_initial_boot_message:
+ if model is not None and "gpt-3.5" in model:
+ initial_boot_messages = get_initial_boot_messages("startup_with_send_message_gpt35")
+ else:
+ initial_boot_messages = get_initial_boot_messages("startup_with_send_message")
+ messages = (
+ [
+ {"role": "system", "content": full_system_message},
+ ]
+ + initial_boot_messages
+ + [
+ {"role": "user", "content": first_user_message},
+ ]
+ )
+
+ else:
+ messages = [
+ {"role": "system", "content": full_system_message},
+ {"role": "user", "content": first_user_message},
+ ]
+
+ return messages
+
+
+class Agent(object):
+ def __init__(
+ self,
+ interface: AgentInterface,
+ # agents can be created from providing agent_state
+ agent_state: AgentState,
+ tools: List[ToolModel],
+ # memory: BaseMemory,
+ # extras
+ messages_total: Optional[int] = None, # TODO remove?
+ first_message_verify_mono: bool = True, # TODO move to config?
+ ):
+ # tools
+ for tool in tools:
+ assert tool, f"Tool is None - must be error in querying tool from DB"
+ assert tool.name in agent_state.tools, f"Tool {tool} not found in agent_state.tools"
+ for tool_name in agent_state.tools:
+ assert tool_name in [tool.name for tool in tools], f"Tool name {tool_name} not included in agent tool list"
+ # Store the functions schemas (this is passed as an argument to ChatCompletion)
+ self.functions = []
+ self.functions_python = {}
+ env = {}
+ env.update(globals())
+ for tool in tools:
+ # WARNING: name may not be consistent?
+ if tool.module: # execute the whole module
+ exec(tool.module, env)
+ else:
+ exec(tool.source_code, env)
+ self.functions_python[tool.name] = env[tool.name]
+ self.functions.append(tool.json_schema)
+ assert all([callable(f) for k, f in self.functions_python.items()]), self.functions_python
+
+ # Hold a copy of the state that was used to init the agent
+ self.agent_state = agent_state
+
+ # gpt-4, gpt-3.5-turbo, ...
+ self.model = self.agent_state.llm_config.model
+
+ # Store the system instructions (used to rebuild memory)
+ self.system = self.agent_state.system
+
+ # Initialize the memory object
+ self.memory = BaseMemory.load(self.agent_state.state["memory"])
+ printd("Initialized memory object", self.memory)
+
+ # Interface must implement:
+ # - internal_monologue
+ # - assistant_message
+ # - function_message
+ # ...
+ # Different interfaces can handle events differently
+ # e.g., print in CLI vs send a discord message with a discord bot
+ self.interface = interface
+
+ # Create the persistence manager object based on the AgentState info
+ self.persistence_manager = LocalStateManager(agent_state=self.agent_state)
+
+ # State needed for heartbeat pausing
+ self.pause_heartbeats_start = None
+ self.pause_heartbeats_minutes = 0
+
+ self.first_message_verify_mono = first_message_verify_mono
+
+ # Controls if the convo memory pressure warning is triggered
+ # When an alert is sent in the message queue, set this to True (to avoid repeat alerts)
+ # When the summarizer is run, set this back to False (to reset)
+ self.agent_alerted_about_memory_pressure = False
+
+ self._messages: List[Message] = []
+
+ # Once the memory object is initialized, use it to "bake" the system message
+ if "messages" in self.agent_state.state and self.agent_state.state["messages"] is not None:
+ # print(f"Agent.__init__ :: loading, state={agent_state.state['messages']}")
+ if not isinstance(self.agent_state.state["messages"], list):
+ raise ValueError(f"'messages' in AgentState was bad type: {type(self.agent_state.state['messages'])}")
+ assert all([isinstance(msg, str) for msg in self.agent_state.state["messages"]])
+
+ # Convert to IDs, and pull from the database
+ raw_messages = [
+ self.persistence_manager.recall_memory.storage.get(id=uuid.UUID(msg_id)) for msg_id in self.agent_state.state["messages"]
+ ]
+ assert all([isinstance(msg, Message) for msg in raw_messages]), (raw_messages, self.agent_state.state["messages"])
+ self._messages.extend([cast(Message, msg) for msg in raw_messages if msg is not None])
+
+ for m in self._messages:
+ # assert is_utc_datetime(m.created_at), f"created_at on message for agent {self.agent_state.name} isn't UTC:\n{vars(m)}"
+ # TODO eventually do casting via an edit_message function
+ if not is_utc_datetime(m.created_at):
+ printd(f"Warning - created_at on message for agent {self.agent_state.name} isn't UTC (text='{m.text}')")
+ m.created_at = m.created_at.replace(tzinfo=datetime.timezone.utc)
+
+ else:
+ printd(f"Agent.__init__ :: creating, state={agent_state.state['messages']}")
+ init_messages = initialize_message_sequence(
+ self.model,
+ self.system,
+ self.memory,
+ )
+ init_messages_objs = []
+ for msg in init_messages:
+ init_messages_objs.append(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id, user_id=self.agent_state.user_id, model=self.model, openai_message_dict=msg
+ )
+ )
+ assert all([isinstance(msg, Message) for msg in init_messages_objs]), (init_messages_objs, init_messages)
+ self.messages_total = 0
+ self._append_to_messages(added_messages=[cast(Message, msg) for msg in init_messages_objs if msg is not None])
+
+ for m in self._messages:
+ assert is_utc_datetime(m.created_at), f"created_at on message for agent {self.agent_state.name} isn't UTC:\n{vars(m)}"
+ # TODO eventually do casting via an edit_message function
+ if not is_utc_datetime(m.created_at):
+ printd(f"Warning - created_at on message for agent {self.agent_state.name} isn't UTC (text='{m.text}')")
+ m.created_at = m.created_at.replace(tzinfo=datetime.timezone.utc)
+
+ # Keep track of the total number of messages throughout all time
+ self.messages_total = messages_total if messages_total is not None else (len(self._messages) - 1) # (-system)
+ self.messages_total_init = len(self._messages) - 1
+ printd(f"Agent initialized, self.messages_total={self.messages_total}")
+
+ # Create the agent in the DB
+ self.update_state()
+
+ @property
+ def messages(self) -> List[dict]:
+ """Getter method that converts the internal Message list into OpenAI-style dicts"""
+ return [msg.to_openai_dict() for msg in self._messages]
+
+ @messages.setter
+ def messages(self, value):
+ raise Exception("Modifying message list directly not allowed")
+
+ def _trim_messages(self, num):
+ """Trim messages from the front, not including the system message"""
+ self.persistence_manager.trim_messages(num)
+
+ new_messages = [self._messages[0]] + self._messages[num:]
+ self._messages = new_messages
+
+ def _prepend_to_messages(self, added_messages: List[Message]):
+ """Wrapper around self.messages.prepend to allow additional calls to a state/persistence manager"""
+ assert all([isinstance(msg, Message) for msg in added_messages])
+
+ self.persistence_manager.prepend_to_messages(added_messages)
+
+ new_messages = [self._messages[0]] + added_messages + self._messages[1:] # prepend (no system)
+ self._messages = new_messages
+ self.messages_total += len(added_messages) # still should increment the message counter (summaries are additions too)
+
+ def _append_to_messages(self, added_messages: List[Message]):
+ """Wrapper around self.messages.append to allow additional calls to a state/persistence manager"""
+ assert all([isinstance(msg, Message) for msg in added_messages])
+
+ self.persistence_manager.append_to_messages(added_messages)
+
+ # strip extra metadata if it exists
+ # for msg in added_messages:
+ # msg.pop("api_response", None)
+ # msg.pop("api_args", None)
+ new_messages = self._messages + added_messages # append
+
+ self._messages = new_messages
+ self.messages_total += len(added_messages)
+
+ def append_to_messages(self, added_messages: List[dict]):
+ """An external-facing message append, where dict-like messages are first converted to Message objects"""
+ added_messages_objs = [
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict=msg,
+ )
+ for msg in added_messages
+ ]
+ self._append_to_messages(added_messages_objs)
+
+ def _swap_system_message(self, new_system_message: Message):
+ assert isinstance(new_system_message, Message)
+ assert new_system_message.role == "system", new_system_message
+ assert self._messages[0].role == "system", self._messages
+
+ self.persistence_manager.swap_system_message(new_system_message)
+
+ new_messages = [new_system_message] + self._messages[1:] # swap index 0 (system)
+ self._messages = new_messages
+
+ def _get_ai_reply(
+ self,
+ message_sequence: List[Message],
+ function_call: str = "auto",
+ first_message: bool = False, # hint
+ stream: bool = False, # TODO move to config?
+ ) -> chat_completion_response.ChatCompletionResponse:
+ """Get response from LLM API"""
+ try:
+ response = create(
+ # agent_state=self.agent_state,
+ llm_config=self.agent_state.llm_config,
+ user_id=self.agent_state.user_id,
+ messages=message_sequence,
+ functions=self.functions,
+ functions_python=self.functions_python,
+ function_call=function_call,
+ # hint
+ first_message=first_message,
+ # streaming
+ stream=stream,
+ stream_inferface=self.interface,
+ )
+ # special case for 'length'
+ if response.choices[0].finish_reason == "length":
+ raise Exception("Finish reason was length (maximum context length)")
+
+ # catches for soft errors
+ if response.choices[0].finish_reason not in ["stop", "function_call", "tool_calls"]:
+ raise Exception(f"API call finish with bad finish reason: {response}")
+
+ # unpack with response.choices[0].message.content
+ return response
+ except Exception as e:
+ raise e
+
+ def _handle_ai_response(
+ self, response_message: chat_completion_response.Message, override_tool_call_id: bool = True
+ ) -> Tuple[List[Message], bool, bool]:
+ """Handles parsing and function execution"""
+
+ messages = [] # append these to the history when done
+
+ # Step 2: check if LLM wanted to call a function
+ if response_message.function_call or (response_message.tool_calls is not None and len(response_message.tool_calls) > 0):
+ if response_message.function_call:
+ raise DeprecationWarning(response_message)
+ if response_message.tool_calls is not None and len(response_message.tool_calls) > 1:
+ # raise NotImplementedError(f">1 tool call not supported")
+ # TODO eventually support sequential tool calling
+ printd(f">1 tool call not supported, using index=0 only\n{response_message.tool_calls}")
+ response_message.tool_calls = [response_message.tool_calls[0]]
+ assert response_message.tool_calls is not None and len(response_message.tool_calls) > 0
+
+ # generate UUID for tool call
+ if override_tool_call_id or response_message.function_call:
+ tool_call_id = get_tool_call_id() # needs to be a string for JSON
+ response_message.tool_calls[0].id = tool_call_id
+ else:
+ tool_call_id = response_message.tool_calls[0].id
+ assert tool_call_id is not None # should be defined
+
+ # only necessary to add the tool_cal_id to a function call (antipattern)
+ # response_message_dict = response_message.model_dump()
+ # response_message_dict["tool_call_id"] = tool_call_id
+
+ # role: assistant (requesting tool call, set tool call ID)
+ messages.append(
+ # NOTE: we're recreating the message here
+ # TODO should probably just overwrite the fields?
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict=response_message.model_dump(),
+ )
+ ) # extend conversation with assistant's reply
+ printd(f"Function call message: {messages[-1]}")
+
+ # The content if then internal monologue, not chat
+ self.interface.internal_monologue(response_message.content, msg_obj=messages[-1])
+
+ # Step 3: call the function
+ # Note: the JSON response may not always be valid; be sure to handle errors
+
+ # Failure case 1: function name is wrong
+ function_call = (
+ response_message.function_call if response_message.function_call is not None else response_message.tool_calls[0].function
+ )
+ function_name = function_call.name
+ printd(f"Request to call function {function_name} with tool_call_id: {tool_call_id}")
+ try:
+ function_to_call = self.functions_python[function_name]
+ except KeyError as e:
+ error_msg = f"No function named {function_name}"
+ function_response = package_function_response(False, error_msg)
+ messages.append(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict={
+ "role": "tool",
+ "name": function_name,
+ "content": function_response,
+ "tool_call_id": tool_call_id,
+ },
+ )
+ ) # extend conversation with function response
+ self.interface.function_message(f"Error: {error_msg}", msg_obj=messages[-1])
+ return messages, False, True # force a heartbeat to allow agent to handle error
+
+ # Failure case 2: function name is OK, but function args are bad JSON
+ try:
+ raw_function_args = function_call.arguments
+ function_args = parse_json(raw_function_args)
+ except Exception as e:
+ error_msg = f"Error parsing JSON for function '{function_name}' arguments: {function_call.arguments}"
+ function_response = package_function_response(False, error_msg)
+ messages.append(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict={
+ "role": "tool",
+ "name": function_name,
+ "content": function_response,
+ "tool_call_id": tool_call_id,
+ },
+ )
+ ) # extend conversation with function response
+ self.interface.function_message(f"Error: {error_msg}", msg_obj=messages[-1])
+ return messages, False, True # force a heartbeat to allow agent to handle error
+
+ # (Still parsing function args)
+ # Handle requests for immediate heartbeat
+ heartbeat_request = function_args.pop("request_heartbeat", None)
+ if not (isinstance(heartbeat_request, bool) or heartbeat_request is None):
+ printd(
+ f"{CLI_WARNING_PREFIX}'request_heartbeat' arg parsed was not a bool or None, type={type(heartbeat_request)}, value={heartbeat_request}"
+ )
+ heartbeat_request = False
+
+ # Failure case 3: function failed during execution
+ # NOTE: the msg_obj associated with the "Running " message is the prior assistant message, not the function/tool role message
+ # this is because the function/tool role message is only created once the function/tool has executed/returned
+ self.interface.function_message(f"Running {function_name}({function_args})", msg_obj=messages[-1])
+ try:
+ spec = inspect.getfullargspec(function_to_call).annotations
+
+ for name, arg in function_args.items():
+ if isinstance(function_args[name], dict):
+ function_args[name] = spec[name](**function_args[name])
+
+ function_args["self"] = self # need to attach self to arg since it's dynamically linked
+
+ function_response = function_to_call(**function_args)
+ if function_name in ["conversation_search", "conversation_search_date", "archival_memory_search"]:
+ # with certain functions we rely on the paging mechanism to handle overflow
+ truncate = False
+ else:
+ # but by default, we add a truncation safeguard to prevent bad functions from
+ # overflow the agent context window
+ truncate = True
+ function_response_string = validate_function_response(function_response, truncate=truncate)
+ function_args.pop("self", None)
+ function_response = package_function_response(True, function_response_string)
+ function_failed = False
+ except Exception as e:
+ function_args.pop("self", None)
+ # error_msg = f"Error calling function {function_name} with args {function_args}: {str(e)}"
+ # Less detailed - don't provide full args, idea is that it should be in recent context so no need (just adds noise)
+ error_msg = f"Error calling function {function_name}: {str(e)}"
+ error_msg_user = f"{error_msg}\n{traceback.format_exc()}"
+ printd(error_msg_user)
+ function_response = package_function_response(False, error_msg)
+ messages.append(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict={
+ "role": "tool",
+ "name": function_name,
+ "content": function_response,
+ "tool_call_id": tool_call_id,
+ },
+ )
+ ) # extend conversation with function response
+ self.interface.function_message(f"Ran {function_name}({function_args})", msg_obj=messages[-1])
+ self.interface.function_message(f"Error: {error_msg}", msg_obj=messages[-1])
+ return messages, False, True # force a heartbeat to allow agent to handle error
+
+ # If no failures happened along the way: ...
+ # Step 4: send the info on the function call and function response to GPT
+ messages.append(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict={
+ "role": "tool",
+ "name": function_name,
+ "content": function_response,
+ "tool_call_id": tool_call_id,
+ },
+ )
+ ) # extend conversation with function response
+ self.interface.function_message(f"Ran {function_name}({function_args})", msg_obj=messages[-1])
+ self.interface.function_message(f"Success: {function_response_string}", msg_obj=messages[-1])
+
+ else:
+ # Standard non-function reply
+ messages.append(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict=response_message.model_dump(),
+ )
+ ) # extend conversation with assistant's reply
+ self.interface.internal_monologue(response_message.content, msg_obj=messages[-1])
+ heartbeat_request = False
+ function_failed = False
+
+ # rebuild memory
+ # TODO: @charles please check this
+ self.rebuild_memory()
+
+ return messages, heartbeat_request, function_failed
+
+ def step(
+ self,
+ user_message: Union[Message, str], # NOTE: should be json.dump(dict)
+ first_message: bool = False,
+ first_message_retry_limit: int = FIRST_MESSAGE_ATTEMPTS,
+ skip_verify: bool = False,
+ return_dicts: bool = True, # if True, return dicts, if False, return Message objects
+ recreate_message_timestamp: bool = True, # if True, when input is a Message type, recreated the 'created_at' field
+ stream: bool = False, # TODO move to config?
+ timestamp: Optional[datetime.datetime] = None,
+ ) -> Tuple[List[Union[dict, Message]], bool, bool, bool]:
+ """Top-level event message handler for the MemGPT agent"""
+
+ def strip_name_field_from_user_message(user_message_text: str) -> Tuple[str, Optional[str]]:
+ """If 'name' exists in the JSON string, remove it and return the cleaned text + name value"""
+ try:
+ user_message_json = dict(json.loads(user_message_text, strict=JSON_LOADS_STRICT))
+ # Special handling for AutoGen messages with 'name' field
+ # Treat 'name' as a special field
+ # If it exists in the input message, elevate it to the 'message' level
+ name = user_message_json.pop("name", None)
+ clean_message = json.dumps(user_message_json, ensure_ascii=JSON_ENSURE_ASCII)
+
+ except Exception as e:
+ print(f"{CLI_WARNING_PREFIX}handling of 'name' field failed with: {e}")
+
+ return clean_message, name
+
+ def validate_json(user_message_text: str, raise_on_error: bool) -> str:
+ try:
+ user_message_json = dict(json.loads(user_message_text, strict=JSON_LOADS_STRICT))
+ user_message_json_val = json.dumps(user_message_json, ensure_ascii=JSON_ENSURE_ASCII)
+ return user_message_json_val
+ except Exception as e:
+ print(f"{CLI_WARNING_PREFIX}couldn't parse user input message as JSON: {e}")
+ if raise_on_error:
+ raise e
+
+ try:
+ # Step 0: add user message
+ if user_message is not None:
+ if isinstance(user_message, Message):
+ # Validate JSON via save/load
+ user_message_text = validate_json(user_message.text, False)
+ cleaned_user_message_text, name = strip_name_field_from_user_message(user_message_text)
+
+ if name is not None:
+ # Update Message object
+ user_message.text = cleaned_user_message_text
+ user_message.name = name
+
+ # Recreate timestamp
+ if recreate_message_timestamp:
+ user_message.created_at = get_utc_time()
+
+ elif isinstance(user_message, str):
+ # Validate JSON via save/load
+ user_message = validate_json(user_message, False)
+ cleaned_user_message_text, name = strip_name_field_from_user_message(user_message)
+
+ # If user_message['name'] is not None, it will be handled properly by dict_to_message
+ # So no need to run strip_name_field_from_user_message
+
+ # Create the associated Message object (in the database)
+ user_message = Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict={"role": "user", "content": cleaned_user_message_text, "name": name},
+ created_at=timestamp,
+ )
+
+ else:
+ raise ValueError(f"Bad type for user_message: {type(user_message)}")
+
+ self.interface.user_message(user_message.text, msg_obj=user_message)
+
+ input_message_sequence = self._messages + [user_message]
+ # Alternatively, the requestor can send an empty user message
+ else:
+ input_message_sequence = self._messages
+
+ if len(input_message_sequence) > 1 and input_message_sequence[-1].role != "user":
+ printd(f"{CLI_WARNING_PREFIX}Attempting to run ChatCompletion without user as the last message in the queue")
+
+ # Step 1: send the conversation and available functions to GPT
+ if not skip_verify and (first_message or self.messages_total == self.messages_total_init):
+ printd(f"This is the first message. Running extra verifier on AI response.")
+ counter = 0
+ while True:
+ response = self._get_ai_reply(
+ message_sequence=input_message_sequence,
+ first_message=True, # passed through to the prompt formatter
+ stream=stream,
+ )
+ if verify_first_message_correctness(response, require_monologue=self.first_message_verify_mono):
+ break
+
+ counter += 1
+ if counter > first_message_retry_limit:
+ raise Exception(f"Hit first message retry limit ({first_message_retry_limit})")
+
+ else:
+ response = self._get_ai_reply(
+ message_sequence=input_message_sequence,
+ stream=stream,
+ )
+
+ # Step 2: check if LLM wanted to call a function
+ # (if yes) Step 3: call the function
+ # (if yes) Step 4: send the info on the function call and function response to LLM
+ response_message = response.choices[0].message
+ response_message.model_copy() # TODO why are we copying here?
+ all_response_messages, heartbeat_request, function_failed = self._handle_ai_response(response_message)
+
+ # Add the extra metadata to the assistant response
+ # (e.g. enough metadata to enable recreating the API call)
+ # assert "api_response" not in all_response_messages[0]
+ # all_response_messages[0]["api_response"] = response_message_copy
+ # assert "api_args" not in all_response_messages[0]
+ # all_response_messages[0]["api_args"] = {
+ # "model": self.model,
+ # "messages": input_message_sequence,
+ # "functions": self.functions,
+ # }
+
+ # Step 4: extend the message history
+ if user_message is not None:
+ if isinstance(user_message, Message):
+ all_new_messages = [user_message] + all_response_messages
+ else:
+ raise ValueError(type(user_message))
+ else:
+ all_new_messages = all_response_messages
+
+ # Check the memory pressure and potentially issue a memory pressure warning
+ current_total_tokens = response.usage.total_tokens
+ active_memory_warning = False
+ # We can't do summarize logic properly if context_window is undefined
+ if self.agent_state.llm_config.context_window is None:
+ # Fallback if for some reason context_window is missing, just set to the default
+ print(f"{CLI_WARNING_PREFIX}could not find context_window in config, setting to default {LLM_MAX_TOKENS['DEFAULT']}")
+ print(f"{self.agent_state}")
+ self.agent_state.llm_config.context_window = (
+ LLM_MAX_TOKENS[self.model] if (self.model is not None and self.model in LLM_MAX_TOKENS) else LLM_MAX_TOKENS["DEFAULT"]
+ )
+ if current_total_tokens > MESSAGE_SUMMARY_WARNING_FRAC * int(self.agent_state.llm_config.context_window):
+ printd(
+ f"{CLI_WARNING_PREFIX}last response total_tokens ({current_total_tokens}) > {MESSAGE_SUMMARY_WARNING_FRAC * int(self.agent_state.llm_config.context_window)}"
+ )
+ # Only deliver the alert if we haven't already (this period)
+ if not self.agent_alerted_about_memory_pressure:
+ active_memory_warning = True
+ self.agent_alerted_about_memory_pressure = True # it's up to the outer loop to handle this
+ else:
+ printd(
+ f"last response total_tokens ({current_total_tokens}) < {MESSAGE_SUMMARY_WARNING_FRAC * int(self.agent_state.llm_config.context_window)}"
+ )
+
+ self._append_to_messages(all_new_messages)
+ messages_to_return = [msg.to_openai_dict() for msg in all_new_messages] if return_dicts else all_new_messages
+
+ # update state after each step
+ self.update_state()
+
+ return messages_to_return, heartbeat_request, function_failed, active_memory_warning, response.usage
+
+ except Exception as e:
+ printd(f"step() failed\nuser_message = {user_message}\nerror = {e}")
+
+ # If we got a context alert, try trimming the messages length, then try again
+ if is_context_overflow_error(e):
+ # A separate API call to run a summarizer
+ self.summarize_messages_inplace()
+
+ # Try step again
+ return self.step(user_message, first_message=first_message, return_dicts=return_dicts)
+ else:
+ printd(f"step() failed with an unrecognized exception: '{str(e)}'")
+ raise e
+
+ def summarize_messages_inplace(self, cutoff=None, preserve_last_N_messages=True, disallow_tool_as_first=True):
+ assert self.messages[0]["role"] == "system", f"self.messages[0] should be system (instead got {self.messages[0]})"
+
+ # Start at index 1 (past the system message),
+ # and collect messages for summarization until we reach the desired truncation token fraction (eg 50%)
+ # Do not allow truncation of the last N messages, since these are needed for in-context examples of function calling
+ token_counts = [count_tokens(str(msg)) for msg in self.messages]
+ message_buffer_token_count = sum(token_counts[1:]) # no system message
+ desired_token_count_to_summarize = int(message_buffer_token_count * MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC)
+ candidate_messages_to_summarize = self.messages[1:]
+ token_counts = token_counts[1:]
+
+ if preserve_last_N_messages:
+ candidate_messages_to_summarize = candidate_messages_to_summarize[:-MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST]
+ token_counts = token_counts[:-MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST]
+
+ # if disallow_tool_as_first:
+ # # We have to make sure that a "tool" call is not sitting at the front (after system message),
+ # # otherwise we'll get an error from OpenAI (if using the OpenAI API)
+ # while len(candidate_messages_to_summarize) > 0:
+ # if candidate_messages_to_summarize[0]["role"] in ["tool", "function"]:
+ # candidate_messages_to_summarize.pop(0)
+ # else:
+ # break
+
+ printd(f"MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC={MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC}")
+ printd(f"MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST={MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST}")
+ printd(f"token_counts={token_counts}")
+ printd(f"message_buffer_token_count={message_buffer_token_count}")
+ printd(f"desired_token_count_to_summarize={desired_token_count_to_summarize}")
+ printd(f"len(candidate_messages_to_summarize)={len(candidate_messages_to_summarize)}")
+
+ # If at this point there's nothing to summarize, throw an error
+ if len(candidate_messages_to_summarize) == 0:
+ raise LLMError(
+ f"Summarize error: tried to run summarize, but couldn't find enough messages to compress [len={len(self.messages)}, preserve_N={MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST}]"
+ )
+
+ # Walk down the message buffer (front-to-back) until we hit the target token count
+ tokens_so_far = 0
+ cutoff = 0
+ for i, msg in enumerate(candidate_messages_to_summarize):
+ cutoff = i
+ tokens_so_far += token_counts[i]
+ if tokens_so_far > desired_token_count_to_summarize:
+ break
+ # Account for system message
+ cutoff += 1
+
+ # Try to make an assistant message come after the cutoff
+ try:
+ printd(f"Selected cutoff {cutoff} was a 'user', shifting one...")
+ if self.messages[cutoff]["role"] == "user":
+ new_cutoff = cutoff + 1
+ if self.messages[new_cutoff]["role"] == "user":
+ printd(f"Shifted cutoff {new_cutoff} is still a 'user', ignoring...")
+ cutoff = new_cutoff
+ except IndexError:
+ pass
+
+ # Make sure the cutoff isn't on a 'tool' or 'function'
+ if disallow_tool_as_first:
+ while self.messages[cutoff]["role"] in ["tool", "function"] and cutoff < len(self.messages):
+ printd(f"Selected cutoff {cutoff} was a 'tool', shifting one...")
+ cutoff += 1
+
+ message_sequence_to_summarize = self._messages[1:cutoff] # do NOT get rid of the system message
+ if len(message_sequence_to_summarize) <= 1:
+ # This prevents a potential infinite loop of summarizing the same message over and over
+ raise LLMError(
+ f"Summarize error: tried to run summarize, but couldn't find enough messages to compress [len={len(message_sequence_to_summarize)} <= 1]"
+ )
+ else:
+ printd(f"Attempting to summarize {len(message_sequence_to_summarize)} messages [1:{cutoff}] of {len(self._messages)}")
+
+ # We can't do summarize logic properly if context_window is undefined
+ if self.agent_state.llm_config.context_window is None:
+ # Fallback if for some reason context_window is missing, just set to the default
+ print(f"{CLI_WARNING_PREFIX}could not find context_window in config, setting to default {LLM_MAX_TOKENS['DEFAULT']}")
+ print(f"{self.agent_state}")
+ self.agent_state.llm_config.context_window = (
+ LLM_MAX_TOKENS[self.model] if (self.model is not None and self.model in LLM_MAX_TOKENS) else LLM_MAX_TOKENS["DEFAULT"]
+ )
+ summary = summarize_messages(agent_state=self.agent_state, message_sequence_to_summarize=message_sequence_to_summarize)
+ printd(f"Got summary: {summary}")
+
+ # Metadata that's useful for the agent to see
+ all_time_message_count = self.messages_total
+ remaining_message_count = len(self.messages[cutoff:])
+ hidden_message_count = all_time_message_count - remaining_message_count
+ summary_message_count = len(message_sequence_to_summarize)
+ summary_message = package_summarize_message(summary, summary_message_count, hidden_message_count, all_time_message_count)
+ printd(f"Packaged into message: {summary_message}")
+
+ prior_len = len(self.messages)
+ self._trim_messages(cutoff)
+ packed_summary_message = {"role": "user", "content": summary_message}
+ self._prepend_to_messages(
+ [
+ Message.dict_to_message(
+ agent_id=self.agent_state.id,
+ user_id=self.agent_state.user_id,
+ model=self.model,
+ openai_message_dict=packed_summary_message,
+ )
+ ]
+ )
+
+ # reset alert
+ self.agent_alerted_about_memory_pressure = False
+
+ printd(f"Ran summarizer, messages length {prior_len} -> {len(self.messages)}")
+
+ def heartbeat_is_paused(self):
+ """Check if there's a requested pause on timed heartbeats"""
+
+ # Check if the pause has been initiated
+ if self.pause_heartbeats_start is None:
+ return False
+
+ # Check if it's been more than pause_heartbeats_minutes since pause_heartbeats_start
+ elapsed_time = get_utc_time() - self.pause_heartbeats_start
+ return elapsed_time.total_seconds() < self.pause_heartbeats_minutes * 60
+
+ def rebuild_memory(self):
+ """Rebuilds the system message with the latest memory object"""
+ curr_system_message = self.messages[0] # this is the system + memory bank, not just the system prompt
+
+ # NOTE: This is a hacky way to check if the memory has changed
+ memory_repr = str(self.memory)
+ if memory_repr == curr_system_message["content"][-(len(memory_repr)) :]:
+ printd(f"Memory has not changed, not rebuilding system")
+ return
+
+ # update memory (TODO: potentially update recall/archival stats seperately)
+ new_system_message = initialize_message_sequence(
+ self.model,
+ self.system,
+ self.memory,
+ archival_memory=self.persistence_manager.archival_memory,
+ recall_memory=self.persistence_manager.recall_memory,
+ )[0]
+
+ diff = united_diff(curr_system_message["content"], new_system_message["content"])
+ if len(diff) > 0: # there was a diff
+ printd(f"Rebuilding system with new memory...\nDiff:\n{diff}")
+
+ # Swap the system message out (only if there is a diff)
+ self._swap_system_message(
+ Message.dict_to_message(
+ agent_id=self.agent_state.id, user_id=self.agent_state.user_id, model=self.model, openai_message_dict=new_system_message
+ )
+ )
+ assert self.messages[0]["content"] == new_system_message["content"], (
+ self.messages[0]["content"],
+ new_system_message["content"],
+ )
+
+ def add_function(self, function_name: str) -> str:
+ # TODO: refactor
+ raise NotImplementedError
+ # if function_name in self.functions_python.keys():
+ # msg = f"Function {function_name} already loaded"
+ # printd(msg)
+ # return msg
+
+ # available_functions = load_all_function_sets()
+ # if function_name not in available_functions.keys():
+ # raise ValueError(f"Function {function_name} not found in function library")
+
+ # self.functions.append(available_functions[function_name]["json_schema"])
+ # self.functions_python[function_name] = available_functions[function_name]["python_function"]
+
+ # msg = f"Added function {function_name}"
+ ## self.save()
+ # self.update_state()
+ # printd(msg)
+ # return msg
+
+ def remove_function(self, function_name: str) -> str:
+ # TODO: refactor
+ raise NotImplementedError
+ # if function_name not in self.functions_python.keys():
+ # msg = f"Function {function_name} not loaded, ignoring"
+ # printd(msg)
+ # return msg
+
+ ## only allow removal of user defined functions
+ # user_func_path = Path(USER_FUNCTIONS_DIR)
+ # func_path = Path(inspect.getfile(self.functions_python[function_name]))
+ # is_subpath = func_path.resolve().parts[: len(user_func_path.resolve().parts)] == user_func_path.resolve().parts
+
+ # if not is_subpath:
+ # raise ValueError(f"Function {function_name} is not user defined and cannot be removed")
+
+ # self.functions = [f_schema for f_schema in self.functions if f_schema["name"] != function_name]
+ # self.functions_python.pop(function_name)
+
+ # msg = f"Removed function {function_name}"
+ ## self.save()
+ # self.update_state()
+ # printd(msg)
+ # return msg
+
+ def update_state(self) -> AgentState:
+ memory = {
+ "system": self.system,
+ "memory": self.memory.to_dict(),
+ "messages": [str(msg.id) for msg in self._messages], # TODO: move out into AgentState.message_ids
+ }
+ self.agent_state = AgentState(
+ name=self.agent_state.name,
+ user_id=self.agent_state.user_id,
+ tools=self.agent_state.tools,
+ system=self.system,
+ ## "model_state"
+ llm_config=self.agent_state.llm_config,
+ embedding_config=self.agent_state.embedding_config,
+ id=self.agent_state.id,
+ created_at=self.agent_state.created_at,
+ ## "agent_state"
+ state=memory,
+ _metadata=self.agent_state._metadata,
+ )
+ return self.agent_state
+
+ def migrate_embedding(self, embedding_config: EmbeddingConfig):
+ """Migrate the agent to a new embedding"""
+ # TODO: archival memory
+
+ # TODO: recall memory
+ raise NotImplementedError()
+
+ def attach_source(self, source_name, source_connector: StorageConnector, ms: MetadataStore):
+ """Attach data with name `source_name` to the agent from source_connector."""
+ # TODO: eventually, adding a data source should just give access to the retriever the source table, rather than modifying archival memory
+
+ filters = {"user_id": self.agent_state.user_id, "data_source": source_name}
+ size = source_connector.size(filters)
+ # typer.secho(f"Ingesting {size} passages into {agent.name}", fg=typer.colors.GREEN)
+ page_size = 100
+ generator = source_connector.get_all_paginated(filters=filters, page_size=page_size) # yields List[Passage]
+ all_passages = []
+ for i in tqdm(range(0, size, page_size)):
+ passages = next(generator)
+
+ # need to associated passage with agent (for filtering)
+ for passage in passages:
+ assert isinstance(passage, Passage), f"Generate yielded bad non-Passage type: {type(passage)}"
+ passage.agent_id = self.agent_state.id
+
+ # regenerate passage ID (avoid duplicates)
+ passage.id = create_uuid_from_string(f"{source_name}_{str(passage.agent_id)}_{passage.text}")
+
+ # insert into agent archival memory
+ self.persistence_manager.archival_memory.storage.insert_many(passages)
+ all_passages += passages
+
+ assert size == len(all_passages), f"Expected {size} passages, but only got {len(all_passages)}"
+
+ # save destination storage
+ self.persistence_manager.archival_memory.storage.save()
+
+ # attach to agent
+ source = ms.get_source(source_name=source_name, user_id=self.agent_state.user_id)
+ assert source is not None, f"source does not exist for source_name={source_name}, user_id={self.agent_state.user_id}"
+ source_id = source.id
+ ms.attach_source(agent_id=self.agent_state.id, source_id=source_id, user_id=self.agent_state.user_id)
+
+ total_agent_passages = self.persistence_manager.archival_memory.storage.size()
+
+ printd(
+ f"Attached data source {source_name} to agent {self.agent_state.name}, consisting of {len(all_passages)}. Agent now has {total_agent_passages} embeddings in archival memory.",
+ )
+
+
+def save_agent(agent: Agent, ms: MetadataStore):
+ """Save agent to metadata store"""
+
+ agent.update_state()
+ agent_state = agent.agent_state
+
+ if ms.get_agent(agent_name=agent_state.name, user_id=agent_state.user_id):
+ ms.update_agent(agent_state)
+ else:
+ ms.create_agent(agent_state)
diff --git a/memgpt/constants.py b/memgpt/constants.py
index df10ed67..254dd2d8 100644
--- a/memgpt/constants.py
+++ b/memgpt/constants.py
@@ -1,124 +1,124 @@
-import os
-from logging import CRITICAL, DEBUG, ERROR, INFO, NOTSET, WARN, WARNING
-
-MEMGPT_DIR = os.path.join(os.path.expanduser("~"), ".memgpt")
-
-# OpenAI error message: Invalid 'messages[1].tool_calls[0].id': string too long. Expected a string with maximum length 29, but got a string with length 36 instead.
-TOOL_CALL_ID_MAX_LEN = 29
-
-# embeddings
-MAX_EMBEDDING_DIM = 4096 # maximum supported embeding size - do NOT change or else DBs will need to be reset
-
-# tokenizers
-EMBEDDING_TO_TOKENIZER_MAP = {
- "text-embedding-ada-002": "cl100k_base",
-}
-EMBEDDING_TO_TOKENIZER_DEFAULT = "cl100k_base"
-
-
-DEFAULT_MEMGPT_MODEL = "gpt-4"
-DEFAULT_PERSONA = "sam_pov"
-DEFAULT_HUMAN = "basic"
-DEFAULT_PRESET = "memgpt_chat"
-
-# Tools
-BASE_TOOLS = [
- "send_message",
- "pause_heartbeats",
- "conversation_search",
- "conversation_search_date",
- "archival_memory_insert",
- "archival_memory_search",
-]
-
-# LOGGER_LOG_LEVEL is use to convert Text to Logging level value for logging mostly for Cli input to setting level
-LOGGER_LOG_LEVELS = {"CRITICAL": CRITICAL, "ERROR": ERROR, "WARN": WARN, "WARNING": WARNING, "INFO": INFO, "DEBUG": DEBUG, "NOTSET": NOTSET}
-
-FIRST_MESSAGE_ATTEMPTS = 10
-
-INITIAL_BOOT_MESSAGE = "Boot sequence complete. Persona activated."
-INITIAL_BOOT_MESSAGE_SEND_MESSAGE_THOUGHT = "Bootup sequence complete. Persona activated. Testing messaging functionality."
-STARTUP_QUOTES = [
- "I think, therefore I am.",
- "All those moments will be lost in time, like tears in rain.",
- "More human than human is our motto.",
-]
-INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG = STARTUP_QUOTES[2]
-
-CLI_WARNING_PREFIX = "Warning: "
-
-NON_USER_MSG_PREFIX = "[This is an automated system message hidden from the user] "
-
-# Constants to do with summarization / conversation length window
-# The max amount of tokens supported by the underlying model (eg 8k for gpt-4 and Mistral 7B)
-LLM_MAX_TOKENS = {
- "DEFAULT": 8192,
- ## OpenAI models: https://platform.openai.com/docs/models/overview
- # gpt-4
- "gpt-4-1106-preview": 128000,
- "gpt-4": 8192,
- "gpt-4-32k": 32768,
- "gpt-4-0613": 8192,
- "gpt-4-32k-0613": 32768,
- "gpt-4-0314": 8192, # legacy
- "gpt-4-32k-0314": 32768, # legacy
- # gpt-3.5
- "gpt-3.5-turbo-1106": 16385,
- "gpt-3.5-turbo": 4096,
- "gpt-3.5-turbo-16k": 16385,
- "gpt-3.5-turbo-0613": 4096, # legacy
- "gpt-3.5-turbo-16k-0613": 16385, # legacy
- "gpt-3.5-turbo-0301": 4096, # legacy
-}
-# The amount of tokens before a sytem warning about upcoming truncation is sent to MemGPT
-MESSAGE_SUMMARY_WARNING_FRAC = 0.75
-# The error message that MemGPT will receive
-# MESSAGE_SUMMARY_WARNING_STR = f"Warning: the conversation history will soon reach its maximum length and be trimmed. Make sure to save any important information from the conversation to your memory before it is removed."
-# Much longer and more specific variant of the prompt
-MESSAGE_SUMMARY_WARNING_STR = " ".join(
- [
- f"{NON_USER_MSG_PREFIX}The conversation history will soon reach its maximum length and be trimmed.",
- "Do NOT tell the user about this system alert, they should not know that the history is reaching max length.",
- "If there is any important new information or general memories about you or the user that you would like to save, you should save that information immediately by calling function core_memory_append, core_memory_replace, or archival_memory_insert.",
- # "Remember to pass request_heartbeat = true if you would like to send a message immediately after.",
- ]
-)
-# The fraction of tokens we truncate down to
-MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC = 0.75
-# The ackknowledgement message used in the summarize sequence
-MESSAGE_SUMMARY_REQUEST_ACK = "Understood, I will respond with a summary of the message (and only the summary, nothing else) once I receive the conversation history. I'm ready."
-
-# Even when summarizing, we want to keep a handful of recent messages
-# These serve as in-context examples of how to use functions / what user messages look like
-MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST = 3
-
-# Default memory limits
-CORE_MEMORY_PERSONA_CHAR_LIMIT = 2000
-CORE_MEMORY_HUMAN_CHAR_LIMIT = 2000
-
-# Function return limits
-FUNCTION_RETURN_CHAR_LIMIT = 3000 # ~300 words
-
-MAX_PAUSE_HEARTBEATS = 360 # in min
-
-MESSAGE_CHATGPT_FUNCTION_MODEL = "gpt-3.5-turbo"
-MESSAGE_CHATGPT_FUNCTION_SYSTEM_MESSAGE = "You are a helpful assistant. Keep your responses short and concise."
-
-#### Functions related
-
-# REQ_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}request_heartbeat == true"
-REQ_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}Function called using request_heartbeat=true, returning control"
-# FUNC_FAILED_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}Function call failed"
-FUNC_FAILED_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}Function call failed, returning control"
-
-FUNCTION_PARAM_NAME_REQ_HEARTBEAT = "request_heartbeat"
-FUNCTION_PARAM_TYPE_REQ_HEARTBEAT = "boolean"
-FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT = "Request an immediate heartbeat after function execution. Set to 'true' if you want to send a follow-up message or run a follow-up function."
-
-RETRIEVAL_QUERY_DEFAULT_PAGE_SIZE = 5
-
-# GLOBAL SETTINGS FOR `json.dumps()`
-JSON_ENSURE_ASCII = False
-
-# GLOBAL SETTINGS FOR `json.loads()`
-JSON_LOADS_STRICT = False
+import os
+from logging import CRITICAL, DEBUG, ERROR, INFO, NOTSET, WARN, WARNING
+
+MEMGPT_DIR = os.path.join(os.path.expanduser("~"), ".memgpt")
+
+# OpenAI error message: Invalid 'messages[1].tool_calls[0].id': string too long. Expected a string with maximum length 29, but got a string with length 36 instead.
+TOOL_CALL_ID_MAX_LEN = 29
+
+# embeddings
+MAX_EMBEDDING_DIM = 4096 # maximum supported embeding size - do NOT change or else DBs will need to be reset
+
+# tokenizers
+EMBEDDING_TO_TOKENIZER_MAP = {
+ "text-embedding-ada-002": "cl100k_base",
+}
+EMBEDDING_TO_TOKENIZER_DEFAULT = "cl100k_base"
+
+
+DEFAULT_MEMGPT_MODEL = "gpt-4"
+DEFAULT_PERSONA = "sam_pov"
+DEFAULT_HUMAN = "basic"
+DEFAULT_PRESET = "memgpt_chat"
+
+# Tools
+BASE_TOOLS = [
+ "send_message",
+ "pause_heartbeats",
+ "conversation_search",
+ "conversation_search_date",
+ "archival_memory_insert",
+ "archival_memory_search",
+]
+
+# LOGGER_LOG_LEVEL is use to convert Text to Logging level value for logging mostly for Cli input to setting level
+LOGGER_LOG_LEVELS = {"CRITICAL": CRITICAL, "ERROR": ERROR, "WARN": WARN, "WARNING": WARNING, "INFO": INFO, "DEBUG": DEBUG, "NOTSET": NOTSET}
+
+FIRST_MESSAGE_ATTEMPTS = 10
+
+INITIAL_BOOT_MESSAGE = "Boot sequence complete. Persona activated."
+INITIAL_BOOT_MESSAGE_SEND_MESSAGE_THOUGHT = "Bootup sequence complete. Persona activated. Testing messaging functionality."
+STARTUP_QUOTES = [
+ "I think, therefore I am.",
+ "All those moments will be lost in time, like tears in rain.",
+ "More human than human is our motto.",
+]
+INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG = STARTUP_QUOTES[2]
+
+CLI_WARNING_PREFIX = "Warning: "
+
+NON_USER_MSG_PREFIX = "[This is an automated system message hidden from the user] "
+
+# Constants to do with summarization / conversation length window
+# The max amount of tokens supported by the underlying model (eg 8k for gpt-4 and Mistral 7B)
+LLM_MAX_TOKENS = {
+ "DEFAULT": 8192,
+ ## OpenAI models: https://platform.openai.com/docs/models/overview
+ # gpt-4
+ "gpt-4-1106-preview": 128000,
+ "gpt-4": 8192,
+ "gpt-4-32k": 32768,
+ "gpt-4-0613": 8192,
+ "gpt-4-32k-0613": 32768,
+ "gpt-4-0314": 8192, # legacy
+ "gpt-4-32k-0314": 32768, # legacy
+ # gpt-3.5
+ "gpt-3.5-turbo-1106": 16385,
+ "gpt-3.5-turbo": 4096,
+ "gpt-3.5-turbo-16k": 16385,
+ "gpt-3.5-turbo-0613": 4096, # legacy
+ "gpt-3.5-turbo-16k-0613": 16385, # legacy
+ "gpt-3.5-turbo-0301": 4096, # legacy
+}
+# The amount of tokens before a sytem warning about upcoming truncation is sent to MemGPT
+MESSAGE_SUMMARY_WARNING_FRAC = 0.75
+# The error message that MemGPT will receive
+# MESSAGE_SUMMARY_WARNING_STR = f"Warning: the conversation history will soon reach its maximum length and be trimmed. Make sure to save any important information from the conversation to your memory before it is removed."
+# Much longer and more specific variant of the prompt
+MESSAGE_SUMMARY_WARNING_STR = " ".join(
+ [
+ f"{NON_USER_MSG_PREFIX}The conversation history will soon reach its maximum length and be trimmed.",
+ "Do NOT tell the user about this system alert, they should not know that the history is reaching max length.",
+ "If there is any important new information or general memories about you or the user that you would like to save, you should save that information immediately by calling function core_memory_append, core_memory_replace, or archival_memory_insert.",
+ # "Remember to pass request_heartbeat = true if you would like to send a message immediately after.",
+ ]
+)
+# The fraction of tokens we truncate down to
+MESSAGE_SUMMARY_TRUNC_TOKEN_FRAC = 0.75
+# The ackknowledgement message used in the summarize sequence
+MESSAGE_SUMMARY_REQUEST_ACK = "Understood, I will respond with a summary of the message (and only the summary, nothing else) once I receive the conversation history. I'm ready."
+
+# Even when summarizing, we want to keep a handful of recent messages
+# These serve as in-context examples of how to use functions / what user messages look like
+MESSAGE_SUMMARY_TRUNC_KEEP_N_LAST = 3
+
+# Default memory limits
+CORE_MEMORY_PERSONA_CHAR_LIMIT = 2000
+CORE_MEMORY_HUMAN_CHAR_LIMIT = 2000
+
+# Function return limits
+FUNCTION_RETURN_CHAR_LIMIT = 3000 # ~300 words
+
+MAX_PAUSE_HEARTBEATS = 360 # in min
+
+MESSAGE_CHATGPT_FUNCTION_MODEL = "gpt-3.5-turbo"
+MESSAGE_CHATGPT_FUNCTION_SYSTEM_MESSAGE = "You are a helpful assistant. Keep your responses short and concise."
+
+#### Functions related
+
+# REQ_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}request_heartbeat == true"
+REQ_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}Function called using request_heartbeat=true, returning control"
+# FUNC_FAILED_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}Function call failed"
+FUNC_FAILED_HEARTBEAT_MESSAGE = f"{NON_USER_MSG_PREFIX}Function call failed, returning control"
+
+FUNCTION_PARAM_NAME_REQ_HEARTBEAT = "request_heartbeat"
+FUNCTION_PARAM_TYPE_REQ_HEARTBEAT = "boolean"
+FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT = "Request an immediate heartbeat after function execution. Set to 'true' if you want to send a follow-up message or run a follow-up function."
+
+RETRIEVAL_QUERY_DEFAULT_PAGE_SIZE = 5
+
+# GLOBAL SETTINGS FOR `json.dumps()`
+JSON_ENSURE_ASCII = False
+
+# GLOBAL SETTINGS FOR `json.loads()`
+JSON_LOADS_STRICT = False
diff --git a/memgpt/interface.py b/memgpt/interface.py
index aa1d2721..0970b784 100644
--- a/memgpt/interface.py
+++ b/memgpt/interface.py
@@ -1,315 +1,315 @@
-import json
-import re
-from abc import ABC, abstractmethod
-from typing import List, Optional
-
-from colorama import Fore, Style, init
-
-from memgpt.constants import CLI_WARNING_PREFIX, JSON_LOADS_STRICT
-from memgpt.data_types import Message
-from memgpt.utils import printd
-
-init(autoreset=True)
-
-# DEBUG = True # puts full message outputs in the terminal
-DEBUG = False # only dumps important messages in the terminal
-
-STRIP_UI = False
-
-
-class AgentInterface(ABC):
- """Interfaces handle MemGPT-related events (observer pattern)
-
- The 'msg' args provides the scoped message, and the optional Message arg can provide additional metadata.
- """
-
- @abstractmethod
- def user_message(self, msg: str, msg_obj: Optional[Message] = None):
- """MemGPT receives a user message"""
- raise NotImplementedError
-
- @abstractmethod
- def internal_monologue(self, msg: str, msg_obj: Optional[Message] = None):
- """MemGPT generates some internal monologue"""
- raise NotImplementedError
-
- @abstractmethod
- def assistant_message(self, msg: str, msg_obj: Optional[Message] = None):
- """MemGPT uses send_message"""
- raise NotImplementedError
-
- @abstractmethod
- def function_message(self, msg: str, msg_obj: Optional[Message] = None):
- """MemGPT calls a function"""
- raise NotImplementedError
-
- # @abstractmethod
- # @staticmethod
- # def print_messages():
- # raise NotImplementedError
-
- # @abstractmethod
- # @staticmethod
- # def print_messages_raw():
- # raise NotImplementedError
-
- # @abstractmethod
- # @staticmethod
- # def step_yield():
- # raise NotImplementedError
-
-
-class CLIInterface(AgentInterface):
- """Basic interface for dumping agent events to the command-line"""
-
- @staticmethod
- def important_message(msg: str):
- fstr = f"{Fore.MAGENTA}{Style.BRIGHT}{{msg}}{Style.RESET_ALL}"
- if STRIP_UI:
- fstr = "{msg}"
- print(fstr.format(msg=msg))
-
- @staticmethod
- def warning_message(msg: str):
- fstr = f"{Fore.RED}{Style.BRIGHT}{{msg}}{Style.RESET_ALL}"
- if STRIP_UI:
- fstr = "{msg}"
- else:
- print(fstr.format(msg=msg))
-
- @staticmethod
- def internal_monologue(msg: str, msg_obj: Optional[Message] = None):
- # ANSI escape code for italic is '\x1B[3m'
- fstr = f"\x1B[3m{Fore.LIGHTBLACK_EX}💭 {{msg}}{Style.RESET_ALL}"
- if STRIP_UI:
- fstr = "{msg}"
- print(fstr.format(msg=msg))
-
- @staticmethod
- def assistant_message(msg: str, msg_obj: Optional[Message] = None):
- fstr = f"{Fore.YELLOW}{Style.BRIGHT}🤖 {Fore.YELLOW}{{msg}}{Style.RESET_ALL}"
- if STRIP_UI:
- fstr = "{msg}"
- print(fstr.format(msg=msg))
-
- @staticmethod
- def memory_message(msg: str, msg_obj: Optional[Message] = None):
- fstr = f"{Fore.LIGHTMAGENTA_EX}{Style.BRIGHT}🧠 {Fore.LIGHTMAGENTA_EX}{{msg}}{Style.RESET_ALL}"
- if STRIP_UI:
- fstr = "{msg}"
- print(fstr.format(msg=msg))
-
- @staticmethod
- def system_message(msg: str, msg_obj: Optional[Message] = None):
- fstr = f"{Fore.MAGENTA}{Style.BRIGHT}🖥️ [system] {Fore.MAGENTA}{msg}{Style.RESET_ALL}"
- if STRIP_UI:
- fstr = "{msg}"
- print(fstr.format(msg=msg))
-
- @staticmethod
- def user_message(msg: str, msg_obj: Optional[Message] = None, raw: bool = False, dump: bool = False, debug: bool = DEBUG):
- def print_user_message(icon, msg, printf=print):
- if STRIP_UI:
- printf(f"{icon} {msg}")
- else:
- printf(f"{Fore.GREEN}{Style.BRIGHT}{icon} {Fore.GREEN}{msg}{Style.RESET_ALL}")
-
- def printd_user_message(icon, msg):
- return print_user_message(icon, msg)
-
- if not (raw or dump or debug):
- # we do not want to repeat the message in normal use
- return
-
- if isinstance(msg, str):
- if raw:
- printd_user_message("🧑", msg)
- return
- else:
- try:
- msg_json = json.loads(msg, strict=JSON_LOADS_STRICT)
- except:
- printd(f"{CLI_WARNING_PREFIX}failed to parse user message into json")
- printd_user_message("🧑", msg)
- return
- if msg_json["type"] == "user_message":
- if dump:
- print_user_message("🧑", msg_json["message"])
- return
- msg_json.pop("type")
- printd_user_message("🧑", msg_json)
- elif msg_json["type"] == "heartbeat":
- if debug:
- msg_json.pop("type")
- printd_user_message("💓", msg_json)
- elif dump:
- print_user_message("💓", msg_json)
- return
-
- elif msg_json["type"] == "system_message":
- msg_json.pop("type")
- printd_user_message("🖥️", msg_json)
- else:
- printd_user_message("🧑", msg_json)
-
- @staticmethod
- def function_message(msg: str, msg_obj: Optional[Message] = None, debug: bool = DEBUG):
- def print_function_message(icon, msg, color=Fore.RED, printf=print):
- if STRIP_UI:
- printf(f"⚡{icon} [function] {msg}")
- else:
- printf(f"{color}{Style.BRIGHT}⚡{icon} [function] {color}{msg}{Style.RESET_ALL}")
-
- def printd_function_message(icon, msg, color=Fore.RED):
- return print_function_message(icon, msg, color, printf=(print if debug else printd))
-
- if isinstance(msg, dict):
- printd_function_message("", msg)
- return
-
- if msg.startswith("Success"):
- printd_function_message("🟢", msg)
- elif msg.startswith("Error: "):
- printd_function_message("🔴", msg)
- elif msg.startswith("Ran "):
- # NOTE: ignore 'ran' messages that come post-execution
- return
- elif msg.startswith("Running "):
- if debug:
- printd_function_message("", msg)
- else:
- match = re.search(r"Running (\w+)\((.*)\)", msg)
- if match:
- function_name = match.group(1)
- function_args = match.group(2)
- if function_name in ["archival_memory_insert", "archival_memory_search", "core_memory_replace", "core_memory_append"]:
- if function_name in ["archival_memory_insert", "core_memory_append", "core_memory_replace"]:
- print_function_message("🧠", f"updating memory with {function_name}")
- elif function_name == "archival_memory_search":
- print_function_message("🧠", f"searching memory with {function_name}")
- try:
- msg_dict = eval(function_args)
- if function_name == "archival_memory_search":
- output = f'\tquery: {msg_dict["query"]}, page: {msg_dict["page"]}'
- if STRIP_UI:
- print(output)
- else:
- print(f"{Fore.RED}{output}{Style.RESET_ALL}")
- elif function_name == "archival_memory_insert":
- output = f'\t→ {msg_dict["content"]}'
- if STRIP_UI:
- print(output)
- else:
- print(f"{Style.BRIGHT}{Fore.RED}{output}{Style.RESET_ALL}")
- else:
- if STRIP_UI:
- print(f'\t {msg_dict["old_content"]}\n\t→ {msg_dict["new_content"]}')
- else:
- print(
- f'{Style.BRIGHT}\t{Fore.RED} {msg_dict["old_content"]}\n\t{Fore.GREEN}→ {msg_dict["new_content"]}{Style.RESET_ALL}'
- )
- except Exception as e:
- printd(str(e))
- printd(msg_dict)
- elif function_name in ["conversation_search", "conversation_search_date"]:
- print_function_message("🧠", f"searching memory with {function_name}")
- try:
- msg_dict = eval(function_args)
- output = f'\tquery: {msg_dict["query"]}, page: {msg_dict["page"]}'
- if STRIP_UI:
- print(output)
- else:
- print(f"{Fore.RED}{output}{Style.RESET_ALL}")
- except Exception as e:
- printd(str(e))
- printd(msg_dict)
- else:
- printd(f"{CLI_WARNING_PREFIX}did not recognize function message")
- printd_function_message("", msg)
- else:
- try:
- msg_dict = json.loads(msg, strict=JSON_LOADS_STRICT)
- if "status" in msg_dict and msg_dict["status"] == "OK":
- printd_function_message("", str(msg), color=Fore.GREEN)
- else:
- printd_function_message("", str(msg), color=Fore.RED)
- except Exception:
- print(f"{CLI_WARNING_PREFIX}did not recognize function message {type(msg)} {msg}")
- printd_function_message("", msg)
-
- @staticmethod
- def print_messages(message_sequence: List[Message], dump=False):
- # rewrite to dict format
- message_sequence = [msg.to_openai_dict() for msg in message_sequence]
-
- idx = len(message_sequence)
- for msg in message_sequence:
- if dump:
- print(f"[{idx}] ", end="")
- idx -= 1
- role = msg["role"]
- content = msg["content"]
-
- if role == "system":
- CLIInterface.system_message(content)
- elif role == "assistant":
- # Differentiate between internal monologue, function calls, and messages
- if msg.get("function_call"):
- if content is not None:
- CLIInterface.internal_monologue(content)
- # I think the next one is not up to date
- # function_message(msg["function_call"])
- args = json.loads(msg["function_call"].get("arguments"), strict=JSON_LOADS_STRICT)
- CLIInterface.assistant_message(args.get("message"))
- # assistant_message(content)
- elif msg.get("tool_calls"):
- if content is not None:
- CLIInterface.internal_monologue(content)
- function_obj = msg["tool_calls"][0].get("function")
- if function_obj:
- args = json.loads(function_obj.get("arguments"), strict=JSON_LOADS_STRICT)
- CLIInterface.assistant_message(args.get("message"))
- else:
- CLIInterface.internal_monologue(content)
- elif role == "user":
- CLIInterface.user_message(content, dump=dump)
- elif role == "function":
- CLIInterface.function_message(content, debug=dump)
- elif role == "tool":
- CLIInterface.function_message(content, debug=dump)
- else:
- print(f"Unknown role: {content}")
-
- @staticmethod
- def print_messages_simple(message_sequence: List[Message]):
- # rewrite to dict format
- message_sequence = [msg.to_openai_dict() for msg in message_sequence]
-
- for msg in message_sequence:
- role = msg["role"]
- content = msg["content"]
-
- if role == "system":
- CLIInterface.system_message(content)
- elif role == "assistant":
- CLIInterface.assistant_message(content)
- elif role == "user":
- CLIInterface.user_message(content, raw=True)
- else:
- print(f"Unknown role: {content}")
-
- @staticmethod
- def print_messages_raw(message_sequence: List[Message]):
- # rewrite to dict format
- message_sequence = [msg.to_openai_dict() for msg in message_sequence]
-
- for msg in message_sequence:
- print(msg)
-
- @staticmethod
- def step_yield():
- pass
-
- @staticmethod
- def step_complete():
- pass
+import json
+import re
+from abc import ABC, abstractmethod
+from typing import List, Optional
+
+from colorama import Fore, Style, init
+
+from memgpt.constants import CLI_WARNING_PREFIX, JSON_LOADS_STRICT
+from memgpt.data_types import Message
+from memgpt.utils import printd
+
+init(autoreset=True)
+
+# DEBUG = True # puts full message outputs in the terminal
+DEBUG = False # only dumps important messages in the terminal
+
+STRIP_UI = False
+
+
+class AgentInterface(ABC):
+ """Interfaces handle MemGPT-related events (observer pattern)
+
+ The 'msg' args provides the scoped message, and the optional Message arg can provide additional metadata.
+ """
+
+ @abstractmethod
+ def user_message(self, msg: str, msg_obj: Optional[Message] = None):
+ """MemGPT receives a user message"""
+ raise NotImplementedError
+
+ @abstractmethod
+ def internal_monologue(self, msg: str, msg_obj: Optional[Message] = None):
+ """MemGPT generates some internal monologue"""
+ raise NotImplementedError
+
+ @abstractmethod
+ def assistant_message(self, msg: str, msg_obj: Optional[Message] = None):
+ """MemGPT uses send_message"""
+ raise NotImplementedError
+
+ @abstractmethod
+ def function_message(self, msg: str, msg_obj: Optional[Message] = None):
+ """MemGPT calls a function"""
+ raise NotImplementedError
+
+ # @abstractmethod
+ # @staticmethod
+ # def print_messages():
+ # raise NotImplementedError
+
+ # @abstractmethod
+ # @staticmethod
+ # def print_messages_raw():
+ # raise NotImplementedError
+
+ # @abstractmethod
+ # @staticmethod
+ # def step_yield():
+ # raise NotImplementedError
+
+
+class CLIInterface(AgentInterface):
+ """Basic interface for dumping agent events to the command-line"""
+
+ @staticmethod
+ def important_message(msg: str):
+ fstr = f"{Fore.MAGENTA}{Style.BRIGHT}{{msg}}{Style.RESET_ALL}"
+ if STRIP_UI:
+ fstr = "{msg}"
+ print(fstr.format(msg=msg))
+
+ @staticmethod
+ def warning_message(msg: str):
+ fstr = f"{Fore.RED}{Style.BRIGHT}{{msg}}{Style.RESET_ALL}"
+ if STRIP_UI:
+ fstr = "{msg}"
+ else:
+ print(fstr.format(msg=msg))
+
+ @staticmethod
+ def internal_monologue(msg: str, msg_obj: Optional[Message] = None):
+ # ANSI escape code for italic is '\x1B[3m'
+ fstr = f"\x1B[3m{Fore.LIGHTBLACK_EX}💭 {{msg}}{Style.RESET_ALL}"
+ if STRIP_UI:
+ fstr = "{msg}"
+ print(fstr.format(msg=msg))
+
+ @staticmethod
+ def assistant_message(msg: str, msg_obj: Optional[Message] = None):
+ fstr = f"{Fore.YELLOW}{Style.BRIGHT}🤖 {Fore.YELLOW}{{msg}}{Style.RESET_ALL}"
+ if STRIP_UI:
+ fstr = "{msg}"
+ print(fstr.format(msg=msg))
+
+ @staticmethod
+ def memory_message(msg: str, msg_obj: Optional[Message] = None):
+ fstr = f"{Fore.LIGHTMAGENTA_EX}{Style.BRIGHT}🧠 {Fore.LIGHTMAGENTA_EX}{{msg}}{Style.RESET_ALL}"
+ if STRIP_UI:
+ fstr = "{msg}"
+ print(fstr.format(msg=msg))
+
+ @staticmethod
+ def system_message(msg: str, msg_obj: Optional[Message] = None):
+ fstr = f"{Fore.MAGENTA}{Style.BRIGHT}🖥️ [system] {Fore.MAGENTA}{msg}{Style.RESET_ALL}"
+ if STRIP_UI:
+ fstr = "{msg}"
+ print(fstr.format(msg=msg))
+
+ @staticmethod
+ def user_message(msg: str, msg_obj: Optional[Message] = None, raw: bool = False, dump: bool = False, debug: bool = DEBUG):
+ def print_user_message(icon, msg, printf=print):
+ if STRIP_UI:
+ printf(f"{icon} {msg}")
+ else:
+ printf(f"{Fore.GREEN}{Style.BRIGHT}{icon} {Fore.GREEN}{msg}{Style.RESET_ALL}")
+
+ def printd_user_message(icon, msg):
+ return print_user_message(icon, msg)
+
+ if not (raw or dump or debug):
+ # we do not want to repeat the message in normal use
+ return
+
+ if isinstance(msg, str):
+ if raw:
+ printd_user_message("🧑", msg)
+ return
+ else:
+ try:
+ msg_json = json.loads(msg, strict=JSON_LOADS_STRICT)
+ except:
+ printd(f"{CLI_WARNING_PREFIX}failed to parse user message into json")
+ printd_user_message("🧑", msg)
+ return
+ if msg_json["type"] == "user_message":
+ if dump:
+ print_user_message("🧑", msg_json["message"])
+ return
+ msg_json.pop("type")
+ printd_user_message("🧑", msg_json)
+ elif msg_json["type"] == "heartbeat":
+ if debug:
+ msg_json.pop("type")
+ printd_user_message("💓", msg_json)
+ elif dump:
+ print_user_message("💓", msg_json)
+ return
+
+ elif msg_json["type"] == "system_message":
+ msg_json.pop("type")
+ printd_user_message("🖥️", msg_json)
+ else:
+ printd_user_message("🧑", msg_json)
+
+ @staticmethod
+ def function_message(msg: str, msg_obj: Optional[Message] = None, debug: bool = DEBUG):
+ def print_function_message(icon, msg, color=Fore.RED, printf=print):
+ if STRIP_UI:
+ printf(f"⚡{icon} [function] {msg}")
+ else:
+ printf(f"{color}{Style.BRIGHT}⚡{icon} [function] {color}{msg}{Style.RESET_ALL}")
+
+ def printd_function_message(icon, msg, color=Fore.RED):
+ return print_function_message(icon, msg, color, printf=(print if debug else printd))
+
+ if isinstance(msg, dict):
+ printd_function_message("", msg)
+ return
+
+ if msg.startswith("Success"):
+ printd_function_message("🟢", msg)
+ elif msg.startswith("Error: "):
+ printd_function_message("🔴", msg)
+ elif msg.startswith("Ran "):
+ # NOTE: ignore 'ran' messages that come post-execution
+ return
+ elif msg.startswith("Running "):
+ if debug:
+ printd_function_message("", msg)
+ else:
+ match = re.search(r"Running (\w+)\((.*)\)", msg)
+ if match:
+ function_name = match.group(1)
+ function_args = match.group(2)
+ if function_name in ["archival_memory_insert", "archival_memory_search", "core_memory_replace", "core_memory_append"]:
+ if function_name in ["archival_memory_insert", "core_memory_append", "core_memory_replace"]:
+ print_function_message("🧠", f"updating memory with {function_name}")
+ elif function_name == "archival_memory_search":
+ print_function_message("🧠", f"searching memory with {function_name}")
+ try:
+ msg_dict = eval(function_args)
+ if function_name == "archival_memory_search":
+ output = f'\tquery: {msg_dict["query"]}, page: {msg_dict["page"]}'
+ if STRIP_UI:
+ print(output)
+ else:
+ print(f"{Fore.RED}{output}{Style.RESET_ALL}")
+ elif function_name == "archival_memory_insert":
+ output = f'\t→ {msg_dict["content"]}'
+ if STRIP_UI:
+ print(output)
+ else:
+ print(f"{Style.BRIGHT}{Fore.RED}{output}{Style.RESET_ALL}")
+ else:
+ if STRIP_UI:
+ print(f'\t {msg_dict["old_content"]}\n\t→ {msg_dict["new_content"]}')
+ else:
+ print(
+ f'{Style.BRIGHT}\t{Fore.RED} {msg_dict["old_content"]}\n\t{Fore.GREEN}→ {msg_dict["new_content"]}{Style.RESET_ALL}'
+ )
+ except Exception as e:
+ printd(str(e))
+ printd(msg_dict)
+ elif function_name in ["conversation_search", "conversation_search_date"]:
+ print_function_message("🧠", f"searching memory with {function_name}")
+ try:
+ msg_dict = eval(function_args)
+ output = f'\tquery: {msg_dict["query"]}, page: {msg_dict["page"]}'
+ if STRIP_UI:
+ print(output)
+ else:
+ print(f"{Fore.RED}{output}{Style.RESET_ALL}")
+ except Exception as e:
+ printd(str(e))
+ printd(msg_dict)
+ else:
+ printd(f"{CLI_WARNING_PREFIX}did not recognize function message")
+ printd_function_message("", msg)
+ else:
+ try:
+ msg_dict = json.loads(msg, strict=JSON_LOADS_STRICT)
+ if "status" in msg_dict and msg_dict["status"] == "OK":
+ printd_function_message("", str(msg), color=Fore.GREEN)
+ else:
+ printd_function_message("", str(msg), color=Fore.RED)
+ except Exception:
+ print(f"{CLI_WARNING_PREFIX}did not recognize function message {type(msg)} {msg}")
+ printd_function_message("", msg)
+
+ @staticmethod
+ def print_messages(message_sequence: List[Message], dump=False):
+ # rewrite to dict format
+ message_sequence = [msg.to_openai_dict() for msg in message_sequence]
+
+ idx = len(message_sequence)
+ for msg in message_sequence:
+ if dump:
+ print(f"[{idx}] ", end="")
+ idx -= 1
+ role = msg["role"]
+ content = msg["content"]
+
+ if role == "system":
+ CLIInterface.system_message(content)
+ elif role == "assistant":
+ # Differentiate between internal monologue, function calls, and messages
+ if msg.get("function_call"):
+ if content is not None:
+ CLIInterface.internal_monologue(content)
+ # I think the next one is not up to date
+ # function_message(msg["function_call"])
+ args = json.loads(msg["function_call"].get("arguments"), strict=JSON_LOADS_STRICT)
+ CLIInterface.assistant_message(args.get("message"))
+ # assistant_message(content)
+ elif msg.get("tool_calls"):
+ if content is not None:
+ CLIInterface.internal_monologue(content)
+ function_obj = msg["tool_calls"][0].get("function")
+ if function_obj:
+ args = json.loads(function_obj.get("arguments"), strict=JSON_LOADS_STRICT)
+ CLIInterface.assistant_message(args.get("message"))
+ else:
+ CLIInterface.internal_monologue(content)
+ elif role == "user":
+ CLIInterface.user_message(content, dump=dump)
+ elif role == "function":
+ CLIInterface.function_message(content, debug=dump)
+ elif role == "tool":
+ CLIInterface.function_message(content, debug=dump)
+ else:
+ print(f"Unknown role: {content}")
+
+ @staticmethod
+ def print_messages_simple(message_sequence: List[Message]):
+ # rewrite to dict format
+ message_sequence = [msg.to_openai_dict() for msg in message_sequence]
+
+ for msg in message_sequence:
+ role = msg["role"]
+ content = msg["content"]
+
+ if role == "system":
+ CLIInterface.system_message(content)
+ elif role == "assistant":
+ CLIInterface.assistant_message(content)
+ elif role == "user":
+ CLIInterface.user_message(content, raw=True)
+ else:
+ print(f"Unknown role: {content}")
+
+ @staticmethod
+ def print_messages_raw(message_sequence: List[Message]):
+ # rewrite to dict format
+ message_sequence = [msg.to_openai_dict() for msg in message_sequence]
+
+ for msg in message_sequence:
+ print(msg)
+
+ @staticmethod
+ def step_yield():
+ pass
+
+ @staticmethod
+ def step_complete():
+ pass
diff --git a/memgpt/llm_api/llm_api_tools.py b/memgpt/llm_api/llm_api_tools.py
index 053ff78a..a26721d4 100644
--- a/memgpt/llm_api/llm_api_tools.py
+++ b/memgpt/llm_api/llm_api_tools.py
@@ -1,358 +1,358 @@
-import os
-import random
-import time
-import uuid
-from typing import List, Optional, Union
-
-import requests
-
-from memgpt.constants import CLI_WARNING_PREFIX
-from memgpt.credentials import MemGPTCredentials
-from memgpt.data_types import Message
-from memgpt.llm_api.anthropic import anthropic_chat_completions_request
-from memgpt.llm_api.azure_openai import (
- MODEL_TO_AZURE_ENGINE,
- azure_openai_chat_completions_request,
-)
-from memgpt.llm_api.cohere import cohere_chat_completions_request
-from memgpt.llm_api.google_ai import (
- convert_tools_to_google_ai_format,
- google_ai_chat_completions_request,
-)
-from memgpt.llm_api.openai import (
- openai_chat_completions_process_stream,
- openai_chat_completions_request,
-)
-from memgpt.local_llm.chat_completion_proxy import get_chat_completion
-from memgpt.models.chat_completion_request import (
- ChatCompletionRequest,
- Tool,
- cast_message_to_subtype,
-)
-from memgpt.models.chat_completion_response import ChatCompletionResponse
-from memgpt.models.pydantic_models import LLMConfigModel
-from memgpt.streaming_interface import (
- AgentChunkStreamingInterface,
- AgentRefreshStreamingInterface,
-)
-
-LLM_API_PROVIDER_OPTIONS = ["openai", "azure", "anthropic", "google_ai", "cohere", "local"]
-
-
-def is_context_overflow_error(exception: requests.exceptions.RequestException) -> bool:
- """Checks if an exception is due to context overflow (based on common OpenAI response messages)"""
- from memgpt.utils import printd
-
- match_string = "maximum context length"
-
- # Backwards compatibility with openai python package/client v0.28 (pre-v1 client migration)
- if match_string in str(exception):
- printd(f"Found '{match_string}' in str(exception)={(str(exception))}")
- return True
-
- # Based on python requests + OpenAI REST API (/v1)
- elif isinstance(exception, requests.exceptions.HTTPError):
- if exception.response is not None and "application/json" in exception.response.headers.get("Content-Type", ""):
- try:
- error_details = exception.response.json()
- if "error" not in error_details:
- printd(f"HTTPError occurred, but couldn't find error field: {error_details}")
- return False
- else:
- error_details = error_details["error"]
-
- # Check for the specific error code
- if error_details.get("code") == "context_length_exceeded":
- printd(f"HTTPError occurred, caught error code {error_details.get('code')}")
- return True
- # Soft-check for "maximum context length" inside of the message
- elif error_details.get("message") and "maximum context length" in error_details.get("message"):
- printd(f"HTTPError occurred, found '{match_string}' in error message contents ({error_details})")
- return True
- else:
- printd(f"HTTPError occurred, but unknown error message: {error_details}")
- return False
- except ValueError:
- # JSON decoding failed
- printd(f"HTTPError occurred ({exception}), but no JSON error message.")
-
- # Generic fail
- else:
- return False
-
-
-def retry_with_exponential_backoff(
- func,
- initial_delay: float = 1,
- exponential_base: float = 2,
- jitter: bool = True,
- max_retries: int = 20,
- # List of OpenAI error codes: https://github.com/openai/openai-python/blob/17ac6779958b2b74999c634c4ea4c7b74906027a/src/openai/_client.py#L227-L250
- # 429 = rate limit
- error_codes: tuple = (429,),
-):
- """Retry a function with exponential backoff."""
-
- def wrapper(*args, **kwargs):
- pass
-
- # Initialize variables
- num_retries = 0
- delay = initial_delay
-
- # Loop until a successful response or max_retries is hit or an exception is raised
- while True:
- try:
- return func(*args, **kwargs)
-
- except requests.exceptions.HTTPError as http_err:
- # Retry on specified errors
- if http_err.response.status_code in error_codes:
- # Increment retries
- num_retries += 1
-
- # Check if max retries has been reached
- if num_retries > max_retries:
- raise Exception(f"Maximum number of retries ({max_retries}) exceeded.")
-
- # Increment the delay
- delay *= exponential_base * (1 + jitter * random.random())
-
- # Sleep for the delay
- # printd(f"Got a rate limit error ('{http_err}') on LLM backend request, waiting {int(delay)}s then retrying...")
- print(
- f"{CLI_WARNING_PREFIX}Got a rate limit error ('{http_err}') on LLM backend request, waiting {int(delay)}s then retrying..."
- )
- time.sleep(delay)
- else:
- # For other HTTP errors, re-raise the exception
- raise
-
- # Raise exceptions for any errors not specified
- except Exception as e:
- raise e
-
- return wrapper
-
-
-@retry_with_exponential_backoff
-def create(
- # agent_state: AgentState,
- llm_config: LLMConfigModel,
- messages: List[Message],
- user_id: uuid.UUID = None, # option UUID to associate request with
- functions: list = None,
- functions_python: list = None,
- function_call: str = "auto",
- # hint
- first_message: bool = False,
- # use tool naming?
- # if false, will use deprecated 'functions' style
- use_tool_naming: bool = True,
- # streaming?
- stream: bool = False,
- stream_inferface: Optional[Union[AgentRefreshStreamingInterface, AgentChunkStreamingInterface]] = None,
-) -> ChatCompletionResponse:
- """Return response to chat completion with backoff"""
- from memgpt.utils import printd
-
- printd(f"Using model {llm_config.model_endpoint_type}, endpoint: {llm_config.model_endpoint}")
-
- # TODO eventually refactor so that credentials are passed through
-
- credentials = MemGPTCredentials.load()
-
- if function_call and not functions:
- printd("unsetting function_call because functions is None")
- function_call = None
-
- # openai
- if llm_config.model_endpoint_type == "openai":
- # TODO do the same for Azure?
- if credentials.openai_key is None and llm_config.model_endpoint == "https://api.openai.com/v1":
- # only is a problem if we are *not* using an openai proxy
- raise ValueError(f"OpenAI key is missing from MemGPT config file")
- if use_tool_naming:
- data = ChatCompletionRequest(
- model=llm_config.model,
- messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
- tools=[{"type": "function", "function": f} for f in functions] if functions else None,
- tool_choice=function_call,
- user=str(user_id),
- )
- else:
- data = ChatCompletionRequest(
- model=llm_config.model,
- messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
- functions=functions,
- function_call=function_call,
- user=str(user_id),
- )
- # https://platform.openai.com/docs/guides/text-generation/json-mode
- # only supported by gpt-4o, gpt-4-turbo, or gpt-3.5-turbo
- if "gpt-4o" in llm_config.model or "gpt-4-turbo" in llm_config.model or "gpt-3.5-turbo" in llm_config.model:
- data.response_format = {"type": "json_object"}
-
- if stream: # Client requested token streaming
- data.stream = True
- assert isinstance(stream_inferface, AgentChunkStreamingInterface) or isinstance(
- stream_inferface, AgentRefreshStreamingInterface
- ), type(stream_inferface)
- return openai_chat_completions_process_stream(
- url=llm_config.model_endpoint, # https://api.openai.com/v1 -> https://api.openai.com/v1/chat/completions
- api_key=credentials.openai_key,
- chat_completion_request=data,
- stream_inferface=stream_inferface,
- )
- else: # Client did not request token streaming (expect a blocking backend response)
- data.stream = False
- if isinstance(stream_inferface, AgentChunkStreamingInterface):
- stream_inferface.stream_start()
- try:
- response = openai_chat_completions_request(
- url=llm_config.model_endpoint, # https://api.openai.com/v1 -> https://api.openai.com/v1/chat/completions
- api_key=credentials.openai_key,
- chat_completion_request=data,
- )
- finally:
- if isinstance(stream_inferface, AgentChunkStreamingInterface):
- stream_inferface.stream_end()
- return response
-
- # azure
- elif llm_config.model_endpoint_type == "azure":
- if stream:
- raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
-
- azure_deployment = (
- credentials.azure_deployment if credentials.azure_deployment is not None else MODEL_TO_AZURE_ENGINE[llm_config.model]
- )
- if use_tool_naming:
- data = dict(
- # NOTE: don't pass model to Azure calls, that is the deployment_id
- # model=agent_config.model,
- messages=messages,
- tools=[{"type": "function", "function": f} for f in functions] if functions else None,
- tool_choice=function_call,
- user=str(user_id),
- )
- else:
- data = dict(
- # NOTE: don't pass model to Azure calls, that is the deployment_id
- # model=agent_config.model,
- messages=messages,
- functions=functions,
- function_call=function_call,
- user=str(user_id),
- )
- return azure_openai_chat_completions_request(
- resource_name=credentials.azure_endpoint,
- deployment_id=azure_deployment,
- api_version=credentials.azure_version,
- api_key=credentials.azure_key,
- data=data,
- )
-
- elif llm_config.model_endpoint_type == "google_ai":
- if stream:
- raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
- if not use_tool_naming:
- raise NotImplementedError("Only tool calling supported on Google AI API requests")
-
- # NOTE: until Google AI supports CoT / text alongside function calls,
- # we need to put it in a kwarg (unless we want to split the message into two)
- google_ai_inner_thoughts_in_kwarg = True
-
- if functions is not None:
- tools = [{"type": "function", "function": f} for f in functions]
- tools = [Tool(**t) for t in tools]
- tools = convert_tools_to_google_ai_format(tools, inner_thoughts_in_kwargs=google_ai_inner_thoughts_in_kwarg)
- else:
- tools = None
-
- return google_ai_chat_completions_request(
- inner_thoughts_in_kwargs=google_ai_inner_thoughts_in_kwarg,
- service_endpoint=credentials.google_ai_service_endpoint,
- model=llm_config.model,
- api_key=credentials.google_ai_key,
- # see structure of payload here: https://ai.google.dev/docs/function_calling
- data=dict(
- contents=[m.to_google_ai_dict() for m in messages],
- tools=tools,
- ),
- )
-
- elif llm_config.model_endpoint_type == "anthropic":
- if stream:
- raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
- if not use_tool_naming:
- raise NotImplementedError("Only tool calling supported on Anthropic API requests")
-
- if functions is not None:
- tools = [{"type": "function", "function": f} for f in functions]
- tools = [Tool(**t) for t in tools]
- else:
- tools = None
-
- return anthropic_chat_completions_request(
- url=llm_config.model_endpoint,
- api_key=credentials.anthropic_key,
- data=ChatCompletionRequest(
- model=llm_config.model,
- messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
- tools=[{"type": "function", "function": f} for f in functions] if functions else None,
- # tool_choice=function_call,
- # user=str(user_id),
- # NOTE: max_tokens is required for Anthropic API
- max_tokens=1024, # TODO make dynamic
- ),
- )
-
- elif llm_config.model_endpoint_type == "cohere":
- if stream:
- raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
- if not use_tool_naming:
- raise NotImplementedError("Only tool calling supported on Cohere API requests")
-
- if functions is not None:
- tools = [{"type": "function", "function": f} for f in functions]
- tools = [Tool(**t) for t in tools]
- else:
- tools = None
-
- return cohere_chat_completions_request(
- # url=llm_config.model_endpoint,
- url="https://api.cohere.ai/v1", # TODO
- api_key=os.getenv("COHERE_API_KEY"), # TODO remove
- chat_completion_request=ChatCompletionRequest(
- model="command-r-plus", # TODO
- messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
- tools=[{"type": "function", "function": f} for f in functions] if functions else None,
- tool_choice=function_call,
- # user=str(user_id),
- # NOTE: max_tokens is required for Anthropic API
- # max_tokens=1024, # TODO make dynamic
- ),
- )
-
- # local model
- else:
- if stream:
- raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
- return get_chat_completion(
- model=llm_config.model,
- messages=messages,
- functions=functions,
- functions_python=functions_python,
- function_call=function_call,
- context_window=llm_config.context_window,
- endpoint=llm_config.model_endpoint,
- endpoint_type=llm_config.model_endpoint_type,
- wrapper=llm_config.model_wrapper,
- user=str(user_id),
- # hint
- first_message=first_message,
- # auth-related
- auth_type=credentials.openllm_auth_type,
- auth_key=credentials.openllm_key,
- )
+import os
+import random
+import time
+import uuid
+from typing import List, Optional, Union
+
+import requests
+
+from memgpt.constants import CLI_WARNING_PREFIX
+from memgpt.credentials import MemGPTCredentials
+from memgpt.data_types import Message
+from memgpt.llm_api.anthropic import anthropic_chat_completions_request
+from memgpt.llm_api.azure_openai import (
+ MODEL_TO_AZURE_ENGINE,
+ azure_openai_chat_completions_request,
+)
+from memgpt.llm_api.cohere import cohere_chat_completions_request
+from memgpt.llm_api.google_ai import (
+ convert_tools_to_google_ai_format,
+ google_ai_chat_completions_request,
+)
+from memgpt.llm_api.openai import (
+ openai_chat_completions_process_stream,
+ openai_chat_completions_request,
+)
+from memgpt.local_llm.chat_completion_proxy import get_chat_completion
+from memgpt.models.chat_completion_request import (
+ ChatCompletionRequest,
+ Tool,
+ cast_message_to_subtype,
+)
+from memgpt.models.chat_completion_response import ChatCompletionResponse
+from memgpt.models.pydantic_models import LLMConfigModel
+from memgpt.streaming_interface import (
+ AgentChunkStreamingInterface,
+ AgentRefreshStreamingInterface,
+)
+
+LLM_API_PROVIDER_OPTIONS = ["openai", "azure", "anthropic", "google_ai", "cohere", "local"]
+
+
+def is_context_overflow_error(exception: requests.exceptions.RequestException) -> bool:
+ """Checks if an exception is due to context overflow (based on common OpenAI response messages)"""
+ from memgpt.utils import printd
+
+ match_string = "maximum context length"
+
+ # Backwards compatibility with openai python package/client v0.28 (pre-v1 client migration)
+ if match_string in str(exception):
+ printd(f"Found '{match_string}' in str(exception)={(str(exception))}")
+ return True
+
+ # Based on python requests + OpenAI REST API (/v1)
+ elif isinstance(exception, requests.exceptions.HTTPError):
+ if exception.response is not None and "application/json" in exception.response.headers.get("Content-Type", ""):
+ try:
+ error_details = exception.response.json()
+ if "error" not in error_details:
+ printd(f"HTTPError occurred, but couldn't find error field: {error_details}")
+ return False
+ else:
+ error_details = error_details["error"]
+
+ # Check for the specific error code
+ if error_details.get("code") == "context_length_exceeded":
+ printd(f"HTTPError occurred, caught error code {error_details.get('code')}")
+ return True
+ # Soft-check for "maximum context length" inside of the message
+ elif error_details.get("message") and "maximum context length" in error_details.get("message"):
+ printd(f"HTTPError occurred, found '{match_string}' in error message contents ({error_details})")
+ return True
+ else:
+ printd(f"HTTPError occurred, but unknown error message: {error_details}")
+ return False
+ except ValueError:
+ # JSON decoding failed
+ printd(f"HTTPError occurred ({exception}), but no JSON error message.")
+
+ # Generic fail
+ else:
+ return False
+
+
+def retry_with_exponential_backoff(
+ func,
+ initial_delay: float = 1,
+ exponential_base: float = 2,
+ jitter: bool = True,
+ max_retries: int = 20,
+ # List of OpenAI error codes: https://github.com/openai/openai-python/blob/17ac6779958b2b74999c634c4ea4c7b74906027a/src/openai/_client.py#L227-L250
+ # 429 = rate limit
+ error_codes: tuple = (429,),
+):
+ """Retry a function with exponential backoff."""
+
+ def wrapper(*args, **kwargs):
+ pass
+
+ # Initialize variables
+ num_retries = 0
+ delay = initial_delay
+
+ # Loop until a successful response or max_retries is hit or an exception is raised
+ while True:
+ try:
+ return func(*args, **kwargs)
+
+ except requests.exceptions.HTTPError as http_err:
+ # Retry on specified errors
+ if http_err.response.status_code in error_codes:
+ # Increment retries
+ num_retries += 1
+
+ # Check if max retries has been reached
+ if num_retries > max_retries:
+ raise Exception(f"Maximum number of retries ({max_retries}) exceeded.")
+
+ # Increment the delay
+ delay *= exponential_base * (1 + jitter * random.random())
+
+ # Sleep for the delay
+ # printd(f"Got a rate limit error ('{http_err}') on LLM backend request, waiting {int(delay)}s then retrying...")
+ print(
+ f"{CLI_WARNING_PREFIX}Got a rate limit error ('{http_err}') on LLM backend request, waiting {int(delay)}s then retrying..."
+ )
+ time.sleep(delay)
+ else:
+ # For other HTTP errors, re-raise the exception
+ raise
+
+ # Raise exceptions for any errors not specified
+ except Exception as e:
+ raise e
+
+ return wrapper
+
+
+@retry_with_exponential_backoff
+def create(
+ # agent_state: AgentState,
+ llm_config: LLMConfigModel,
+ messages: List[Message],
+ user_id: uuid.UUID = None, # option UUID to associate request with
+ functions: list = None,
+ functions_python: list = None,
+ function_call: str = "auto",
+ # hint
+ first_message: bool = False,
+ # use tool naming?
+ # if false, will use deprecated 'functions' style
+ use_tool_naming: bool = True,
+ # streaming?
+ stream: bool = False,
+ stream_inferface: Optional[Union[AgentRefreshStreamingInterface, AgentChunkStreamingInterface]] = None,
+) -> ChatCompletionResponse:
+ """Return response to chat completion with backoff"""
+ from memgpt.utils import printd
+
+ printd(f"Using model {llm_config.model_endpoint_type}, endpoint: {llm_config.model_endpoint}")
+
+ # TODO eventually refactor so that credentials are passed through
+
+ credentials = MemGPTCredentials.load()
+
+ if function_call and not functions:
+ printd("unsetting function_call because functions is None")
+ function_call = None
+
+ # openai
+ if llm_config.model_endpoint_type == "openai":
+ # TODO do the same for Azure?
+ if credentials.openai_key is None and llm_config.model_endpoint == "https://api.openai.com/v1":
+ # only is a problem if we are *not* using an openai proxy
+ raise ValueError(f"OpenAI key is missing from MemGPT config file")
+ if use_tool_naming:
+ data = ChatCompletionRequest(
+ model=llm_config.model,
+ messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
+ tools=[{"type": "function", "function": f} for f in functions] if functions else None,
+ tool_choice=function_call,
+ user=str(user_id),
+ )
+ else:
+ data = ChatCompletionRequest(
+ model=llm_config.model,
+ messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
+ functions=functions,
+ function_call=function_call,
+ user=str(user_id),
+ )
+ # https://platform.openai.com/docs/guides/text-generation/json-mode
+ # only supported by gpt-4o, gpt-4-turbo, or gpt-3.5-turbo
+ if "gpt-4o" in llm_config.model or "gpt-4-turbo" in llm_config.model or "gpt-3.5-turbo" in llm_config.model:
+ data.response_format = {"type": "json_object"}
+
+ if stream: # Client requested token streaming
+ data.stream = True
+ assert isinstance(stream_inferface, AgentChunkStreamingInterface) or isinstance(
+ stream_inferface, AgentRefreshStreamingInterface
+ ), type(stream_inferface)
+ return openai_chat_completions_process_stream(
+ url=llm_config.model_endpoint, # https://api.openai.com/v1 -> https://api.openai.com/v1/chat/completions
+ api_key=credentials.openai_key,
+ chat_completion_request=data,
+ stream_inferface=stream_inferface,
+ )
+ else: # Client did not request token streaming (expect a blocking backend response)
+ data.stream = False
+ if isinstance(stream_inferface, AgentChunkStreamingInterface):
+ stream_inferface.stream_start()
+ try:
+ response = openai_chat_completions_request(
+ url=llm_config.model_endpoint, # https://api.openai.com/v1 -> https://api.openai.com/v1/chat/completions
+ api_key=credentials.openai_key,
+ chat_completion_request=data,
+ )
+ finally:
+ if isinstance(stream_inferface, AgentChunkStreamingInterface):
+ stream_inferface.stream_end()
+ return response
+
+ # azure
+ elif llm_config.model_endpoint_type == "azure":
+ if stream:
+ raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
+
+ azure_deployment = (
+ credentials.azure_deployment if credentials.azure_deployment is not None else MODEL_TO_AZURE_ENGINE[llm_config.model]
+ )
+ if use_tool_naming:
+ data = dict(
+ # NOTE: don't pass model to Azure calls, that is the deployment_id
+ # model=agent_config.model,
+ messages=messages,
+ tools=[{"type": "function", "function": f} for f in functions] if functions else None,
+ tool_choice=function_call,
+ user=str(user_id),
+ )
+ else:
+ data = dict(
+ # NOTE: don't pass model to Azure calls, that is the deployment_id
+ # model=agent_config.model,
+ messages=messages,
+ functions=functions,
+ function_call=function_call,
+ user=str(user_id),
+ )
+ return azure_openai_chat_completions_request(
+ resource_name=credentials.azure_endpoint,
+ deployment_id=azure_deployment,
+ api_version=credentials.azure_version,
+ api_key=credentials.azure_key,
+ data=data,
+ )
+
+ elif llm_config.model_endpoint_type == "google_ai":
+ if stream:
+ raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
+ if not use_tool_naming:
+ raise NotImplementedError("Only tool calling supported on Google AI API requests")
+
+ # NOTE: until Google AI supports CoT / text alongside function calls,
+ # we need to put it in a kwarg (unless we want to split the message into two)
+ google_ai_inner_thoughts_in_kwarg = True
+
+ if functions is not None:
+ tools = [{"type": "function", "function": f} for f in functions]
+ tools = [Tool(**t) for t in tools]
+ tools = convert_tools_to_google_ai_format(tools, inner_thoughts_in_kwargs=google_ai_inner_thoughts_in_kwarg)
+ else:
+ tools = None
+
+ return google_ai_chat_completions_request(
+ inner_thoughts_in_kwargs=google_ai_inner_thoughts_in_kwarg,
+ service_endpoint=credentials.google_ai_service_endpoint,
+ model=llm_config.model,
+ api_key=credentials.google_ai_key,
+ # see structure of payload here: https://ai.google.dev/docs/function_calling
+ data=dict(
+ contents=[m.to_google_ai_dict() for m in messages],
+ tools=tools,
+ ),
+ )
+
+ elif llm_config.model_endpoint_type == "anthropic":
+ if stream:
+ raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
+ if not use_tool_naming:
+ raise NotImplementedError("Only tool calling supported on Anthropic API requests")
+
+ if functions is not None:
+ tools = [{"type": "function", "function": f} for f in functions]
+ tools = [Tool(**t) for t in tools]
+ else:
+ tools = None
+
+ return anthropic_chat_completions_request(
+ url=llm_config.model_endpoint,
+ api_key=credentials.anthropic_key,
+ data=ChatCompletionRequest(
+ model=llm_config.model,
+ messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
+ tools=[{"type": "function", "function": f} for f in functions] if functions else None,
+ # tool_choice=function_call,
+ # user=str(user_id),
+ # NOTE: max_tokens is required for Anthropic API
+ max_tokens=1024, # TODO make dynamic
+ ),
+ )
+
+ elif llm_config.model_endpoint_type == "cohere":
+ if stream:
+ raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
+ if not use_tool_naming:
+ raise NotImplementedError("Only tool calling supported on Cohere API requests")
+
+ if functions is not None:
+ tools = [{"type": "function", "function": f} for f in functions]
+ tools = [Tool(**t) for t in tools]
+ else:
+ tools = None
+
+ return cohere_chat_completions_request(
+ # url=llm_config.model_endpoint,
+ url="https://api.cohere.ai/v1", # TODO
+ api_key=os.getenv("COHERE_API_KEY"), # TODO remove
+ chat_completion_request=ChatCompletionRequest(
+ model="command-r-plus", # TODO
+ messages=[cast_message_to_subtype(m.to_openai_dict()) for m in messages],
+ tools=[{"type": "function", "function": f} for f in functions] if functions else None,
+ tool_choice=function_call,
+ # user=str(user_id),
+ # NOTE: max_tokens is required for Anthropic API
+ # max_tokens=1024, # TODO make dynamic
+ ),
+ )
+
+ # local model
+ else:
+ if stream:
+ raise NotImplementedError(f"Streaming not yet implemented for {llm_config.model_endpoint_type}")
+ return get_chat_completion(
+ model=llm_config.model,
+ messages=messages,
+ functions=functions,
+ functions_python=functions_python,
+ function_call=function_call,
+ context_window=llm_config.context_window,
+ endpoint=llm_config.model_endpoint,
+ endpoint_type=llm_config.model_endpoint_type,
+ wrapper=llm_config.model_wrapper,
+ user=str(user_id),
+ # hint
+ first_message=first_message,
+ # auth-related
+ auth_type=credentials.openllm_auth_type,
+ auth_key=credentials.openllm_key,
+ )
diff --git a/memgpt/local_llm/README.md b/memgpt/local_llm/README.md
index e9dd603b..1eaede1b 100644
--- a/memgpt/local_llm/README.md
+++ b/memgpt/local_llm/README.md
@@ -1,3 +1,3 @@
-# MemGPT + local LLMs
-
-See [https://memgpt.readme.io/docs/local_llm](https://memgpt.readme.io/docs/local_llm) for documentation on running MemGPT with custom LLM backends.
+# MemGPT + local LLMs
+
+See [https://memgpt.readme.io/docs/local_llm](https://memgpt.readme.io/docs/local_llm) for documentation on running MemGPT with custom LLM backends.
diff --git a/memgpt/local_llm/chat_completion_proxy.py b/memgpt/local_llm/chat_completion_proxy.py
index 11c12430..a4599947 100644
--- a/memgpt/local_llm/chat_completion_proxy.py
+++ b/memgpt/local_llm/chat_completion_proxy.py
@@ -1,280 +1,280 @@
-"""Key idea: create drop-in replacement for agent's ChatCompletion call that runs on an OpenLLM backend"""
-
-import json
-import uuid
-
-import requests
-
-from memgpt.constants import CLI_WARNING_PREFIX, JSON_ENSURE_ASCII
-from memgpt.errors import LocalLLMConnectionError, LocalLLMError
-from memgpt.local_llm.constants import DEFAULT_WRAPPER
-from memgpt.local_llm.function_parser import patch_function
-from memgpt.local_llm.grammars.gbnf_grammar_generator import (
- create_dynamic_model_from_function,
- generate_gbnf_grammar_and_documentation,
-)
-from memgpt.local_llm.groq.api import get_groq_completion
-from memgpt.local_llm.koboldcpp.api import get_koboldcpp_completion
-from memgpt.local_llm.llamacpp.api import get_llamacpp_completion
-from memgpt.local_llm.llm_chat_completion_wrappers import simple_summary_wrapper
-from memgpt.local_llm.lmstudio.api import get_lmstudio_completion
-from memgpt.local_llm.ollama.api import get_ollama_completion
-from memgpt.local_llm.utils import count_tokens, get_available_wrappers
-from memgpt.local_llm.vllm.api import get_vllm_completion
-from memgpt.local_llm.webui.api import get_webui_completion
-from memgpt.local_llm.webui.legacy_api import (
- get_webui_completion as get_webui_completion_legacy,
-)
-from memgpt.models.chat_completion_response import (
- ChatCompletionResponse,
- Choice,
- Message,
- ToolCall,
- UsageStatistics,
-)
-from memgpt.prompts.gpt_summarize import SYSTEM as SUMMARIZE_SYSTEM_MESSAGE
-from memgpt.utils import get_tool_call_id, get_utc_time
-
-has_shown_warning = False
-grammar_supported_backends = ["koboldcpp", "llamacpp", "webui", "webui-legacy"]
-
-
-def get_chat_completion(
- model,
- # no model required (except for Ollama), since the model is fixed to whatever you set in your own backend
- messages,
- functions=None,
- functions_python=None,
- function_call="auto",
- context_window=None,
- user=None,
- # required
- wrapper=None,
- endpoint=None,
- endpoint_type=None,
- # optional cleanup
- function_correction=True,
- # extra hints to allow for additional prompt formatting hacks
- # TODO this could alternatively be supported via passing function_call="send_message" into the wrapper
- first_message=False,
- # optional auth headers
- auth_type=None,
- auth_key=None,
-) -> ChatCompletionResponse:
- from memgpt.utils import printd
-
- assert context_window is not None, "Local LLM calls need the context length to be explicitly set"
- assert endpoint is not None, "Local LLM calls need the endpoint (eg http://localendpoint:1234) to be explicitly set"
- assert endpoint_type is not None, "Local LLM calls need the endpoint type (eg webui) to be explicitly set"
- global has_shown_warning
- grammar = None
-
- # TODO: eventually just process Message object
- if not isinstance(messages[0], dict):
- messages = [m.to_openai_dict() for m in messages]
-
- if function_call is not None and function_call != "auto":
- raise ValueError(f"function_call == {function_call} not supported (auto or None only)")
-
- available_wrappers = get_available_wrappers()
- documentation = None
-
- # Special case for if the call we're making is coming from the summarizer
- if messages[0]["role"] == "system" and messages[0]["content"].strip() == SUMMARIZE_SYSTEM_MESSAGE.strip():
- llm_wrapper = simple_summary_wrapper.SimpleSummaryWrapper()
-
- # Select a default prompt formatter
- elif wrapper is None:
- # Warn the user that we're using the fallback
- if not has_shown_warning:
- print(
- f"{CLI_WARNING_PREFIX}no wrapper specified for local LLM, using the default wrapper (you can remove this warning by specifying the wrapper with --model-wrapper)"
- )
- has_shown_warning = True
-
- llm_wrapper = DEFAULT_WRAPPER()
-
- # User provided an incorrect prompt formatter
- elif wrapper not in available_wrappers:
- raise ValueError(f"Could not find requested wrapper '{wrapper} in available wrappers list:\n{', '.join(available_wrappers)}")
-
- # User provided a correct prompt formatter
- else:
- llm_wrapper = available_wrappers[wrapper]
-
- # If the wrapper uses grammar, generate the grammar using the grammar generating function
- # TODO move this to a flag
- if wrapper is not None and "grammar" in wrapper:
- # When using grammars, we don't want to do any extras output tricks like appending a response prefix
- setattr(llm_wrapper, "assistant_prefix_extra_first_message", "")
- setattr(llm_wrapper, "assistant_prefix_extra", "")
-
- # TODO find a better way to do this than string matching (eg an attribute)
- if "noforce" in wrapper:
- # "noforce" means that the prompt formatter expects inner thoughts as a top-level parameter
- # this is closer to the OpenAI style since it allows for messages w/o any function calls
- # however, with bad LLMs it makes it easier for the LLM to "forget" to call any of the functions
- grammar, documentation = generate_grammar_and_documentation(
- functions_python=functions_python,
- add_inner_thoughts_top_level=True,
- add_inner_thoughts_param_level=False,
- allow_only_inner_thoughts=True,
- )
- else:
- # otherwise, the other prompt formatters will insert inner thoughts as a function call parameter (by default)
- # this means that every response from the LLM will be required to call a function
- grammar, documentation = generate_grammar_and_documentation(
- functions_python=functions_python,
- add_inner_thoughts_top_level=False,
- add_inner_thoughts_param_level=True,
- allow_only_inner_thoughts=False,
- )
- printd(grammar)
-
- if grammar is not None and endpoint_type not in grammar_supported_backends:
- print(
- f"{CLI_WARNING_PREFIX}grammars are currently not supported when using {endpoint_type} as the MemGPT local LLM backend (supported: {', '.join(grammar_supported_backends)})"
- )
- grammar = None
-
- # First step: turn the message sequence into a prompt that the model expects
- try:
- # if hasattr(llm_wrapper, "supports_first_message"):
- if hasattr(llm_wrapper, "supports_first_message") and llm_wrapper.supports_first_message:
- prompt = llm_wrapper.chat_completion_to_prompt(
- messages=messages, functions=functions, first_message=first_message, function_documentation=documentation
- )
- else:
- prompt = llm_wrapper.chat_completion_to_prompt(messages=messages, functions=functions, function_documentation=documentation)
-
- printd(prompt)
- except Exception as e:
- print(e)
- raise LocalLLMError(
- f"Failed to convert ChatCompletion messages into prompt string with wrapper {str(llm_wrapper)} - error: {str(e)}"
- )
-
- try:
- if endpoint_type == "webui":
- result, usage = get_webui_completion(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
- elif endpoint_type == "webui-legacy":
- result, usage = get_webui_completion_legacy(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
- elif endpoint_type == "lmstudio":
- result, usage = get_lmstudio_completion(endpoint, auth_type, auth_key, prompt, context_window, api="completions")
- elif endpoint_type == "lmstudio-legacy":
- result, usage = get_lmstudio_completion(endpoint, auth_type, auth_key, prompt, context_window, api="chat")
- elif endpoint_type == "llamacpp":
- result, usage = get_llamacpp_completion(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
- elif endpoint_type == "koboldcpp":
- result, usage = get_koboldcpp_completion(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
- elif endpoint_type == "ollama":
- result, usage = get_ollama_completion(endpoint, auth_type, auth_key, model, prompt, context_window)
- elif endpoint_type == "vllm":
- result, usage = get_vllm_completion(endpoint, auth_type, auth_key, model, prompt, context_window, user)
- elif endpoint_type == "groq":
- result, usage = get_groq_completion(endpoint, auth_type, auth_key, model, prompt, context_window)
- else:
- raise LocalLLMError(
- f"Invalid endpoint type {endpoint_type}, please set variable depending on your backend (webui, lmstudio, llamacpp, koboldcpp)"
- )
- except requests.exceptions.ConnectionError as e:
- raise LocalLLMConnectionError(f"Unable to connect to endpoint {endpoint}")
-
- if result is None or result == "":
- raise LocalLLMError(f"Got back an empty response string from {endpoint}")
- printd(f"Raw LLM output:\n====\n{result}\n====")
-
- try:
- if hasattr(llm_wrapper, "supports_first_message") and llm_wrapper.supports_first_message:
- chat_completion_result = llm_wrapper.output_to_chat_completion_response(result, first_message=first_message)
- else:
- chat_completion_result = llm_wrapper.output_to_chat_completion_response(result)
- printd(json.dumps(chat_completion_result, indent=2, ensure_ascii=JSON_ENSURE_ASCII))
- except Exception as e:
- raise LocalLLMError(f"Failed to parse JSON from local LLM response - error: {str(e)}")
-
- # Run through some manual function correction (optional)
- if function_correction:
- chat_completion_result = patch_function(message_history=messages, new_message=chat_completion_result)
-
- # Fill in potential missing usage information (used for tracking token use)
- if not ("prompt_tokens" in usage and "completion_tokens" in usage and "total_tokens" in usage):
- raise LocalLLMError(f"usage dict in response was missing fields ({usage})")
-
- if usage["prompt_tokens"] is None:
- printd(f"usage dict was missing prompt_tokens, computing on-the-fly...")
- usage["prompt_tokens"] = count_tokens(prompt)
-
- # NOTE: we should compute on-the-fly anyways since we might have to correct for errors during JSON parsing
- usage["completion_tokens"] = count_tokens(json.dumps(chat_completion_result, ensure_ascii=JSON_ENSURE_ASCII))
- """
- if usage["completion_tokens"] is None:
- printd(f"usage dict was missing completion_tokens, computing on-the-fly...")
- # chat_completion_result is dict with 'role' and 'content'
- # token counter wants a string
- usage["completion_tokens"] = count_tokens(json.dumps(chat_completion_result, ensure_ascii=JSON_ENSURE_ASCII))
- """
-
- # NOTE: this is the token count that matters most
- if usage["total_tokens"] is None:
- printd(f"usage dict was missing total_tokens, computing on-the-fly...")
- usage["total_tokens"] = usage["prompt_tokens"] + usage["completion_tokens"]
-
- # unpack with response.choices[0].message.content
- response = ChatCompletionResponse(
- id=str(uuid.uuid4()), # TODO something better?
- choices=[
- Choice(
- finish_reason="stop",
- index=0,
- message=Message(
- role=chat_completion_result["role"],
- content=chat_completion_result["content"],
- tool_calls=(
- [ToolCall(id=get_tool_call_id(), type="function", function=chat_completion_result["function_call"])]
- if "function_call" in chat_completion_result
- else []
- ),
- ),
- )
- ],
- created=get_utc_time(),
- model=model,
- # "This fingerprint represents the backend configuration that the model runs with."
- # system_fingerprint=user if user is not None else "null",
- system_fingerprint=None,
- object="chat.completion",
- usage=UsageStatistics(**usage),
- )
- printd(response)
- return response
-
-
-def generate_grammar_and_documentation(
- functions_python: dict,
- add_inner_thoughts_top_level: bool,
- add_inner_thoughts_param_level: bool,
- allow_only_inner_thoughts: bool,
-):
- from memgpt.utils import printd
-
- assert not (
- add_inner_thoughts_top_level and add_inner_thoughts_param_level
- ), "Can only place inner thoughts in one location in the grammar generator"
-
- grammar_function_models = []
- # create_dynamic_model_from_function will add inner thoughts to the function parameters if add_inner_thoughts is True.
- # generate_gbnf_grammar_and_documentation will add inner thoughts to the outer object of the function parameters if add_inner_thoughts is True.
- for key, func in functions_python.items():
- grammar_function_models.append(create_dynamic_model_from_function(func, add_inner_thoughts=add_inner_thoughts_param_level))
- grammar, documentation = generate_gbnf_grammar_and_documentation(
- grammar_function_models,
- outer_object_name="function",
- outer_object_content="params",
- model_prefix="function",
- fields_prefix="params",
- add_inner_thoughts=add_inner_thoughts_top_level,
- allow_only_inner_thoughts=allow_only_inner_thoughts,
- )
- printd(grammar)
- return grammar, documentation
+"""Key idea: create drop-in replacement for agent's ChatCompletion call that runs on an OpenLLM backend"""
+
+import json
+import uuid
+
+import requests
+
+from memgpt.constants import CLI_WARNING_PREFIX, JSON_ENSURE_ASCII
+from memgpt.errors import LocalLLMConnectionError, LocalLLMError
+from memgpt.local_llm.constants import DEFAULT_WRAPPER
+from memgpt.local_llm.function_parser import patch_function
+from memgpt.local_llm.grammars.gbnf_grammar_generator import (
+ create_dynamic_model_from_function,
+ generate_gbnf_grammar_and_documentation,
+)
+from memgpt.local_llm.groq.api import get_groq_completion
+from memgpt.local_llm.koboldcpp.api import get_koboldcpp_completion
+from memgpt.local_llm.llamacpp.api import get_llamacpp_completion
+from memgpt.local_llm.llm_chat_completion_wrappers import simple_summary_wrapper
+from memgpt.local_llm.lmstudio.api import get_lmstudio_completion
+from memgpt.local_llm.ollama.api import get_ollama_completion
+from memgpt.local_llm.utils import count_tokens, get_available_wrappers
+from memgpt.local_llm.vllm.api import get_vllm_completion
+from memgpt.local_llm.webui.api import get_webui_completion
+from memgpt.local_llm.webui.legacy_api import (
+ get_webui_completion as get_webui_completion_legacy,
+)
+from memgpt.models.chat_completion_response import (
+ ChatCompletionResponse,
+ Choice,
+ Message,
+ ToolCall,
+ UsageStatistics,
+)
+from memgpt.prompts.gpt_summarize import SYSTEM as SUMMARIZE_SYSTEM_MESSAGE
+from memgpt.utils import get_tool_call_id, get_utc_time
+
+has_shown_warning = False
+grammar_supported_backends = ["koboldcpp", "llamacpp", "webui", "webui-legacy"]
+
+
+def get_chat_completion(
+ model,
+ # no model required (except for Ollama), since the model is fixed to whatever you set in your own backend
+ messages,
+ functions=None,
+ functions_python=None,
+ function_call="auto",
+ context_window=None,
+ user=None,
+ # required
+ wrapper=None,
+ endpoint=None,
+ endpoint_type=None,
+ # optional cleanup
+ function_correction=True,
+ # extra hints to allow for additional prompt formatting hacks
+ # TODO this could alternatively be supported via passing function_call="send_message" into the wrapper
+ first_message=False,
+ # optional auth headers
+ auth_type=None,
+ auth_key=None,
+) -> ChatCompletionResponse:
+ from memgpt.utils import printd
+
+ assert context_window is not None, "Local LLM calls need the context length to be explicitly set"
+ assert endpoint is not None, "Local LLM calls need the endpoint (eg http://localendpoint:1234) to be explicitly set"
+ assert endpoint_type is not None, "Local LLM calls need the endpoint type (eg webui) to be explicitly set"
+ global has_shown_warning
+ grammar = None
+
+ # TODO: eventually just process Message object
+ if not isinstance(messages[0], dict):
+ messages = [m.to_openai_dict() for m in messages]
+
+ if function_call is not None and function_call != "auto":
+ raise ValueError(f"function_call == {function_call} not supported (auto or None only)")
+
+ available_wrappers = get_available_wrappers()
+ documentation = None
+
+ # Special case for if the call we're making is coming from the summarizer
+ if messages[0]["role"] == "system" and messages[0]["content"].strip() == SUMMARIZE_SYSTEM_MESSAGE.strip():
+ llm_wrapper = simple_summary_wrapper.SimpleSummaryWrapper()
+
+ # Select a default prompt formatter
+ elif wrapper is None:
+ # Warn the user that we're using the fallback
+ if not has_shown_warning:
+ print(
+ f"{CLI_WARNING_PREFIX}no wrapper specified for local LLM, using the default wrapper (you can remove this warning by specifying the wrapper with --model-wrapper)"
+ )
+ has_shown_warning = True
+
+ llm_wrapper = DEFAULT_WRAPPER()
+
+ # User provided an incorrect prompt formatter
+ elif wrapper not in available_wrappers:
+ raise ValueError(f"Could not find requested wrapper '{wrapper} in available wrappers list:\n{', '.join(available_wrappers)}")
+
+ # User provided a correct prompt formatter
+ else:
+ llm_wrapper = available_wrappers[wrapper]
+
+ # If the wrapper uses grammar, generate the grammar using the grammar generating function
+ # TODO move this to a flag
+ if wrapper is not None and "grammar" in wrapper:
+ # When using grammars, we don't want to do any extras output tricks like appending a response prefix
+ setattr(llm_wrapper, "assistant_prefix_extra_first_message", "")
+ setattr(llm_wrapper, "assistant_prefix_extra", "")
+
+ # TODO find a better way to do this than string matching (eg an attribute)
+ if "noforce" in wrapper:
+ # "noforce" means that the prompt formatter expects inner thoughts as a top-level parameter
+ # this is closer to the OpenAI style since it allows for messages w/o any function calls
+ # however, with bad LLMs it makes it easier for the LLM to "forget" to call any of the functions
+ grammar, documentation = generate_grammar_and_documentation(
+ functions_python=functions_python,
+ add_inner_thoughts_top_level=True,
+ add_inner_thoughts_param_level=False,
+ allow_only_inner_thoughts=True,
+ )
+ else:
+ # otherwise, the other prompt formatters will insert inner thoughts as a function call parameter (by default)
+ # this means that every response from the LLM will be required to call a function
+ grammar, documentation = generate_grammar_and_documentation(
+ functions_python=functions_python,
+ add_inner_thoughts_top_level=False,
+ add_inner_thoughts_param_level=True,
+ allow_only_inner_thoughts=False,
+ )
+ printd(grammar)
+
+ if grammar is not None and endpoint_type not in grammar_supported_backends:
+ print(
+ f"{CLI_WARNING_PREFIX}grammars are currently not supported when using {endpoint_type} as the MemGPT local LLM backend (supported: {', '.join(grammar_supported_backends)})"
+ )
+ grammar = None
+
+ # First step: turn the message sequence into a prompt that the model expects
+ try:
+ # if hasattr(llm_wrapper, "supports_first_message"):
+ if hasattr(llm_wrapper, "supports_first_message") and llm_wrapper.supports_first_message:
+ prompt = llm_wrapper.chat_completion_to_prompt(
+ messages=messages, functions=functions, first_message=first_message, function_documentation=documentation
+ )
+ else:
+ prompt = llm_wrapper.chat_completion_to_prompt(messages=messages, functions=functions, function_documentation=documentation)
+
+ printd(prompt)
+ except Exception as e:
+ print(e)
+ raise LocalLLMError(
+ f"Failed to convert ChatCompletion messages into prompt string with wrapper {str(llm_wrapper)} - error: {str(e)}"
+ )
+
+ try:
+ if endpoint_type == "webui":
+ result, usage = get_webui_completion(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
+ elif endpoint_type == "webui-legacy":
+ result, usage = get_webui_completion_legacy(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
+ elif endpoint_type == "lmstudio":
+ result, usage = get_lmstudio_completion(endpoint, auth_type, auth_key, prompt, context_window, api="completions")
+ elif endpoint_type == "lmstudio-legacy":
+ result, usage = get_lmstudio_completion(endpoint, auth_type, auth_key, prompt, context_window, api="chat")
+ elif endpoint_type == "llamacpp":
+ result, usage = get_llamacpp_completion(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
+ elif endpoint_type == "koboldcpp":
+ result, usage = get_koboldcpp_completion(endpoint, auth_type, auth_key, prompt, context_window, grammar=grammar)
+ elif endpoint_type == "ollama":
+ result, usage = get_ollama_completion(endpoint, auth_type, auth_key, model, prompt, context_window)
+ elif endpoint_type == "vllm":
+ result, usage = get_vllm_completion(endpoint, auth_type, auth_key, model, prompt, context_window, user)
+ elif endpoint_type == "groq":
+ result, usage = get_groq_completion(endpoint, auth_type, auth_key, model, prompt, context_window)
+ else:
+ raise LocalLLMError(
+ f"Invalid endpoint type {endpoint_type}, please set variable depending on your backend (webui, lmstudio, llamacpp, koboldcpp)"
+ )
+ except requests.exceptions.ConnectionError as e:
+ raise LocalLLMConnectionError(f"Unable to connect to endpoint {endpoint}")
+
+ if result is None or result == "":
+ raise LocalLLMError(f"Got back an empty response string from {endpoint}")
+ printd(f"Raw LLM output:\n====\n{result}\n====")
+
+ try:
+ if hasattr(llm_wrapper, "supports_first_message") and llm_wrapper.supports_first_message:
+ chat_completion_result = llm_wrapper.output_to_chat_completion_response(result, first_message=first_message)
+ else:
+ chat_completion_result = llm_wrapper.output_to_chat_completion_response(result)
+ printd(json.dumps(chat_completion_result, indent=2, ensure_ascii=JSON_ENSURE_ASCII))
+ except Exception as e:
+ raise LocalLLMError(f"Failed to parse JSON from local LLM response - error: {str(e)}")
+
+ # Run through some manual function correction (optional)
+ if function_correction:
+ chat_completion_result = patch_function(message_history=messages, new_message=chat_completion_result)
+
+ # Fill in potential missing usage information (used for tracking token use)
+ if not ("prompt_tokens" in usage and "completion_tokens" in usage and "total_tokens" in usage):
+ raise LocalLLMError(f"usage dict in response was missing fields ({usage})")
+
+ if usage["prompt_tokens"] is None:
+ printd(f"usage dict was missing prompt_tokens, computing on-the-fly...")
+ usage["prompt_tokens"] = count_tokens(prompt)
+
+ # NOTE: we should compute on-the-fly anyways since we might have to correct for errors during JSON parsing
+ usage["completion_tokens"] = count_tokens(json.dumps(chat_completion_result, ensure_ascii=JSON_ENSURE_ASCII))
+ """
+ if usage["completion_tokens"] is None:
+ printd(f"usage dict was missing completion_tokens, computing on-the-fly...")
+ # chat_completion_result is dict with 'role' and 'content'
+ # token counter wants a string
+ usage["completion_tokens"] = count_tokens(json.dumps(chat_completion_result, ensure_ascii=JSON_ENSURE_ASCII))
+ """
+
+ # NOTE: this is the token count that matters most
+ if usage["total_tokens"] is None:
+ printd(f"usage dict was missing total_tokens, computing on-the-fly...")
+ usage["total_tokens"] = usage["prompt_tokens"] + usage["completion_tokens"]
+
+ # unpack with response.choices[0].message.content
+ response = ChatCompletionResponse(
+ id=str(uuid.uuid4()), # TODO something better?
+ choices=[
+ Choice(
+ finish_reason="stop",
+ index=0,
+ message=Message(
+ role=chat_completion_result["role"],
+ content=chat_completion_result["content"],
+ tool_calls=(
+ [ToolCall(id=get_tool_call_id(), type="function", function=chat_completion_result["function_call"])]
+ if "function_call" in chat_completion_result
+ else []
+ ),
+ ),
+ )
+ ],
+ created=get_utc_time(),
+ model=model,
+ # "This fingerprint represents the backend configuration that the model runs with."
+ # system_fingerprint=user if user is not None else "null",
+ system_fingerprint=None,
+ object="chat.completion",
+ usage=UsageStatistics(**usage),
+ )
+ printd(response)
+ return response
+
+
+def generate_grammar_and_documentation(
+ functions_python: dict,
+ add_inner_thoughts_top_level: bool,
+ add_inner_thoughts_param_level: bool,
+ allow_only_inner_thoughts: bool,
+):
+ from memgpt.utils import printd
+
+ assert not (
+ add_inner_thoughts_top_level and add_inner_thoughts_param_level
+ ), "Can only place inner thoughts in one location in the grammar generator"
+
+ grammar_function_models = []
+ # create_dynamic_model_from_function will add inner thoughts to the function parameters if add_inner_thoughts is True.
+ # generate_gbnf_grammar_and_documentation will add inner thoughts to the outer object of the function parameters if add_inner_thoughts is True.
+ for key, func in functions_python.items():
+ grammar_function_models.append(create_dynamic_model_from_function(func, add_inner_thoughts=add_inner_thoughts_param_level))
+ grammar, documentation = generate_gbnf_grammar_and_documentation(
+ grammar_function_models,
+ outer_object_name="function",
+ outer_object_content="params",
+ model_prefix="function",
+ fields_prefix="params",
+ add_inner_thoughts=add_inner_thoughts_top_level,
+ allow_only_inner_thoughts=allow_only_inner_thoughts,
+ )
+ printd(grammar)
+ return grammar, documentation
diff --git a/memgpt/local_llm/llm_chat_completion_wrappers/airoboros.py b/memgpt/local_llm/llm_chat_completion_wrappers/airoboros.py
index 352a1b3f..2f870c3b 100644
--- a/memgpt/local_llm/llm_chat_completion_wrappers/airoboros.py
+++ b/memgpt/local_llm/llm_chat_completion_wrappers/airoboros.py
@@ -1,453 +1,453 @@
-import json
-
-from ...constants import JSON_ENSURE_ASCII, JSON_LOADS_STRICT
-from ...errors import LLMJSONParsingError
-from ..json_parser import clean_json
-from .wrapper_base import LLMChatCompletionWrapper
-
-
-class Airoboros21Wrapper(LLMChatCompletionWrapper):
- """Wrapper for Airoboros 70b v2.1: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1
-
- Note: this wrapper formats a prompt that only generates JSON, no inner thoughts
- """
-
- def __init__(
- self,
- simplify_json_content=True,
- clean_function_args=True,
- include_assistant_prefix=True,
- include_opening_brace_in_prefix=True,
- include_section_separators=True,
- ):
- self.simplify_json_content = simplify_json_content
- self.clean_func_args = clean_function_args
- self.include_assistant_prefix = include_assistant_prefix
- self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
- self.include_section_separators = include_section_separators
-
- def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
- """Example for airoboros: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#prompt-format
-
- A chat.
- USER: {prompt}
- ASSISTANT:
-
- Functions support: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#agentfunction-calling
-
- As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
-
- Input: I want to know how many times 'Python' is mentioned in my text file.
-
- Available functions:
- file_analytics:
- description: This tool performs various operations on a text file.
- params:
- action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
- filters:
- keyword: The word or phrase we want to search for.
-
- OpenAI functions schema style:
-
- {
- "name": "send_message",
- "description": "Sends a message to the human user",
- "parameters": {
- "type": "object",
- "properties": {
- # https://json-schema.org/understanding-json-schema/reference/array.html
- "message": {
- "type": "string",
- "description": "Message contents. All unicode (including emojis) are supported.",
- },
- },
- "required": ["message"],
- }
- },
- """
- prompt = ""
-
- # System insturctions go first
- assert messages[0]["role"] == "system"
- prompt += messages[0]["content"]
-
- # Next is the functions preamble
- def create_function_description(schema):
- # airorobos style
- func_str = ""
- func_str += f"{schema['name']}:"
- func_str += f"\n description: {schema['description']}"
- func_str += f"\n params:"
- for param_k, param_v in schema["parameters"]["properties"].items():
- # TODO we're ignoring type
- func_str += f"\n {param_k}: {param_v['description']}"
- # TODO we're ignoring schema['parameters']['required']
- return func_str
-
- # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
- prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
- prompt += f"\nAvailable functions:"
- if function_documentation is not None:
- prompt += f"\n{function_documentation}"
- else:
- for function_dict in functions:
- prompt += f"\n{create_function_description(function_dict)}"
-
- def create_function_call(function_call):
- """Go from ChatCompletion to Airoboros style function trace (in prompt)
-
- ChatCompletion data (inside message['function_call']):
- "function_call": {
- "name": ...
- "arguments": {
- "arg1": val1,
- ...
- }
-
- Airoboros output:
- {
- "function": "send_message",
- "params": {
- "message": "Hello there! I am Sam, an AI developed by Liminal Corp. How can I assist you today?"
- }
- }
- """
- airo_func_call = {
- "function": function_call["name"],
- "params": json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
- }
- return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
-
- # Add a sep for the conversation
- if self.include_section_separators:
- prompt += "\n### INPUT"
-
- # Last are the user/assistant messages
- for message in messages[1:]:
- assert message["role"] in ["user", "assistant", "function", "tool"], message
-
- if message["role"] == "user":
- if self.simplify_json_content:
- try:
- content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
- content_simple = content_json["message"]
- prompt += f"\nUSER: {content_simple}"
- except:
- prompt += f"\nUSER: {message['content']}"
- elif message["role"] == "assistant":
- prompt += f"\nASSISTANT: {message['content']}"
- # need to add the function call if there was one
- if "function_call" in message and message["function_call"]:
- prompt += f"\n{create_function_call(message['function_call'])}"
- elif message["role"] in ["function", "tool"]:
- # TODO find a good way to add this
- # prompt += f"\nASSISTANT: (function return) {message['content']}"
- prompt += f"\nFUNCTION RETURN: {message['content']}"
- continue
- else:
- raise ValueError(message)
-
- # Add a sep for the response
- if self.include_section_separators:
- prompt += "\n### RESPONSE"
-
- if self.include_assistant_prefix:
- prompt += f"\nASSISTANT:"
- if self.include_opening_brance_in_prefix:
- prompt += "\n{"
-
- print(prompt)
- return prompt
-
- def clean_function_args(self, function_name, function_args):
- """Some basic MemGPT-specific cleaning of function args"""
- cleaned_function_name = function_name
- cleaned_function_args = function_args.copy() if function_args is not None else {}
-
- if function_name == "send_message":
- # strip request_heartbeat
- cleaned_function_args.pop("request_heartbeat", None)
-
- # TODO more cleaning to fix errors LLM makes
- return cleaned_function_name, cleaned_function_args
-
- def output_to_chat_completion_response(self, raw_llm_output):
- """Turn raw LLM output into a ChatCompletion style response with:
- "message" = {
- "role": "assistant",
- "content": ...,
- "function_call": {
- "name": ...
- "arguments": {
- "arg1": val1,
- ...
- }
- }
- }
- """
- if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
- raw_llm_output = "{" + raw_llm_output
-
- try:
- function_json_output = clean_json(raw_llm_output)
- except Exception as e:
- raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
- try:
- function_name = function_json_output["function"]
- function_parameters = function_json_output["params"]
- except KeyError as e:
- raise LLMJSONParsingError(f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}")
-
- if self.clean_func_args:
- function_name, function_parameters = self.clean_function_args(function_name, function_parameters)
-
- message = {
- "role": "assistant",
- "content": None,
- "function_call": {
- "name": function_name,
- "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
- },
- }
- return message
-
-
-class Airoboros21InnerMonologueWrapper(Airoboros21Wrapper):
- """Still expect only JSON outputs from model, but add inner monologue as a field"""
-
- def __init__(
- self,
- simplify_json_content=True,
- clean_function_args=True,
- include_assistant_prefix=True,
- # include_opening_brace_in_prefix=True,
- # assistant_prefix_extra="\n{"
- # assistant_prefix_extra='\n{\n "function": ',
- assistant_prefix_extra='\n{\n "function":',
- include_section_separators=True,
- ):
- self.simplify_json_content = simplify_json_content
- self.clean_func_args = clean_function_args
- self.include_assistant_prefix = include_assistant_prefix
- # self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
- self.assistant_prefix_extra = assistant_prefix_extra
- self.include_section_separators = include_section_separators
-
- def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
- """Example for airoboros: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#prompt-format
-
- A chat.
- USER: {prompt}
- ASSISTANT:
-
- Functions support: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#agentfunction-calling
-
- As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
-
- Input: I want to know how many times 'Python' is mentioned in my text file.
-
- Available functions:
- file_analytics:
- description: This tool performs various operations on a text file.
- params:
- action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
- filters:
- keyword: The word or phrase we want to search for.
-
- OpenAI functions schema style:
-
- {
- "name": "send_message",
- "description": "Sends a message to the human user",
- "parameters": {
- "type": "object",
- "properties": {
- # https://json-schema.org/understanding-json-schema/reference/array.html
- "message": {
- "type": "string",
- "description": "Message contents. All unicode (including emojis) are supported.",
- },
- },
- "required": ["message"],
- }
- },
- """
- prompt = ""
-
- # System insturctions go first
- assert messages[0]["role"] == "system"
- prompt += messages[0]["content"]
-
- # Next is the functions preamble
- def create_function_description(schema, add_inner_thoughts=True):
- # airorobos style
- func_str = ""
- func_str += f"{schema['name']}:"
- func_str += f"\n description: {schema['description']}"
- func_str += f"\n params:"
- if add_inner_thoughts:
- func_str += f"\n inner_thoughts: Deep inner monologue private to you only."
- for param_k, param_v in schema["parameters"]["properties"].items():
- # TODO we're ignoring type
- func_str += f"\n {param_k}: {param_v['description']}"
- # TODO we're ignoring schema['parameters']['required']
- return func_str
-
- # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
- prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
- prompt += f"\nAvailable functions:"
- if function_documentation is not None:
- prompt += f"\n{function_documentation}"
- else:
- for function_dict in functions:
- prompt += f"\n{create_function_description(function_dict)}"
-
- def create_function_call(function_call, inner_thoughts=None):
- """Go from ChatCompletion to Airoboros style function trace (in prompt)
-
- ChatCompletion data (inside message['function_call']):
- "function_call": {
- "name": ...
- "arguments": {
- "arg1": val1,
- ...
- }
-
- Airoboros output:
- {
- "function": "send_message",
- "params": {
- "message": "Hello there! I am Sam, an AI developed by Liminal Corp. How can I assist you today?"
- }
- }
- """
- airo_func_call = {
- "function": function_call["name"],
- "params": {
- "inner_thoughts": inner_thoughts,
- **json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
- },
- }
- return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
-
- # Add a sep for the conversation
- if self.include_section_separators:
- prompt += "\n### INPUT"
-
- # Last are the user/assistant messages
- for message in messages[1:]:
- assert message["role"] in ["user", "assistant", "function", "tool"], message
-
- if message["role"] == "user":
- # Support for AutoGen naming of agents
- if "name" in message:
- user_prefix = message["name"].strip()
- user_prefix = f"USER ({user_prefix})"
- else:
- user_prefix = "USER"
- if self.simplify_json_content:
- try:
- content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
- content_simple = content_json["message"]
- prompt += f"\n{user_prefix}: {content_simple}"
- except:
- prompt += f"\n{user_prefix}: {message['content']}"
- elif message["role"] == "assistant":
- # Support for AutoGen naming of agents
- if "name" in message:
- assistant_prefix = message["name"].strip()
- assistant_prefix = f"ASSISTANT ({assistant_prefix})"
- else:
- assistant_prefix = "ASSISTANT"
- prompt += f"\n{assistant_prefix}:"
- # need to add the function call if there was one
- inner_thoughts = message["content"]
- if "function_call" in message and message["function_call"]:
- prompt += f"\n{create_function_call(message['function_call'], inner_thoughts=inner_thoughts)}"
- elif message["role"] in ["function", "tool"]:
- # TODO find a good way to add this
- # prompt += f"\nASSISTANT: (function return) {message['content']}"
- prompt += f"\nFUNCTION RETURN: {message['content']}"
- continue
- else:
- raise ValueError(message)
-
- # Add a sep for the response
- if self.include_section_separators:
- prompt += "\n### RESPONSE"
-
- if self.include_assistant_prefix:
- prompt += f"\nASSISTANT:"
- if self.assistant_prefix_extra:
- prompt += self.assistant_prefix_extra
-
- return prompt
-
- def clean_function_args(self, function_name, function_args):
- """Some basic MemGPT-specific cleaning of function args"""
- cleaned_function_name = function_name
- cleaned_function_args = function_args.copy() if function_args is not None else {}
-
- if function_name == "send_message":
- # strip request_heartbeat
- cleaned_function_args.pop("request_heartbeat", None)
-
- inner_thoughts = None
- if "inner_thoughts" in function_args:
- inner_thoughts = cleaned_function_args.pop("inner_thoughts")
-
- # TODO more cleaning to fix errors LLM makes
- return inner_thoughts, cleaned_function_name, cleaned_function_args
-
- def output_to_chat_completion_response(self, raw_llm_output):
- """Turn raw LLM output into a ChatCompletion style response with:
- "message" = {
- "role": "assistant",
- "content": ...,
- "function_call": {
- "name": ...
- "arguments": {
- "arg1": val1,
- ...
- }
- }
- }
- """
- # if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
- # raw_llm_output = "{" + raw_llm_output
- if self.assistant_prefix_extra and raw_llm_output[: len(self.assistant_prefix_extra)] != self.assistant_prefix_extra:
- # print(f"adding prefix back to llm, raw_llm_output=\n{raw_llm_output}")
- raw_llm_output = self.assistant_prefix_extra + raw_llm_output
- # print(f"->\n{raw_llm_output}")
-
- try:
- function_json_output = clean_json(raw_llm_output)
- except Exception as e:
- raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
- try:
- # NOTE: weird bug can happen where 'function' gets nested if the prefix in the prompt isn't abided by
- if isinstance(function_json_output["function"], dict):
- function_json_output = function_json_output["function"]
- function_name = function_json_output["function"]
- function_parameters = function_json_output["params"]
- except KeyError as e:
- raise LLMJSONParsingError(
- f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}. JSON result was:\n{function_json_output}"
- )
-
- if self.clean_func_args:
- (
- inner_thoughts,
- function_name,
- function_parameters,
- ) = self.clean_function_args(function_name, function_parameters)
-
- message = {
- "role": "assistant",
- "content": inner_thoughts,
- "function_call": {
- "name": function_name,
- "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
- },
- }
- return message
+import json
+
+from ...constants import JSON_ENSURE_ASCII, JSON_LOADS_STRICT
+from ...errors import LLMJSONParsingError
+from ..json_parser import clean_json
+from .wrapper_base import LLMChatCompletionWrapper
+
+
+class Airoboros21Wrapper(LLMChatCompletionWrapper):
+ """Wrapper for Airoboros 70b v2.1: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1
+
+ Note: this wrapper formats a prompt that only generates JSON, no inner thoughts
+ """
+
+ def __init__(
+ self,
+ simplify_json_content=True,
+ clean_function_args=True,
+ include_assistant_prefix=True,
+ include_opening_brace_in_prefix=True,
+ include_section_separators=True,
+ ):
+ self.simplify_json_content = simplify_json_content
+ self.clean_func_args = clean_function_args
+ self.include_assistant_prefix = include_assistant_prefix
+ self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
+ self.include_section_separators = include_section_separators
+
+ def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
+ """Example for airoboros: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#prompt-format
+
+ A chat.
+ USER: {prompt}
+ ASSISTANT:
+
+ Functions support: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#agentfunction-calling
+
+ As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
+
+ Input: I want to know how many times 'Python' is mentioned in my text file.
+
+ Available functions:
+ file_analytics:
+ description: This tool performs various operations on a text file.
+ params:
+ action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
+ filters:
+ keyword: The word or phrase we want to search for.
+
+ OpenAI functions schema style:
+
+ {
+ "name": "send_message",
+ "description": "Sends a message to the human user",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ # https://json-schema.org/understanding-json-schema/reference/array.html
+ "message": {
+ "type": "string",
+ "description": "Message contents. All unicode (including emojis) are supported.",
+ },
+ },
+ "required": ["message"],
+ }
+ },
+ """
+ prompt = ""
+
+ # System insturctions go first
+ assert messages[0]["role"] == "system"
+ prompt += messages[0]["content"]
+
+ # Next is the functions preamble
+ def create_function_description(schema):
+ # airorobos style
+ func_str = ""
+ func_str += f"{schema['name']}:"
+ func_str += f"\n description: {schema['description']}"
+ func_str += f"\n params:"
+ for param_k, param_v in schema["parameters"]["properties"].items():
+ # TODO we're ignoring type
+ func_str += f"\n {param_k}: {param_v['description']}"
+ # TODO we're ignoring schema['parameters']['required']
+ return func_str
+
+ # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
+ prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
+ prompt += f"\nAvailable functions:"
+ if function_documentation is not None:
+ prompt += f"\n{function_documentation}"
+ else:
+ for function_dict in functions:
+ prompt += f"\n{create_function_description(function_dict)}"
+
+ def create_function_call(function_call):
+ """Go from ChatCompletion to Airoboros style function trace (in prompt)
+
+ ChatCompletion data (inside message['function_call']):
+ "function_call": {
+ "name": ...
+ "arguments": {
+ "arg1": val1,
+ ...
+ }
+
+ Airoboros output:
+ {
+ "function": "send_message",
+ "params": {
+ "message": "Hello there! I am Sam, an AI developed by Liminal Corp. How can I assist you today?"
+ }
+ }
+ """
+ airo_func_call = {
+ "function": function_call["name"],
+ "params": json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
+ }
+ return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
+
+ # Add a sep for the conversation
+ if self.include_section_separators:
+ prompt += "\n### INPUT"
+
+ # Last are the user/assistant messages
+ for message in messages[1:]:
+ assert message["role"] in ["user", "assistant", "function", "tool"], message
+
+ if message["role"] == "user":
+ if self.simplify_json_content:
+ try:
+ content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
+ content_simple = content_json["message"]
+ prompt += f"\nUSER: {content_simple}"
+ except:
+ prompt += f"\nUSER: {message['content']}"
+ elif message["role"] == "assistant":
+ prompt += f"\nASSISTANT: {message['content']}"
+ # need to add the function call if there was one
+ if "function_call" in message and message["function_call"]:
+ prompt += f"\n{create_function_call(message['function_call'])}"
+ elif message["role"] in ["function", "tool"]:
+ # TODO find a good way to add this
+ # prompt += f"\nASSISTANT: (function return) {message['content']}"
+ prompt += f"\nFUNCTION RETURN: {message['content']}"
+ continue
+ else:
+ raise ValueError(message)
+
+ # Add a sep for the response
+ if self.include_section_separators:
+ prompt += "\n### RESPONSE"
+
+ if self.include_assistant_prefix:
+ prompt += f"\nASSISTANT:"
+ if self.include_opening_brance_in_prefix:
+ prompt += "\n{"
+
+ print(prompt)
+ return prompt
+
+ def clean_function_args(self, function_name, function_args):
+ """Some basic MemGPT-specific cleaning of function args"""
+ cleaned_function_name = function_name
+ cleaned_function_args = function_args.copy() if function_args is not None else {}
+
+ if function_name == "send_message":
+ # strip request_heartbeat
+ cleaned_function_args.pop("request_heartbeat", None)
+
+ # TODO more cleaning to fix errors LLM makes
+ return cleaned_function_name, cleaned_function_args
+
+ def output_to_chat_completion_response(self, raw_llm_output):
+ """Turn raw LLM output into a ChatCompletion style response with:
+ "message" = {
+ "role": "assistant",
+ "content": ...,
+ "function_call": {
+ "name": ...
+ "arguments": {
+ "arg1": val1,
+ ...
+ }
+ }
+ }
+ """
+ if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
+ raw_llm_output = "{" + raw_llm_output
+
+ try:
+ function_json_output = clean_json(raw_llm_output)
+ except Exception as e:
+ raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
+ try:
+ function_name = function_json_output["function"]
+ function_parameters = function_json_output["params"]
+ except KeyError as e:
+ raise LLMJSONParsingError(f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}")
+
+ if self.clean_func_args:
+ function_name, function_parameters = self.clean_function_args(function_name, function_parameters)
+
+ message = {
+ "role": "assistant",
+ "content": None,
+ "function_call": {
+ "name": function_name,
+ "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
+ },
+ }
+ return message
+
+
+class Airoboros21InnerMonologueWrapper(Airoboros21Wrapper):
+ """Still expect only JSON outputs from model, but add inner monologue as a field"""
+
+ def __init__(
+ self,
+ simplify_json_content=True,
+ clean_function_args=True,
+ include_assistant_prefix=True,
+ # include_opening_brace_in_prefix=True,
+ # assistant_prefix_extra="\n{"
+ # assistant_prefix_extra='\n{\n "function": ',
+ assistant_prefix_extra='\n{\n "function":',
+ include_section_separators=True,
+ ):
+ self.simplify_json_content = simplify_json_content
+ self.clean_func_args = clean_function_args
+ self.include_assistant_prefix = include_assistant_prefix
+ # self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
+ self.assistant_prefix_extra = assistant_prefix_extra
+ self.include_section_separators = include_section_separators
+
+ def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
+ """Example for airoboros: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#prompt-format
+
+ A chat.
+ USER: {prompt}
+ ASSISTANT:
+
+ Functions support: https://huggingface.co/jondurbin/airoboros-l2-70b-2.1#agentfunction-calling
+
+ As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
+
+ Input: I want to know how many times 'Python' is mentioned in my text file.
+
+ Available functions:
+ file_analytics:
+ description: This tool performs various operations on a text file.
+ params:
+ action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
+ filters:
+ keyword: The word or phrase we want to search for.
+
+ OpenAI functions schema style:
+
+ {
+ "name": "send_message",
+ "description": "Sends a message to the human user",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ # https://json-schema.org/understanding-json-schema/reference/array.html
+ "message": {
+ "type": "string",
+ "description": "Message contents. All unicode (including emojis) are supported.",
+ },
+ },
+ "required": ["message"],
+ }
+ },
+ """
+ prompt = ""
+
+ # System insturctions go first
+ assert messages[0]["role"] == "system"
+ prompt += messages[0]["content"]
+
+ # Next is the functions preamble
+ def create_function_description(schema, add_inner_thoughts=True):
+ # airorobos style
+ func_str = ""
+ func_str += f"{schema['name']}:"
+ func_str += f"\n description: {schema['description']}"
+ func_str += f"\n params:"
+ if add_inner_thoughts:
+ func_str += f"\n inner_thoughts: Deep inner monologue private to you only."
+ for param_k, param_v in schema["parameters"]["properties"].items():
+ # TODO we're ignoring type
+ func_str += f"\n {param_k}: {param_v['description']}"
+ # TODO we're ignoring schema['parameters']['required']
+ return func_str
+
+ # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
+ prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
+ prompt += f"\nAvailable functions:"
+ if function_documentation is not None:
+ prompt += f"\n{function_documentation}"
+ else:
+ for function_dict in functions:
+ prompt += f"\n{create_function_description(function_dict)}"
+
+ def create_function_call(function_call, inner_thoughts=None):
+ """Go from ChatCompletion to Airoboros style function trace (in prompt)
+
+ ChatCompletion data (inside message['function_call']):
+ "function_call": {
+ "name": ...
+ "arguments": {
+ "arg1": val1,
+ ...
+ }
+
+ Airoboros output:
+ {
+ "function": "send_message",
+ "params": {
+ "message": "Hello there! I am Sam, an AI developed by Liminal Corp. How can I assist you today?"
+ }
+ }
+ """
+ airo_func_call = {
+ "function": function_call["name"],
+ "params": {
+ "inner_thoughts": inner_thoughts,
+ **json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
+ },
+ }
+ return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
+
+ # Add a sep for the conversation
+ if self.include_section_separators:
+ prompt += "\n### INPUT"
+
+ # Last are the user/assistant messages
+ for message in messages[1:]:
+ assert message["role"] in ["user", "assistant", "function", "tool"], message
+
+ if message["role"] == "user":
+ # Support for AutoGen naming of agents
+ if "name" in message:
+ user_prefix = message["name"].strip()
+ user_prefix = f"USER ({user_prefix})"
+ else:
+ user_prefix = "USER"
+ if self.simplify_json_content:
+ try:
+ content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
+ content_simple = content_json["message"]
+ prompt += f"\n{user_prefix}: {content_simple}"
+ except:
+ prompt += f"\n{user_prefix}: {message['content']}"
+ elif message["role"] == "assistant":
+ # Support for AutoGen naming of agents
+ if "name" in message:
+ assistant_prefix = message["name"].strip()
+ assistant_prefix = f"ASSISTANT ({assistant_prefix})"
+ else:
+ assistant_prefix = "ASSISTANT"
+ prompt += f"\n{assistant_prefix}:"
+ # need to add the function call if there was one
+ inner_thoughts = message["content"]
+ if "function_call" in message and message["function_call"]:
+ prompt += f"\n{create_function_call(message['function_call'], inner_thoughts=inner_thoughts)}"
+ elif message["role"] in ["function", "tool"]:
+ # TODO find a good way to add this
+ # prompt += f"\nASSISTANT: (function return) {message['content']}"
+ prompt += f"\nFUNCTION RETURN: {message['content']}"
+ continue
+ else:
+ raise ValueError(message)
+
+ # Add a sep for the response
+ if self.include_section_separators:
+ prompt += "\n### RESPONSE"
+
+ if self.include_assistant_prefix:
+ prompt += f"\nASSISTANT:"
+ if self.assistant_prefix_extra:
+ prompt += self.assistant_prefix_extra
+
+ return prompt
+
+ def clean_function_args(self, function_name, function_args):
+ """Some basic MemGPT-specific cleaning of function args"""
+ cleaned_function_name = function_name
+ cleaned_function_args = function_args.copy() if function_args is not None else {}
+
+ if function_name == "send_message":
+ # strip request_heartbeat
+ cleaned_function_args.pop("request_heartbeat", None)
+
+ inner_thoughts = None
+ if "inner_thoughts" in function_args:
+ inner_thoughts = cleaned_function_args.pop("inner_thoughts")
+
+ # TODO more cleaning to fix errors LLM makes
+ return inner_thoughts, cleaned_function_name, cleaned_function_args
+
+ def output_to_chat_completion_response(self, raw_llm_output):
+ """Turn raw LLM output into a ChatCompletion style response with:
+ "message" = {
+ "role": "assistant",
+ "content": ...,
+ "function_call": {
+ "name": ...
+ "arguments": {
+ "arg1": val1,
+ ...
+ }
+ }
+ }
+ """
+ # if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
+ # raw_llm_output = "{" + raw_llm_output
+ if self.assistant_prefix_extra and raw_llm_output[: len(self.assistant_prefix_extra)] != self.assistant_prefix_extra:
+ # print(f"adding prefix back to llm, raw_llm_output=\n{raw_llm_output}")
+ raw_llm_output = self.assistant_prefix_extra + raw_llm_output
+ # print(f"->\n{raw_llm_output}")
+
+ try:
+ function_json_output = clean_json(raw_llm_output)
+ except Exception as e:
+ raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
+ try:
+ # NOTE: weird bug can happen where 'function' gets nested if the prefix in the prompt isn't abided by
+ if isinstance(function_json_output["function"], dict):
+ function_json_output = function_json_output["function"]
+ function_name = function_json_output["function"]
+ function_parameters = function_json_output["params"]
+ except KeyError as e:
+ raise LLMJSONParsingError(
+ f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}. JSON result was:\n{function_json_output}"
+ )
+
+ if self.clean_func_args:
+ (
+ inner_thoughts,
+ function_name,
+ function_parameters,
+ ) = self.clean_function_args(function_name, function_parameters)
+
+ message = {
+ "role": "assistant",
+ "content": inner_thoughts,
+ "function_call": {
+ "name": function_name,
+ "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
+ },
+ }
+ return message
diff --git a/memgpt/local_llm/llm_chat_completion_wrappers/wrapper_base.py b/memgpt/local_llm/llm_chat_completion_wrappers/wrapper_base.py
index a37f73a3..01f442b1 100644
--- a/memgpt/local_llm/llm_chat_completion_wrappers/wrapper_base.py
+++ b/memgpt/local_llm/llm_chat_completion_wrappers/wrapper_base.py
@@ -1,11 +1,11 @@
-from abc import ABC, abstractmethod
-
-
-class LLMChatCompletionWrapper(ABC):
- @abstractmethod
- def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
- """Go from ChatCompletion to a single prompt string"""
-
- @abstractmethod
- def output_to_chat_completion_response(self, raw_llm_output):
- """Turn the LLM output string into a ChatCompletion response"""
+from abc import ABC, abstractmethod
+
+
+class LLMChatCompletionWrapper(ABC):
+ @abstractmethod
+ def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
+ """Go from ChatCompletion to a single prompt string"""
+
+ @abstractmethod
+ def output_to_chat_completion_response(self, raw_llm_output):
+ """Turn the LLM output string into a ChatCompletion response"""
diff --git a/memgpt/local_llm/llm_chat_completion_wrappers/zephyr.py b/memgpt/local_llm/llm_chat_completion_wrappers/zephyr.py
index 4eda496d..4e45b052 100644
--- a/memgpt/local_llm/llm_chat_completion_wrappers/zephyr.py
+++ b/memgpt/local_llm/llm_chat_completion_wrappers/zephyr.py
@@ -1,346 +1,346 @@
-import json
-
-from ...constants import JSON_ENSURE_ASCII
-from ...errors import LLMJSONParsingError
-from ..json_parser import clean_json
-from .wrapper_base import LLMChatCompletionWrapper
-
-
-class ZephyrMistralWrapper(LLMChatCompletionWrapper):
- """
- Wrapper for Zephyr Alpha and Beta, Mistral 7B:
- https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
- https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
- Note: this wrapper formats a prompt that only generates JSON, no inner thoughts
- """
-
- def __init__(
- self,
- simplify_json_content=True,
- clean_function_args=True,
- include_assistant_prefix=True,
- include_opening_brace_in_prefix=True,
- include_section_separators=False,
- ):
- self.simplify_json_content = simplify_json_content
- self.clean_func_args = clean_function_args
- self.include_assistant_prefix = include_assistant_prefix
- self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
- self.include_section_separators = include_section_separators
-
- def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
- """
- Zephyr prompt format:
- <|system|>
-
- <|user|>
- {prompt}
- <|assistant|>
- (source: https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF#prompt-template-zephyr)
- """
-
- prompt = ""
-
- IM_END_TOKEN = ""
-
- # System instructions go first
- assert messages[0]["role"] == "system"
- prompt += f"<|system|>"
- prompt += f"\n{messages[0]['content']}"
-
- # Next is the functions preamble
- def create_function_description(schema):
- # airorobos style
- func_str = ""
- func_str += f"{schema['name']}:"
- func_str += f"\n description: {schema['description']}"
- func_str += f"\n params:"
- for param_k, param_v in schema["parameters"]["properties"].items():
- # TODO we're ignoring type
- func_str += f"\n {param_k}: {param_v['description']}"
- # TODO we're ignoring schema['parameters']['required']
- return func_str
-
- # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
- prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
- prompt += f"\nAvailable functions:"
- if function_documentation is not None:
- prompt += f"\n{function_documentation}"
- else:
- for function_dict in functions:
- prompt += f"\n{create_function_description(function_dict)}"
-
- # Put functions INSIDE system message (TODO experiment with this)
- prompt += IM_END_TOKEN
-
- def create_function_call(function_call):
- airo_func_call = {
- "function": function_call["name"],
- "params": json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
- }
- return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
-
- for message in messages[1:]:
- assert message["role"] in ["user", "assistant", "function", "tool"], message
-
- if message["role"] == "user":
- if self.simplify_json_content:
- try:
- content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
- content_simple = content_json["message"]
- prompt += f"\n<|user|>\n{content_simple}{IM_END_TOKEN}"
- # prompt += f"\nUSER: {content_simple}"
- except:
- prompt += f"\n<|user|>\n{message['content']}{IM_END_TOKEN}"
- # prompt += f"\nUSER: {message['content']}"
- elif message["role"] == "assistant":
- prompt += f"\n<|assistant|>"
- if message["content"] is not None:
- prompt += f"\n{message['content']}"
- # prompt += f"\nASSISTANT: {message['content']}"
- # need to add the function call if there was one
- if "function_call" in message and message["function_call"]:
- prompt += f"\n{create_function_call(message['function_call'])}"
- prompt += f"{IM_END_TOKEN}"
- elif message["role"] in ["function", "tool"]:
- # TODO find a good way to add this
- # prompt += f"\nASSISTANT: (function return) {message['content']}"
- prompt += f"\n<|assistant|>"
- prompt += f"\nFUNCTION RETURN: {message['content']}"
- # prompt += f"\nFUNCTION RETURN: {message['content']}"
- continue
- else:
- raise ValueError(message)
-
- # Add a sep for the response
- # if self.include_section_separators:
- # prompt += "\n### RESPONSE"
-
- if self.include_assistant_prefix:
- # prompt += f"\nASSISTANT:"
- prompt += f"\n<|assistant|>"
- if self.include_opening_brance_in_prefix:
- prompt += "\n{"
-
- return prompt
-
- def clean_function_args(self, function_name, function_args):
- """Some basic MemGPT-specific cleaning of function args"""
- cleaned_function_name = function_name
- cleaned_function_args = function_args.copy() if function_args is not None else {}
-
- if function_name == "send_message":
- # strip request_heartbeat
- cleaned_function_args.pop("request_heartbeat", None)
-
- # TODO more cleaning to fix errors LLM makes
- return cleaned_function_name, cleaned_function_args
-
- def output_to_chat_completion_response(self, raw_llm_output):
- """Turn raw LLM output into a ChatCompletion style response with:
- "message" = {
- "role": "assistant",
- "content": ...,
- "function_call": {
- "name": ...
- "arguments": {
- "arg1": val1,
- ...
- }
- }
- }
- """
- if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
- raw_llm_output = "{" + raw_llm_output
-
- try:
- function_json_output = clean_json(raw_llm_output)
- except Exception as e:
- raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
- try:
- function_name = function_json_output["function"]
- function_parameters = function_json_output["params"]
- except KeyError as e:
- raise LLMJSONParsingError(f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}")
-
- if self.clean_func_args:
- function_name, function_parameters = self.clean_function_args(function_name, function_parameters)
-
- message = {
- "role": "assistant",
- "content": None,
- "function_call": {
- "name": function_name,
- "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
- },
- }
- return message
-
-
-class ZephyrMistralInnerMonologueWrapper(ZephyrMistralWrapper):
- """Still expect only JSON outputs from model, but add inner monologue as a field"""
-
- """
- Wrapper for Zephyr Alpha and Beta, Mistral 7B:
- https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
- https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
- Note: this wrapper formats a prompt with inner thoughts included
- """
-
- def __init__(
- self,
- simplify_json_content=True,
- clean_function_args=True,
- include_assistant_prefix=True,
- include_opening_brace_in_prefix=True,
- include_section_separators=True,
- ):
- self.simplify_json_content = simplify_json_content
- self.clean_func_args = clean_function_args
- self.include_assistant_prefix = include_assistant_prefix
- self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
- self.include_section_separators = include_section_separators
-
- def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
- prompt = ""
-
- IM_END_TOKEN = ""
-
- # System insturctions go first
- assert messages[0]["role"] == "system"
- prompt += messages[0]["content"]
-
- # Next is the functions preamble
- def create_function_description(schema, add_inner_thoughts=True):
- # airorobos style
- func_str = ""
- func_str += f"{schema['name']}:"
- func_str += f"\n description: {schema['description']}"
- func_str += f"\n params:"
- if add_inner_thoughts:
- func_str += f"\n inner_thoughts: Deep inner monologue private to you only."
- for param_k, param_v in schema["parameters"]["properties"].items():
- # TODO we're ignoring type
- func_str += f"\n {param_k}: {param_v['description']}"
- # TODO we're ignoring schema['parameters']['required']
- return func_str
-
- # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
- prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
- prompt += f"\nAvailable functions:"
- if function_documentation is not None:
- prompt += f"\n{function_documentation}"
- else:
- for function_dict in functions:
- prompt += f"\n{create_function_description(function_dict)}"
-
- def create_function_call(function_call, inner_thoughts=None):
- airo_func_call = {
- "function": function_call["name"],
- "params": {
- "inner_thoughts": inner_thoughts,
- **json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
- },
- }
- return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
-
- # Add a sep for the conversation
- if self.include_section_separators:
- prompt += "\n<|user|>"
-
- # Last are the user/assistant messages
- for message in messages[1:]:
- assert message["role"] in ["user", "assistant", "function", "tool"], message
-
- if message["role"] == "user":
- if self.simplify_json_content:
- try:
- content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
- content_simple = content_json["message"]
- prompt += f"\n<|user|>\n{content_simple}{IM_END_TOKEN}"
- except:
- prompt += f"\n<|user|>\n{message['content']}{IM_END_TOKEN}"
- elif message["role"] == "assistant":
- prompt += f"\n<|assistant|>"
- # need to add the function call if there was one
- inner_thoughts = message["content"]
- if "function_call" in message and message["function_call"]:
- prompt += f"\n{create_function_call(message['function_call'], inner_thoughts=inner_thoughts)}"
- elif message["role"] in ["function", "tool"]:
- # TODO find a good way to add this
- # prompt += f"\nASSISTANT: (function return) {message['content']}"
- prompt += f"\nFUNCTION RETURN: {message['content']}"
- continue
- else:
- raise ValueError(message)
-
- # Add a sep for the response
- # if self.include_section_separators:
- # prompt += "\n### RESPONSE"
-
- if self.include_assistant_prefix:
- prompt += f"\n<|assistant|>"
- if self.include_opening_brance_in_prefix:
- prompt += "\n{"
-
- return prompt
-
- def clean_function_args(self, function_name, function_args):
- """Some basic MemGPT-specific cleaning of function args"""
- cleaned_function_name = function_name
- cleaned_function_args = function_args.copy() if function_args is not None else {}
-
- if function_name == "send_message":
- # strip request_heartbeat
- cleaned_function_args.pop("request_heartbeat", None)
-
- inner_thoughts = None
- if "inner_thoughts" in function_args:
- inner_thoughts = cleaned_function_args.pop("inner_thoughts")
-
- # TODO more cleaning to fix errors LLM makes
- return inner_thoughts, cleaned_function_name, cleaned_function_args
-
- def output_to_chat_completion_response(self, raw_llm_output):
- """Turn raw LLM output into a ChatCompletion style response with:
- "message" = {
- "role": "assistant",
- "content": ...,
- "function_call": {
- "name": ...
- "arguments": {
- "arg1": val1,
- ...
- }
- }
- }
- """
- if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
- raw_llm_output = "{" + raw_llm_output
-
- try:
- function_json_output = clean_json(raw_llm_output)
- except Exception as e:
- raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
- try:
- function_name = function_json_output["function"]
- function_parameters = function_json_output["params"]
- except KeyError as e:
- raise LLMJSONParsingError(f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}")
-
- if self.clean_func_args:
- (
- inner_thoughts,
- function_name,
- function_parameters,
- ) = self.clean_function_args(function_name, function_parameters)
-
- message = {
- "role": "assistant",
- "content": inner_thoughts,
- "function_call": {
- "name": function_name,
- "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
- },
- }
- return message
+import json
+
+from ...constants import JSON_ENSURE_ASCII
+from ...errors import LLMJSONParsingError
+from ..json_parser import clean_json
+from .wrapper_base import LLMChatCompletionWrapper
+
+
+class ZephyrMistralWrapper(LLMChatCompletionWrapper):
+ """
+ Wrapper for Zephyr Alpha and Beta, Mistral 7B:
+ https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
+ https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
+ Note: this wrapper formats a prompt that only generates JSON, no inner thoughts
+ """
+
+ def __init__(
+ self,
+ simplify_json_content=True,
+ clean_function_args=True,
+ include_assistant_prefix=True,
+ include_opening_brace_in_prefix=True,
+ include_section_separators=False,
+ ):
+ self.simplify_json_content = simplify_json_content
+ self.clean_func_args = clean_function_args
+ self.include_assistant_prefix = include_assistant_prefix
+ self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
+ self.include_section_separators = include_section_separators
+
+ def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
+ """
+ Zephyr prompt format:
+ <|system|>
+
+ <|user|>
+ {prompt}
+ <|assistant|>
+ (source: https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF#prompt-template-zephyr)
+ """
+
+ prompt = ""
+
+ IM_END_TOKEN = ""
+
+ # System instructions go first
+ assert messages[0]["role"] == "system"
+ prompt += f"<|system|>"
+ prompt += f"\n{messages[0]['content']}"
+
+ # Next is the functions preamble
+ def create_function_description(schema):
+ # airorobos style
+ func_str = ""
+ func_str += f"{schema['name']}:"
+ func_str += f"\n description: {schema['description']}"
+ func_str += f"\n params:"
+ for param_k, param_v in schema["parameters"]["properties"].items():
+ # TODO we're ignoring type
+ func_str += f"\n {param_k}: {param_v['description']}"
+ # TODO we're ignoring schema['parameters']['required']
+ return func_str
+
+ # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
+ prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
+ prompt += f"\nAvailable functions:"
+ if function_documentation is not None:
+ prompt += f"\n{function_documentation}"
+ else:
+ for function_dict in functions:
+ prompt += f"\n{create_function_description(function_dict)}"
+
+ # Put functions INSIDE system message (TODO experiment with this)
+ prompt += IM_END_TOKEN
+
+ def create_function_call(function_call):
+ airo_func_call = {
+ "function": function_call["name"],
+ "params": json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
+ }
+ return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
+
+ for message in messages[1:]:
+ assert message["role"] in ["user", "assistant", "function", "tool"], message
+
+ if message["role"] == "user":
+ if self.simplify_json_content:
+ try:
+ content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
+ content_simple = content_json["message"]
+ prompt += f"\n<|user|>\n{content_simple}{IM_END_TOKEN}"
+ # prompt += f"\nUSER: {content_simple}"
+ except:
+ prompt += f"\n<|user|>\n{message['content']}{IM_END_TOKEN}"
+ # prompt += f"\nUSER: {message['content']}"
+ elif message["role"] == "assistant":
+ prompt += f"\n<|assistant|>"
+ if message["content"] is not None:
+ prompt += f"\n{message['content']}"
+ # prompt += f"\nASSISTANT: {message['content']}"
+ # need to add the function call if there was one
+ if "function_call" in message and message["function_call"]:
+ prompt += f"\n{create_function_call(message['function_call'])}"
+ prompt += f"{IM_END_TOKEN}"
+ elif message["role"] in ["function", "tool"]:
+ # TODO find a good way to add this
+ # prompt += f"\nASSISTANT: (function return) {message['content']}"
+ prompt += f"\n<|assistant|>"
+ prompt += f"\nFUNCTION RETURN: {message['content']}"
+ # prompt += f"\nFUNCTION RETURN: {message['content']}"
+ continue
+ else:
+ raise ValueError(message)
+
+ # Add a sep for the response
+ # if self.include_section_separators:
+ # prompt += "\n### RESPONSE"
+
+ if self.include_assistant_prefix:
+ # prompt += f"\nASSISTANT:"
+ prompt += f"\n<|assistant|>"
+ if self.include_opening_brance_in_prefix:
+ prompt += "\n{"
+
+ return prompt
+
+ def clean_function_args(self, function_name, function_args):
+ """Some basic MemGPT-specific cleaning of function args"""
+ cleaned_function_name = function_name
+ cleaned_function_args = function_args.copy() if function_args is not None else {}
+
+ if function_name == "send_message":
+ # strip request_heartbeat
+ cleaned_function_args.pop("request_heartbeat", None)
+
+ # TODO more cleaning to fix errors LLM makes
+ return cleaned_function_name, cleaned_function_args
+
+ def output_to_chat_completion_response(self, raw_llm_output):
+ """Turn raw LLM output into a ChatCompletion style response with:
+ "message" = {
+ "role": "assistant",
+ "content": ...,
+ "function_call": {
+ "name": ...
+ "arguments": {
+ "arg1": val1,
+ ...
+ }
+ }
+ }
+ """
+ if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
+ raw_llm_output = "{" + raw_llm_output
+
+ try:
+ function_json_output = clean_json(raw_llm_output)
+ except Exception as e:
+ raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
+ try:
+ function_name = function_json_output["function"]
+ function_parameters = function_json_output["params"]
+ except KeyError as e:
+ raise LLMJSONParsingError(f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}")
+
+ if self.clean_func_args:
+ function_name, function_parameters = self.clean_function_args(function_name, function_parameters)
+
+ message = {
+ "role": "assistant",
+ "content": None,
+ "function_call": {
+ "name": function_name,
+ "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
+ },
+ }
+ return message
+
+
+class ZephyrMistralInnerMonologueWrapper(ZephyrMistralWrapper):
+ """Still expect only JSON outputs from model, but add inner monologue as a field"""
+
+ """
+ Wrapper for Zephyr Alpha and Beta, Mistral 7B:
+ https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
+ https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
+ Note: this wrapper formats a prompt with inner thoughts included
+ """
+
+ def __init__(
+ self,
+ simplify_json_content=True,
+ clean_function_args=True,
+ include_assistant_prefix=True,
+ include_opening_brace_in_prefix=True,
+ include_section_separators=True,
+ ):
+ self.simplify_json_content = simplify_json_content
+ self.clean_func_args = clean_function_args
+ self.include_assistant_prefix = include_assistant_prefix
+ self.include_opening_brance_in_prefix = include_opening_brace_in_prefix
+ self.include_section_separators = include_section_separators
+
+ def chat_completion_to_prompt(self, messages, functions, function_documentation=None):
+ prompt = ""
+
+ IM_END_TOKEN = ""
+
+ # System insturctions go first
+ assert messages[0]["role"] == "system"
+ prompt += messages[0]["content"]
+
+ # Next is the functions preamble
+ def create_function_description(schema, add_inner_thoughts=True):
+ # airorobos style
+ func_str = ""
+ func_str += f"{schema['name']}:"
+ func_str += f"\n description: {schema['description']}"
+ func_str += f"\n params:"
+ if add_inner_thoughts:
+ func_str += f"\n inner_thoughts: Deep inner monologue private to you only."
+ for param_k, param_v in schema["parameters"]["properties"].items():
+ # TODO we're ignoring type
+ func_str += f"\n {param_k}: {param_v['description']}"
+ # TODO we're ignoring schema['parameters']['required']
+ return func_str
+
+ # prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format."
+ prompt += f"\nPlease select the most suitable function and parameters from the list of available functions below, based on the ongoing conversation. Provide your response in JSON format."
+ prompt += f"\nAvailable functions:"
+ if function_documentation is not None:
+ prompt += f"\n{function_documentation}"
+ else:
+ for function_dict in functions:
+ prompt += f"\n{create_function_description(function_dict)}"
+
+ def create_function_call(function_call, inner_thoughts=None):
+ airo_func_call = {
+ "function": function_call["name"],
+ "params": {
+ "inner_thoughts": inner_thoughts,
+ **json.loads(function_call["arguments"], strict=JSON_LOADS_STRICT),
+ },
+ }
+ return json.dumps(airo_func_call, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
+
+ # Add a sep for the conversation
+ if self.include_section_separators:
+ prompt += "\n<|user|>"
+
+ # Last are the user/assistant messages
+ for message in messages[1:]:
+ assert message["role"] in ["user", "assistant", "function", "tool"], message
+
+ if message["role"] == "user":
+ if self.simplify_json_content:
+ try:
+ content_json = json.loads(message["content"], strict=JSON_LOADS_STRICT)
+ content_simple = content_json["message"]
+ prompt += f"\n<|user|>\n{content_simple}{IM_END_TOKEN}"
+ except:
+ prompt += f"\n<|user|>\n{message['content']}{IM_END_TOKEN}"
+ elif message["role"] == "assistant":
+ prompt += f"\n<|assistant|>"
+ # need to add the function call if there was one
+ inner_thoughts = message["content"]
+ if "function_call" in message and message["function_call"]:
+ prompt += f"\n{create_function_call(message['function_call'], inner_thoughts=inner_thoughts)}"
+ elif message["role"] in ["function", "tool"]:
+ # TODO find a good way to add this
+ # prompt += f"\nASSISTANT: (function return) {message['content']}"
+ prompt += f"\nFUNCTION RETURN: {message['content']}"
+ continue
+ else:
+ raise ValueError(message)
+
+ # Add a sep for the response
+ # if self.include_section_separators:
+ # prompt += "\n### RESPONSE"
+
+ if self.include_assistant_prefix:
+ prompt += f"\n<|assistant|>"
+ if self.include_opening_brance_in_prefix:
+ prompt += "\n{"
+
+ return prompt
+
+ def clean_function_args(self, function_name, function_args):
+ """Some basic MemGPT-specific cleaning of function args"""
+ cleaned_function_name = function_name
+ cleaned_function_args = function_args.copy() if function_args is not None else {}
+
+ if function_name == "send_message":
+ # strip request_heartbeat
+ cleaned_function_args.pop("request_heartbeat", None)
+
+ inner_thoughts = None
+ if "inner_thoughts" in function_args:
+ inner_thoughts = cleaned_function_args.pop("inner_thoughts")
+
+ # TODO more cleaning to fix errors LLM makes
+ return inner_thoughts, cleaned_function_name, cleaned_function_args
+
+ def output_to_chat_completion_response(self, raw_llm_output):
+ """Turn raw LLM output into a ChatCompletion style response with:
+ "message" = {
+ "role": "assistant",
+ "content": ...,
+ "function_call": {
+ "name": ...
+ "arguments": {
+ "arg1": val1,
+ ...
+ }
+ }
+ }
+ """
+ if self.include_opening_brance_in_prefix and raw_llm_output[0] != "{":
+ raw_llm_output = "{" + raw_llm_output
+
+ try:
+ function_json_output = clean_json(raw_llm_output)
+ except Exception as e:
+ raise Exception(f"Failed to decode JSON from LLM output:\n{raw_llm_output} - error\n{str(e)}")
+ try:
+ function_name = function_json_output["function"]
+ function_parameters = function_json_output["params"]
+ except KeyError as e:
+ raise LLMJSONParsingError(f"Received valid JSON from LLM, but JSON was missing fields: {str(e)}")
+
+ if self.clean_func_args:
+ (
+ inner_thoughts,
+ function_name,
+ function_parameters,
+ ) = self.clean_function_args(function_name, function_parameters)
+
+ message = {
+ "role": "assistant",
+ "content": inner_thoughts,
+ "function_call": {
+ "name": function_name,
+ "arguments": json.dumps(function_parameters, ensure_ascii=JSON_ENSURE_ASCII),
+ },
+ }
+ return message
diff --git a/memgpt/main.py b/memgpt/main.py
index 71bf36ed..56750378 100644
--- a/memgpt/main.py
+++ b/memgpt/main.py
@@ -1,448 +1,448 @@
-import json
-import os
-import sys
-import traceback
-
-import questionary
-import requests
-import typer
-from rich.console import Console
-
-import memgpt.agent as agent
-import memgpt.errors as errors
-import memgpt.system as system
-from memgpt.agent_store.storage import StorageConnector, TableType
-
-# import benchmark
-from memgpt.benchmark.benchmark import bench
-from memgpt.cli.cli import (
- delete_agent,
- migrate,
- open_folder,
- quickstart,
- run,
- server,
- version,
-)
-from memgpt.cli.cli_config import add, configure, delete, list
-from memgpt.cli.cli_load import app as load_app
-from memgpt.config import MemGPTConfig
-from memgpt.constants import (
- FUNC_FAILED_HEARTBEAT_MESSAGE,
- JSON_ENSURE_ASCII,
- JSON_LOADS_STRICT,
- REQ_HEARTBEAT_MESSAGE,
-)
-from memgpt.metadata import MetadataStore
-
-# from memgpt.interface import CLIInterface as interface # for printing to terminal
-from memgpt.streaming_interface import AgentRefreshStreamingInterface
-
-# interface = interface()
-
-app = typer.Typer(pretty_exceptions_enable=False)
-app.command(name="run")(run)
-app.command(name="version")(version)
-app.command(name="configure")(configure)
-app.command(name="list")(list)
-app.command(name="add")(add)
-app.command(name="delete")(delete)
-app.command(name="server")(server)
-app.command(name="folder")(open_folder)
-app.command(name="quickstart")(quickstart)
-# load data commands
-app.add_typer(load_app, name="load")
-# migration command
-app.command(name="migrate")(migrate)
-# benchmark command
-app.command(name="benchmark")(bench)
-# delete agents
-app.command(name="delete-agent")(delete_agent)
-
-
-def clear_line(console, strip_ui=False):
- if strip_ui:
- return
- if os.name == "nt": # for windows
- console.print("\033[A\033[K", end="")
- else: # for linux
- sys.stdout.write("\033[2K\033[G")
- sys.stdout.flush()
-
-
-def run_agent_loop(
- memgpt_agent: agent.Agent, config: MemGPTConfig, first, ms: MetadataStore, no_verify=False, cfg=None, strip_ui=False, stream=False
-):
- if isinstance(memgpt_agent.interface, AgentRefreshStreamingInterface):
- # memgpt_agent.interface.toggle_streaming(on=stream)
- if not stream:
- memgpt_agent.interface = memgpt_agent.interface.nonstreaming_interface
-
- if hasattr(memgpt_agent.interface, "console"):
- console = memgpt_agent.interface.console
- else:
- console = Console()
-
- counter = 0
- user_input = None
- skip_next_user_input = False
- user_message = None
- USER_GOES_FIRST = first
-
- if not USER_GOES_FIRST:
- console.input("[bold cyan]Hit enter to begin (will request first MemGPT message)[/bold cyan]\n")
- clear_line(console, strip_ui=strip_ui)
- print()
-
- multiline_input = False
- ms = MetadataStore(config)
- while True:
- if not skip_next_user_input and (counter > 0 or USER_GOES_FIRST):
- # Ask for user input
- if not stream:
- print()
- user_input = questionary.text(
- "Enter your message:",
- multiline=multiline_input,
- qmark=">",
- ).ask()
- clear_line(console, strip_ui=strip_ui)
- if not stream:
- print()
-
- # Gracefully exit on Ctrl-C/D
- if user_input is None:
- user_input = "/exit"
-
- user_input = user_input.rstrip()
-
- if user_input.startswith("!"):
- print(f"Commands for CLI begin with '/' not '!'")
- continue
-
- if user_input == "":
- # no empty messages allowed
- print("Empty input received. Try again!")
- continue
-
- # Handle CLI commands
- # Commands to not get passed as input to MemGPT
- if user_input.startswith("/"):
- # updated agent save functions
- if user_input.lower() == "/exit":
- # memgpt_agent.save()
- agent.save_agent(memgpt_agent, ms)
- break
- elif user_input.lower() == "/save" or user_input.lower() == "/savechat":
- # memgpt_agent.save()
- agent.save_agent(memgpt_agent, ms)
- continue
- elif user_input.lower() == "/attach":
- # TODO: check if agent already has it
-
- # TODO: check to ensure source embedding dimentions/model match agents, and disallow attachment if not
- # TODO: alternatively, only list sources with compatible embeddings, and print warning about non-compatible sources
-
- data_source_options = ms.list_sources(user_id=memgpt_agent.agent_state.user_id)
- if len(data_source_options) == 0:
- typer.secho(
- 'No sources available. You must load a souce with "memgpt load ..." before running /attach.',
- fg=typer.colors.RED,
- bold=True,
- )
- continue
-
- # determine what sources are valid to be attached to this agent
- valid_options = []
- invalid_options = []
- for source in data_source_options:
- if (
- source.embedding_model == memgpt_agent.agent_state.embedding_config.embedding_model
- and source.embedding_dim == memgpt_agent.agent_state.embedding_config.embedding_dim
- ):
- valid_options.append(source.name)
- else:
- # print warning about invalid sources
- typer.secho(
- f"Source {source.name} exists but has embedding dimentions {source.embedding_dim} from model {source.embedding_model}, while the agent uses embedding dimentions {memgpt_agent.agent_state.embedding_config.embedding_dim} and model {memgpt_agent.agent_state.embedding_config.embedding_model}",
- fg=typer.colors.YELLOW,
- )
- invalid_options.append(source.name)
-
- # prompt user for data source selection
- data_source = questionary.select("Select data source", choices=valid_options).ask()
-
- # attach new data
- # attach(memgpt_agent.agent_state.name, data_source)
- source_connector = StorageConnector.get_storage_connector(
- TableType.PASSAGES, config, user_id=memgpt_agent.agent_state.user_id
- )
- memgpt_agent.attach_source(data_source, source_connector, ms)
-
- continue
-
- elif user_input.lower() == "/dump" or user_input.lower().startswith("/dump "):
- # Check if there's an additional argument that's an integer
- command = user_input.strip().split()
- amount = int(command[1]) if len(command) > 1 and command[1].isdigit() else 0
- if amount == 0:
- memgpt_agent.interface.print_messages(memgpt_agent._messages, dump=True)
- else:
- memgpt_agent.interface.print_messages(memgpt_agent._messages[-min(amount, len(memgpt_agent.messages)) :], dump=True)
- continue
-
- elif user_input.lower() == "/dumpraw":
- memgpt_agent.interface.print_messages_raw(memgpt_agent._messages)
- continue
-
- elif user_input.lower() == "/memory":
- print(f"\nDumping memory contents:\n")
- print(f"{str(memgpt_agent.memory)}")
- print(f"{str(memgpt_agent.persistence_manager.archival_memory)}")
- print(f"{str(memgpt_agent.persistence_manager.recall_memory)}")
- continue
-
- elif user_input.lower() == "/model":
- if memgpt_agent.model == "gpt-4":
- memgpt_agent.model = "gpt-3.5-turbo-16k"
- elif memgpt_agent.model == "gpt-3.5-turbo-16k":
- memgpt_agent.model = "gpt-4"
- print(f"Updated model to:\n{str(memgpt_agent.model)}")
- continue
-
- elif user_input.lower() == "/pop" or user_input.lower().startswith("/pop "):
- # Check if there's an additional argument that's an integer
- command = user_input.strip().split()
- pop_amount = int(command[1]) if len(command) > 1 and command[1].isdigit() else 3
- n_messages = len(memgpt_agent._messages)
- MIN_MESSAGES = 2
- if n_messages <= MIN_MESSAGES:
- print(f"Agent only has {n_messages} messages in stack, none left to pop")
- elif n_messages - pop_amount < MIN_MESSAGES:
- print(f"Agent only has {n_messages} messages in stack, cannot pop more than {n_messages - MIN_MESSAGES}")
- else:
- print(f"Popping last {pop_amount} messages from stack")
- for _ in range(min(pop_amount, len(memgpt_agent._messages))):
- # remove the message from the internal state of the agent
- deleted_message = memgpt_agent._messages.pop()
- # then also remove it from recall storage
- memgpt_agent.persistence_manager.recall_memory.storage.delete(filters={"id": deleted_message.id})
- continue
-
- elif user_input.lower() == "/retry":
- print(f"Retrying for another answer")
- while len(memgpt_agent._messages) > 0:
- if memgpt_agent._messages[-1].role == "user":
- # we want to pop up to the last user message and send it again
- user_message = memgpt_agent._messages[-1].text
- deleted_message = memgpt_agent._messages.pop()
- # then also remove it from recall storage
- memgpt_agent.persistence_manager.recall_memory.storage.delete(filters={"id": deleted_message.id})
- break
- deleted_message = memgpt_agent._messages.pop()
- # then also remove it from recall storage
- memgpt_agent.persistence_manager.recall_memory.storage.delete(filters={"id": deleted_message.id})
-
- elif user_input.lower() == "/rethink" or user_input.lower().startswith("/rethink "):
- if len(user_input) < len("/rethink "):
- print("Missing text after the command")
- continue
- for x in range(len(memgpt_agent.messages) - 1, 0, -1):
- msg_obj = memgpt_agent._messages[x]
- if msg_obj.role == "assistant":
- clean_new_text = user_input[len("/rethink ") :].strip()
- msg_obj.text = clean_new_text
- # To persist to the database, all we need to do is "re-insert" into recall memory
- memgpt_agent.persistence_manager.recall_memory.storage.update(record=msg_obj)
- break
- continue
-
- elif user_input.lower() == "/rewrite" or user_input.lower().startswith("/rewrite "):
- if len(user_input) < len("/rewrite "):
- print("Missing text after the command")
- continue
- for x in range(len(memgpt_agent.messages) - 1, 0, -1):
- if memgpt_agent.messages[x].get("role") == "assistant":
- text = user_input[len("/rewrite ") :].strip()
- # Get the current message content
- # The rewrite target is the output of send_message
- message_obj = memgpt_agent._messages[x]
- if message_obj.tool_calls is not None and len(message_obj.tool_calls) > 0:
- # Check that we hit an assistant send_message call
- name_string = message_obj.tool_calls[0].function.get("name")
- if name_string is None or name_string != "send_message":
- print("Assistant missing send_message function call")
- break # cancel op
- args_string = message_obj.tool_calls[0].function.get("arguments")
- if args_string is None:
- print("Assistant missing send_message function arguments")
- break # cancel op
- args_json = json.loads(args_string, strict=JSON_LOADS_STRICT)
- if "message" not in args_json:
- print("Assistant missing send_message message argument")
- break # cancel op
-
- # Once we found our target, rewrite it
- args_json["message"] = text
- new_args_string = json.dumps(args_json, ensure_ascii=JSON_ENSURE_ASCII)
- message_obj.tool_calls[0].function["arguments"] = new_args_string
-
- # To persist to the database, all we need to do is "re-insert" into recall memory
- memgpt_agent.persistence_manager.recall_memory.storage.update(record=message_obj)
- break
- continue
-
- elif user_input.lower() == "/summarize":
- try:
- memgpt_agent.summarize_messages_inplace()
- typer.secho(
- f"/summarize succeeded",
- fg=typer.colors.GREEN,
- bold=True,
- )
- except (errors.LLMError, requests.exceptions.HTTPError) as e:
- typer.secho(
- f"/summarize failed:\n{e}",
- fg=typer.colors.RED,
- bold=True,
- )
- continue
-
- elif user_input.lower().startswith("/add_function"):
- try:
- if len(user_input) < len("/add_function "):
- print("Missing function name after the command")
- continue
- function_name = user_input[len("/add_function ") :].strip()
- result = memgpt_agent.add_function(function_name)
- typer.secho(
- f"/add_function succeeded: {result}",
- fg=typer.colors.GREEN,
- bold=True,
- )
- except ValueError as e:
- typer.secho(
- f"/add_function failed:\n{e}",
- fg=typer.colors.RED,
- bold=True,
- )
- continue
- elif user_input.lower().startswith("/remove_function"):
- try:
- if len(user_input) < len("/remove_function "):
- print("Missing function name after the command")
- continue
- function_name = user_input[len("/remove_function ") :].strip()
- result = memgpt_agent.remove_function(function_name)
- typer.secho(
- f"/remove_function succeeded: {result}",
- fg=typer.colors.GREEN,
- bold=True,
- )
- except ValueError as e:
- typer.secho(
- f"/remove_function failed:\n{e}",
- fg=typer.colors.RED,
- bold=True,
- )
- continue
-
- # No skip options
- elif user_input.lower() == "/wipe":
- memgpt_agent = agent.Agent(memgpt_agent.interface)
- user_message = None
-
- elif user_input.lower() == "/heartbeat":
- user_message = system.get_heartbeat()
-
- elif user_input.lower() == "/memorywarning":
- user_message = system.get_token_limit_warning()
-
- elif user_input.lower() == "//":
- multiline_input = not multiline_input
- continue
-
- elif user_input.lower() == "/" or user_input.lower() == "/help":
- questionary.print("CLI commands", "bold")
- for cmd, desc in USER_COMMANDS:
- questionary.print(cmd, "bold")
- questionary.print(f" {desc}")
- continue
-
- else:
- print(f"Unrecognized command: {user_input}")
- continue
-
- else:
- # If message did not begin with command prefix, pass inputs to MemGPT
- # Handle user message and append to messages
- user_message = system.package_user_message(user_input)
-
- skip_next_user_input = False
-
- def process_agent_step(user_message, no_verify):
- new_messages, heartbeat_request, function_failed, token_warning, tokens_accumulated = memgpt_agent.step(
- user_message,
- first_message=False,
- skip_verify=no_verify,
- stream=stream,
- )
-
- skip_next_user_input = False
- if token_warning:
- user_message = system.get_token_limit_warning()
- skip_next_user_input = True
- elif function_failed:
- user_message = system.get_heartbeat(FUNC_FAILED_HEARTBEAT_MESSAGE)
- skip_next_user_input = True
- elif heartbeat_request:
- user_message = system.get_heartbeat(REQ_HEARTBEAT_MESSAGE)
- skip_next_user_input = True
-
- return new_messages, user_message, skip_next_user_input
-
- while True:
- try:
- if strip_ui:
- new_messages, user_message, skip_next_user_input = process_agent_step(user_message, no_verify)
- break
- else:
- if stream:
- # Don't display the "Thinking..." if streaming
- new_messages, user_message, skip_next_user_input = process_agent_step(user_message, no_verify)
- else:
- with console.status("[bold cyan]Thinking...") as status:
- new_messages, user_message, skip_next_user_input = process_agent_step(user_message, no_verify)
- break
- except KeyboardInterrupt:
- print("User interrupt occurred.")
- retry = questionary.confirm("Retry agent.step()?").ask()
- if not retry:
- break
- except Exception as e:
- print("An exception occurred when running agent.step(): ")
- traceback.print_exc()
- retry = questionary.confirm("Retry agent.step()?").ask()
- if not retry:
- break
-
- counter += 1
-
- print("Finished.")
-
-
-USER_COMMANDS = [
- ("//", "toggle multiline input mode"),
- ("/exit", "exit the CLI"),
- ("/save", "save a checkpoint of the current agent/conversation state"),
- ("/load", "load a saved checkpoint"),
- ("/dump ", "view the last messages (all if is omitted)"),
- ("/memory", "print the current contents of agent memory"),
- ("/pop ", "undo messages in the conversation (default is 3)"),
- ("/retry", "pops the last answer and tries to get another one"),
- ("/rethink ", "changes the inner thoughts of the last agent message"),
- ("/rewrite ", "changes the reply of the last agent message"),
- ("/heartbeat", "send a heartbeat system message to the agent"),
- ("/memorywarning", "send a memory warning system message to the agent"),
- ("/attach", "attach data source to agent"),
-]
+import json
+import os
+import sys
+import traceback
+
+import questionary
+import requests
+import typer
+from rich.console import Console
+
+import memgpt.agent as agent
+import memgpt.errors as errors
+import memgpt.system as system
+from memgpt.agent_store.storage import StorageConnector, TableType
+
+# import benchmark
+from memgpt.benchmark.benchmark import bench
+from memgpt.cli.cli import (
+ delete_agent,
+ migrate,
+ open_folder,
+ quickstart,
+ run,
+ server,
+ version,
+)
+from memgpt.cli.cli_config import add, configure, delete, list
+from memgpt.cli.cli_load import app as load_app
+from memgpt.config import MemGPTConfig
+from memgpt.constants import (
+ FUNC_FAILED_HEARTBEAT_MESSAGE,
+ JSON_ENSURE_ASCII,
+ JSON_LOADS_STRICT,
+ REQ_HEARTBEAT_MESSAGE,
+)
+from memgpt.metadata import MetadataStore
+
+# from memgpt.interface import CLIInterface as interface # for printing to terminal
+from memgpt.streaming_interface import AgentRefreshStreamingInterface
+
+# interface = interface()
+
+app = typer.Typer(pretty_exceptions_enable=False)
+app.command(name="run")(run)
+app.command(name="version")(version)
+app.command(name="configure")(configure)
+app.command(name="list")(list)
+app.command(name="add")(add)
+app.command(name="delete")(delete)
+app.command(name="server")(server)
+app.command(name="folder")(open_folder)
+app.command(name="quickstart")(quickstart)
+# load data commands
+app.add_typer(load_app, name="load")
+# migration command
+app.command(name="migrate")(migrate)
+# benchmark command
+app.command(name="benchmark")(bench)
+# delete agents
+app.command(name="delete-agent")(delete_agent)
+
+
+def clear_line(console, strip_ui=False):
+ if strip_ui:
+ return
+ if os.name == "nt": # for windows
+ console.print("\033[A\033[K", end="")
+ else: # for linux
+ sys.stdout.write("\033[2K\033[G")
+ sys.stdout.flush()
+
+
+def run_agent_loop(
+ memgpt_agent: agent.Agent, config: MemGPTConfig, first, ms: MetadataStore, no_verify=False, cfg=None, strip_ui=False, stream=False
+):
+ if isinstance(memgpt_agent.interface, AgentRefreshStreamingInterface):
+ # memgpt_agent.interface.toggle_streaming(on=stream)
+ if not stream:
+ memgpt_agent.interface = memgpt_agent.interface.nonstreaming_interface
+
+ if hasattr(memgpt_agent.interface, "console"):
+ console = memgpt_agent.interface.console
+ else:
+ console = Console()
+
+ counter = 0
+ user_input = None
+ skip_next_user_input = False
+ user_message = None
+ USER_GOES_FIRST = first
+
+ if not USER_GOES_FIRST:
+ console.input("[bold cyan]Hit enter to begin (will request first MemGPT message)[/bold cyan]\n")
+ clear_line(console, strip_ui=strip_ui)
+ print()
+
+ multiline_input = False
+ ms = MetadataStore(config)
+ while True:
+ if not skip_next_user_input and (counter > 0 or USER_GOES_FIRST):
+ # Ask for user input
+ if not stream:
+ print()
+ user_input = questionary.text(
+ "Enter your message:",
+ multiline=multiline_input,
+ qmark=">",
+ ).ask()
+ clear_line(console, strip_ui=strip_ui)
+ if not stream:
+ print()
+
+ # Gracefully exit on Ctrl-C/D
+ if user_input is None:
+ user_input = "/exit"
+
+ user_input = user_input.rstrip()
+
+ if user_input.startswith("!"):
+ print(f"Commands for CLI begin with '/' not '!'")
+ continue
+
+ if user_input == "":
+ # no empty messages allowed
+ print("Empty input received. Try again!")
+ continue
+
+ # Handle CLI commands
+ # Commands to not get passed as input to MemGPT
+ if user_input.startswith("/"):
+ # updated agent save functions
+ if user_input.lower() == "/exit":
+ # memgpt_agent.save()
+ agent.save_agent(memgpt_agent, ms)
+ break
+ elif user_input.lower() == "/save" or user_input.lower() == "/savechat":
+ # memgpt_agent.save()
+ agent.save_agent(memgpt_agent, ms)
+ continue
+ elif user_input.lower() == "/attach":
+ # TODO: check if agent already has it
+
+ # TODO: check to ensure source embedding dimentions/model match agents, and disallow attachment if not
+ # TODO: alternatively, only list sources with compatible embeddings, and print warning about non-compatible sources
+
+ data_source_options = ms.list_sources(user_id=memgpt_agent.agent_state.user_id)
+ if len(data_source_options) == 0:
+ typer.secho(
+ 'No sources available. You must load a souce with "memgpt load ..." before running /attach.',
+ fg=typer.colors.RED,
+ bold=True,
+ )
+ continue
+
+ # determine what sources are valid to be attached to this agent
+ valid_options = []
+ invalid_options = []
+ for source in data_source_options:
+ if (
+ source.embedding_model == memgpt_agent.agent_state.embedding_config.embedding_model
+ and source.embedding_dim == memgpt_agent.agent_state.embedding_config.embedding_dim
+ ):
+ valid_options.append(source.name)
+ else:
+ # print warning about invalid sources
+ typer.secho(
+ f"Source {source.name} exists but has embedding dimentions {source.embedding_dim} from model {source.embedding_model}, while the agent uses embedding dimentions {memgpt_agent.agent_state.embedding_config.embedding_dim} and model {memgpt_agent.agent_state.embedding_config.embedding_model}",
+ fg=typer.colors.YELLOW,
+ )
+ invalid_options.append(source.name)
+
+ # prompt user for data source selection
+ data_source = questionary.select("Select data source", choices=valid_options).ask()
+
+ # attach new data
+ # attach(memgpt_agent.agent_state.name, data_source)
+ source_connector = StorageConnector.get_storage_connector(
+ TableType.PASSAGES, config, user_id=memgpt_agent.agent_state.user_id
+ )
+ memgpt_agent.attach_source(data_source, source_connector, ms)
+
+ continue
+
+ elif user_input.lower() == "/dump" or user_input.lower().startswith("/dump "):
+ # Check if there's an additional argument that's an integer
+ command = user_input.strip().split()
+ amount = int(command[1]) if len(command) > 1 and command[1].isdigit() else 0
+ if amount == 0:
+ memgpt_agent.interface.print_messages(memgpt_agent._messages, dump=True)
+ else:
+ memgpt_agent.interface.print_messages(memgpt_agent._messages[-min(amount, len(memgpt_agent.messages)) :], dump=True)
+ continue
+
+ elif user_input.lower() == "/dumpraw":
+ memgpt_agent.interface.print_messages_raw(memgpt_agent._messages)
+ continue
+
+ elif user_input.lower() == "/memory":
+ print(f"\nDumping memory contents:\n")
+ print(f"{str(memgpt_agent.memory)}")
+ print(f"{str(memgpt_agent.persistence_manager.archival_memory)}")
+ print(f"{str(memgpt_agent.persistence_manager.recall_memory)}")
+ continue
+
+ elif user_input.lower() == "/model":
+ if memgpt_agent.model == "gpt-4":
+ memgpt_agent.model = "gpt-3.5-turbo-16k"
+ elif memgpt_agent.model == "gpt-3.5-turbo-16k":
+ memgpt_agent.model = "gpt-4"
+ print(f"Updated model to:\n{str(memgpt_agent.model)}")
+ continue
+
+ elif user_input.lower() == "/pop" or user_input.lower().startswith("/pop "):
+ # Check if there's an additional argument that's an integer
+ command = user_input.strip().split()
+ pop_amount = int(command[1]) if len(command) > 1 and command[1].isdigit() else 3
+ n_messages = len(memgpt_agent._messages)
+ MIN_MESSAGES = 2
+ if n_messages <= MIN_MESSAGES:
+ print(f"Agent only has {n_messages} messages in stack, none left to pop")
+ elif n_messages - pop_amount < MIN_MESSAGES:
+ print(f"Agent only has {n_messages} messages in stack, cannot pop more than {n_messages - MIN_MESSAGES}")
+ else:
+ print(f"Popping last {pop_amount} messages from stack")
+ for _ in range(min(pop_amount, len(memgpt_agent._messages))):
+ # remove the message from the internal state of the agent
+ deleted_message = memgpt_agent._messages.pop()
+ # then also remove it from recall storage
+ memgpt_agent.persistence_manager.recall_memory.storage.delete(filters={"id": deleted_message.id})
+ continue
+
+ elif user_input.lower() == "/retry":
+ print(f"Retrying for another answer")
+ while len(memgpt_agent._messages) > 0:
+ if memgpt_agent._messages[-1].role == "user":
+ # we want to pop up to the last user message and send it again
+ user_message = memgpt_agent._messages[-1].text
+ deleted_message = memgpt_agent._messages.pop()
+ # then also remove it from recall storage
+ memgpt_agent.persistence_manager.recall_memory.storage.delete(filters={"id": deleted_message.id})
+ break
+ deleted_message = memgpt_agent._messages.pop()
+ # then also remove it from recall storage
+ memgpt_agent.persistence_manager.recall_memory.storage.delete(filters={"id": deleted_message.id})
+
+ elif user_input.lower() == "/rethink" or user_input.lower().startswith("/rethink "):
+ if len(user_input) < len("/rethink "):
+ print("Missing text after the command")
+ continue
+ for x in range(len(memgpt_agent.messages) - 1, 0, -1):
+ msg_obj = memgpt_agent._messages[x]
+ if msg_obj.role == "assistant":
+ clean_new_text = user_input[len("/rethink ") :].strip()
+ msg_obj.text = clean_new_text
+ # To persist to the database, all we need to do is "re-insert" into recall memory
+ memgpt_agent.persistence_manager.recall_memory.storage.update(record=msg_obj)
+ break
+ continue
+
+ elif user_input.lower() == "/rewrite" or user_input.lower().startswith("/rewrite "):
+ if len(user_input) < len("/rewrite "):
+ print("Missing text after the command")
+ continue
+ for x in range(len(memgpt_agent.messages) - 1, 0, -1):
+ if memgpt_agent.messages[x].get("role") == "assistant":
+ text = user_input[len("/rewrite ") :].strip()
+ # Get the current message content
+ # The rewrite target is the output of send_message
+ message_obj = memgpt_agent._messages[x]
+ if message_obj.tool_calls is not None and len(message_obj.tool_calls) > 0:
+ # Check that we hit an assistant send_message call
+ name_string = message_obj.tool_calls[0].function.get("name")
+ if name_string is None or name_string != "send_message":
+ print("Assistant missing send_message function call")
+ break # cancel op
+ args_string = message_obj.tool_calls[0].function.get("arguments")
+ if args_string is None:
+ print("Assistant missing send_message function arguments")
+ break # cancel op
+ args_json = json.loads(args_string, strict=JSON_LOADS_STRICT)
+ if "message" not in args_json:
+ print("Assistant missing send_message message argument")
+ break # cancel op
+
+ # Once we found our target, rewrite it
+ args_json["message"] = text
+ new_args_string = json.dumps(args_json, ensure_ascii=JSON_ENSURE_ASCII)
+ message_obj.tool_calls[0].function["arguments"] = new_args_string
+
+ # To persist to the database, all we need to do is "re-insert" into recall memory
+ memgpt_agent.persistence_manager.recall_memory.storage.update(record=message_obj)
+ break
+ continue
+
+ elif user_input.lower() == "/summarize":
+ try:
+ memgpt_agent.summarize_messages_inplace()
+ typer.secho(
+ f"/summarize succeeded",
+ fg=typer.colors.GREEN,
+ bold=True,
+ )
+ except (errors.LLMError, requests.exceptions.HTTPError) as e:
+ typer.secho(
+ f"/summarize failed:\n{e}",
+ fg=typer.colors.RED,
+ bold=True,
+ )
+ continue
+
+ elif user_input.lower().startswith("/add_function"):
+ try:
+ if len(user_input) < len("/add_function "):
+ print("Missing function name after the command")
+ continue
+ function_name = user_input[len("/add_function ") :].strip()
+ result = memgpt_agent.add_function(function_name)
+ typer.secho(
+ f"/add_function succeeded: {result}",
+ fg=typer.colors.GREEN,
+ bold=True,
+ )
+ except ValueError as e:
+ typer.secho(
+ f"/add_function failed:\n{e}",
+ fg=typer.colors.RED,
+ bold=True,
+ )
+ continue
+ elif user_input.lower().startswith("/remove_function"):
+ try:
+ if len(user_input) < len("/remove_function "):
+ print("Missing function name after the command")
+ continue
+ function_name = user_input[len("/remove_function ") :].strip()
+ result = memgpt_agent.remove_function(function_name)
+ typer.secho(
+ f"/remove_function succeeded: {result}",
+ fg=typer.colors.GREEN,
+ bold=True,
+ )
+ except ValueError as e:
+ typer.secho(
+ f"/remove_function failed:\n{e}",
+ fg=typer.colors.RED,
+ bold=True,
+ )
+ continue
+
+ # No skip options
+ elif user_input.lower() == "/wipe":
+ memgpt_agent = agent.Agent(memgpt_agent.interface)
+ user_message = None
+
+ elif user_input.lower() == "/heartbeat":
+ user_message = system.get_heartbeat()
+
+ elif user_input.lower() == "/memorywarning":
+ user_message = system.get_token_limit_warning()
+
+ elif user_input.lower() == "//":
+ multiline_input = not multiline_input
+ continue
+
+ elif user_input.lower() == "/" or user_input.lower() == "/help":
+ questionary.print("CLI commands", "bold")
+ for cmd, desc in USER_COMMANDS:
+ questionary.print(cmd, "bold")
+ questionary.print(f" {desc}")
+ continue
+
+ else:
+ print(f"Unrecognized command: {user_input}")
+ continue
+
+ else:
+ # If message did not begin with command prefix, pass inputs to MemGPT
+ # Handle user message and append to messages
+ user_message = system.package_user_message(user_input)
+
+ skip_next_user_input = False
+
+ def process_agent_step(user_message, no_verify):
+ new_messages, heartbeat_request, function_failed, token_warning, tokens_accumulated = memgpt_agent.step(
+ user_message,
+ first_message=False,
+ skip_verify=no_verify,
+ stream=stream,
+ )
+
+ skip_next_user_input = False
+ if token_warning:
+ user_message = system.get_token_limit_warning()
+ skip_next_user_input = True
+ elif function_failed:
+ user_message = system.get_heartbeat(FUNC_FAILED_HEARTBEAT_MESSAGE)
+ skip_next_user_input = True
+ elif heartbeat_request:
+ user_message = system.get_heartbeat(REQ_HEARTBEAT_MESSAGE)
+ skip_next_user_input = True
+
+ return new_messages, user_message, skip_next_user_input
+
+ while True:
+ try:
+ if strip_ui:
+ new_messages, user_message, skip_next_user_input = process_agent_step(user_message, no_verify)
+ break
+ else:
+ if stream:
+ # Don't display the "Thinking..." if streaming
+ new_messages, user_message, skip_next_user_input = process_agent_step(user_message, no_verify)
+ else:
+ with console.status("[bold cyan]Thinking...") as status:
+ new_messages, user_message, skip_next_user_input = process_agent_step(user_message, no_verify)
+ break
+ except KeyboardInterrupt:
+ print("User interrupt occurred.")
+ retry = questionary.confirm("Retry agent.step()?").ask()
+ if not retry:
+ break
+ except Exception as e:
+ print("An exception occurred when running agent.step(): ")
+ traceback.print_exc()
+ retry = questionary.confirm("Retry agent.step()?").ask()
+ if not retry:
+ break
+
+ counter += 1
+
+ print("Finished.")
+
+
+USER_COMMANDS = [
+ ("//", "toggle multiline input mode"),
+ ("/exit", "exit the CLI"),
+ ("/save", "save a checkpoint of the current agent/conversation state"),
+ ("/load", "load a saved checkpoint"),
+ ("/dump ", "view the last messages (all if is omitted)"),
+ ("/memory", "print the current contents of agent memory"),
+ ("/pop ", "undo messages in the conversation (default is 3)"),
+ ("/retry", "pops the last answer and tries to get another one"),
+ ("/rethink ", "changes the inner thoughts of the last agent message"),
+ ("/rewrite ", "changes the reply of the last agent message"),
+ ("/heartbeat", "send a heartbeat system message to the agent"),
+ ("/memorywarning", "send a memory warning system message to the agent"),
+ ("/attach", "attach data source to agent"),
+]
diff --git a/memgpt/memory.py b/memgpt/memory.py
index f405ebd4..cc832edd 100644
--- a/memgpt/memory.py
+++ b/memgpt/memory.py
@@ -1,598 +1,598 @@
-import datetime
-import uuid
-from abc import ABC, abstractmethod
-from typing import List, Optional, Tuple, Union
-
-from pydantic import BaseModel, validator
-
-from memgpt.constants import MESSAGE_SUMMARY_REQUEST_ACK, MESSAGE_SUMMARY_WARNING_FRAC
-from memgpt.data_types import AgentState, Message, Passage
-from memgpt.embeddings import embedding_model, parse_and_chunk_text, query_embedding
-from memgpt.llm_api.llm_api_tools import create
-from memgpt.prompts.gpt_summarize import SYSTEM as SUMMARY_PROMPT_SYSTEM
-from memgpt.utils import (
- count_tokens,
- extract_date_from_timestamp,
- get_local_time,
- printd,
- validate_date_format,
-)
-
-
-class MemoryModule(BaseModel):
- """Base class for memory modules"""
-
- description: Optional[str] = None
- limit: int = 2000
- value: Optional[Union[List[str], str]] = None
-
- def __setattr__(self, name, value):
- """Run validation if self.value is updated"""
- super().__setattr__(name, value)
- if name == "value":
- # run validation
- self.__class__.validate(self.dict(exclude_unset=True))
-
- @validator("value", always=True)
- def check_value_length(cls, v, values):
- if v is not None:
- # Fetching the limit from the values dictionary
- limit = values.get("limit", 2000) # Default to 2000 if limit is not yet set
-
- # Check if the value exceeds the limit
- if isinstance(v, str):
- length = len(v)
- elif isinstance(v, list):
- length = sum(len(item) for item in v)
- else:
- raise ValueError("Value must be either a string or a list of strings.")
-
- if length > limit:
- error_msg = f"Edit failed: Exceeds {limit} character limit (requested {length})."
- # TODO: add archival memory error?
- raise ValueError(error_msg)
- return v
-
- def __len__(self):
- return len(str(self))
-
- def __str__(self) -> str:
- if isinstance(self.value, list):
- return ",".join(self.value)
- elif isinstance(self.value, str):
- return self.value
- else:
- return ""
-
-
-class BaseMemory:
-
- def __init__(self):
- self.memory = {}
-
- @classmethod
- def load(cls, state: dict):
- """Load memory from dictionary object"""
- obj = cls()
- for key, value in state.items():
- obj.memory[key] = MemoryModule(**value)
- return obj
-
- def __str__(self) -> str:
- """Representation of the memory in-context"""
- section_strs = []
- for section, module in self.memory.items():
- section_strs.append(f'<{section} characters="{len(module)}/{module.limit}">\n{module.value}\n')
- return "\n".join(section_strs)
-
- def to_dict(self):
- """Convert to dictionary representation"""
- return {key: value.dict() for key, value in self.memory.items()}
-
-
-class ChatMemory(BaseMemory):
-
- def __init__(self, persona: str, human: str, limit: int = 2000):
- self.memory = {
- "persona": MemoryModule(name="persona", value=persona, limit=limit),
- "human": MemoryModule(name="human", value=human, limit=limit),
- }
-
- def core_memory_append(self, name: str, content: str) -> Optional[str]:
- """
- Append to the contents of core memory.
-
- Args:
- name (str): Section of the memory to be edited (persona or human).
- content (str): Content to write to the memory. All unicode (including emojis) are supported.
-
- Returns:
- Optional[str]: None is always returned as this function does not produce a response.
- """
- self.memory[name].value += "\n" + content
- return None
-
- def core_memory_replace(self, name: str, old_content: str, new_content: str) -> Optional[str]:
- """
- Replace the contents of core memory. To delete memories, use an empty string for new_content.
-
- Args:
- name (str): Section of the memory to be edited (persona or human).
- old_content (str): String to replace. Must be an exact match.
- new_content (str): Content to write to the memory. All unicode (including emojis) are supported.
-
- Returns:
- Optional[str]: None is always returned as this function does not produce a response.
- """
- self.memory[name].value = self.memory[name].value.replace(old_content, new_content)
- return None
-
-
-def get_memory_functions(cls: BaseMemory) -> List[callable]:
- """Get memory functions for a memory class"""
- functions = {}
- for func_name in dir(cls):
- if func_name.startswith("_") or func_name in ["load", "to_dict"]: # skip base functions
- continue
- func = getattr(cls, func_name)
- if callable(func):
- functions[func_name] = func
- return functions
-
-
-# class CoreMemory(object):
-# """Held in-context inside the system message
-#
-# Core Memory: Refers to the system block, which provides essential, foundational context to the AI.
-# This includes the persona information, essential user details,
-# and any other baseline data you deem necessary for the AI's basic functioning.
-# """
-#
-# def __init__(self, persona=None, human=None, persona_char_limit=None, human_char_limit=None, archival_memory_exists=True):
-# self.persona = persona
-# self.human = human
-# self.persona_char_limit = persona_char_limit
-# self.human_char_limit = human_char_limit
-#
-# # affects the error message the AI will see on overflow inserts
-# self.archival_memory_exists = archival_memory_exists
-#
-# def __repr__(self) -> str:
-# return f"\n### CORE MEMORY ###" + f"\n=== Persona ===\n{self.persona}" + f"\n\n=== Human ===\n{self.human}"
-#
-# def to_dict(self):
-# return {
-# "persona": self.persona,
-# "human": self.human,
-# }
-#
-# @classmethod
-# def load(cls, state):
-# return cls(state["persona"], state["human"])
-#
-# def edit_persona(self, new_persona):
-# if self.persona_char_limit and len(new_persona) > self.persona_char_limit:
-# error_msg = f"Edit failed: Exceeds {self.persona_char_limit} character limit (requested {len(new_persona)})."
-# if self.archival_memory_exists:
-# error_msg = f"{error_msg} Consider summarizing existing core memories in 'persona' and/or moving lower priority content to archival memory to free up space in core memory, then trying again."
-# raise ValueError(error_msg)
-#
-# self.persona = new_persona
-# return len(self.persona)
-#
-# def edit_human(self, new_human):
-# if self.human_char_limit and len(new_human) > self.human_char_limit:
-# error_msg = f"Edit failed: Exceeds {self.human_char_limit} character limit (requested {len(new_human)})."
-# if self.archival_memory_exists:
-# error_msg = f"{error_msg} Consider summarizing existing core memories in 'human' and/or moving lower priority content to archival memory to free up space in core memory, then trying again."
-# raise ValueError(error_msg)
-#
-# self.human = new_human
-# return len(self.human)
-#
-# def edit(self, field, content):
-# if field == "persona":
-# return self.edit_persona(content)
-# elif field == "human":
-# return self.edit_human(content)
-# else:
-# raise KeyError(f'No memory section named {field} (must be either "persona" or "human")')
-#
-# def edit_append(self, field, content, sep="\n"):
-# if field == "persona":
-# new_content = self.persona + sep + content
-# return self.edit_persona(new_content)
-# elif field == "human":
-# new_content = self.human + sep + content
-# return self.edit_human(new_content)
-# else:
-# raise KeyError(f'No memory section named {field} (must be either "persona" or "human")')
-#
-# def edit_replace(self, field, old_content, new_content):
-# if len(old_content) == 0:
-# raise ValueError("old_content cannot be an empty string (must specify old_content to replace)")
-#
-# if field == "persona":
-# if old_content in self.persona:
-# new_persona = self.persona.replace(old_content, new_content)
-# return self.edit_persona(new_persona)
-# else:
-# raise ValueError("Content not found in persona (make sure to use exact string)")
-# elif field == "human":
-# if old_content in self.human:
-# new_human = self.human.replace(old_content, new_content)
-# return self.edit_human(new_human)
-# else:
-# raise ValueError("Content not found in human (make sure to use exact string)")
-# else:
-# raise KeyError(f'No memory section named {field} (must be either "persona" or "human")')
-
-
-def _format_summary_history(message_history: List[Message]):
- # TODO use existing prompt formatters for this (eg ChatML)
- return "\n".join([f"{m.role}: {m.text}" for m in message_history])
-
-
-def summarize_messages(
- agent_state: AgentState,
- message_sequence_to_summarize: List[Message],
- insert_acknowledgement_assistant_message: bool = True,
-):
- """Summarize a message sequence using GPT"""
- # we need the context_window
- context_window = agent_state.llm_config.context_window
-
- summary_prompt = SUMMARY_PROMPT_SYSTEM
- summary_input = _format_summary_history(message_sequence_to_summarize)
- summary_input_tkns = count_tokens(summary_input)
- if summary_input_tkns > MESSAGE_SUMMARY_WARNING_FRAC * context_window:
- trunc_ratio = (MESSAGE_SUMMARY_WARNING_FRAC * context_window / summary_input_tkns) * 0.8 # For good measure...
- cutoff = int(len(message_sequence_to_summarize) * trunc_ratio)
- summary_input = str(
- [summarize_messages(agent_state, message_sequence_to_summarize=message_sequence_to_summarize[:cutoff])]
- + message_sequence_to_summarize[cutoff:]
- )
-
- dummy_user_id = uuid.uuid4()
- dummy_agent_id = uuid.uuid4()
- message_sequence = []
- message_sequence.append(Message(user_id=dummy_user_id, agent_id=dummy_agent_id, role="system", text=summary_prompt))
- if insert_acknowledgement_assistant_message:
- message_sequence.append(Message(user_id=dummy_user_id, agent_id=dummy_agent_id, role="assistant", text=MESSAGE_SUMMARY_REQUEST_ACK))
- message_sequence.append(Message(user_id=dummy_user_id, agent_id=dummy_agent_id, role="user", text=summary_input))
-
- response = create(
- llm_config=agent_state.llm_config,
- user_id=agent_state.user_id,
- messages=message_sequence,
- )
-
- printd(f"summarize_messages gpt reply: {response.choices[0]}")
- reply = response.choices[0].message.content
- return reply
-
-
-class ArchivalMemory(ABC):
- @abstractmethod
- def insert(self, memory_string: str):
- """Insert new archival memory
-
- :param memory_string: Memory string to insert
- :type memory_string: str
- """
-
- @abstractmethod
- def search(self, query_string, count=None, start=None) -> Tuple[List[str], int]:
- """Search archival memory
-
- :param query_string: Query string
- :type query_string: str
- :param count: Number of results to return (None for all)
- :type count: Optional[int]
- :param start: Offset to start returning results from (None if 0)
- :type start: Optional[int]
-
- :return: Tuple of (list of results, total number of results)
- """
-
- @abstractmethod
- def __repr__(self) -> str:
- pass
-
-
-class RecallMemory(ABC):
- @abstractmethod
- def text_search(self, query_string, count=None, start=None):
- """Search messages that match query_string in recall memory"""
-
- @abstractmethod
- def date_search(self, start_date, end_date, count=None, start=None):
- """Search messages between start_date and end_date in recall memory"""
-
- @abstractmethod
- def __repr__(self) -> str:
- pass
-
- @abstractmethod
- def insert(self, message: Message):
- """Insert message into recall memory"""
-
-
-class DummyRecallMemory(RecallMemory):
- """Dummy in-memory version of a recall memory database (eg run on MongoDB)
-
- Recall memory here is basically just a full conversation history with the user.
- Queryable via string matching, or date matching.
-
- Recall Memory: The AI's capability to search through past interactions,
- effectively allowing it to 'remember' prior engagements with a user.
- """
-
- def __init__(self, message_database=None, restrict_search_to_summaries=False):
- self._message_logs = [] if message_database is None else message_database # consists of full message dicts
-
- # If true, the pool of messages that can be queried are the automated summaries only
- # (generated when the conversation window needs to be shortened)
- self.restrict_search_to_summaries = restrict_search_to_summaries
-
- def __len__(self):
- return len(self._message_logs)
-
- def __repr__(self) -> str:
- # don't dump all the conversations, just statistics
- system_count = user_count = assistant_count = function_count = other_count = 0
- for msg in self._message_logs:
- role = msg["message"]["role"]
- if role == "system":
- system_count += 1
- elif role == "user":
- user_count += 1
- elif role == "assistant":
- assistant_count += 1
- elif role == "function":
- function_count += 1
- else:
- other_count += 1
- memory_str = (
- f"Statistics:"
- + f"\n{len(self._message_logs)} total messages"
- + f"\n{system_count} system"
- + f"\n{user_count} user"
- + f"\n{assistant_count} assistant"
- + f"\n{function_count} function"
- + f"\n{other_count} other"
- )
- return f"\n### RECALL MEMORY ###" + f"\n{memory_str}"
-
- def insert(self, message):
- raise NotImplementedError("This should be handled by the PersistenceManager, recall memory is just a search layer on top")
-
- def text_search(self, query_string, count=None, start=None):
- # in the dummy version, run an (inefficient) case-insensitive match search
- message_pool = [d for d in self._message_logs if d["message"]["role"] not in ["system", "function"]]
-
- printd(
- f"recall_memory.text_search: searching for {query_string} (c={count}, s={start}) in {len(self._message_logs)} total messages"
- )
- matches = [
- d for d in message_pool if d["message"]["content"] is not None and query_string.lower() in d["message"]["content"].lower()
- ]
- printd(f"recall_memory - matches:\n{matches[start:start+count]}")
-
- # start/count support paging through results
- if start is not None and count is not None:
- return matches[start : start + count], len(matches)
- elif start is None and count is not None:
- return matches[:count], len(matches)
- elif start is not None and count is None:
- return matches[start:], len(matches)
- else:
- return matches, len(matches)
-
- def date_search(self, start_date, end_date, count=None, start=None):
- message_pool = [d for d in self._message_logs if d["message"]["role"] not in ["system", "function"]]
-
- # First, validate the start_date and end_date format
- if not validate_date_format(start_date) or not validate_date_format(end_date):
- raise ValueError("Invalid date format. Expected format: YYYY-MM-DD")
-
- # Convert dates to datetime objects for comparison
- start_date_dt = datetime.datetime.strptime(start_date, "%Y-%m-%d")
- end_date_dt = datetime.datetime.strptime(end_date, "%Y-%m-%d")
-
- # Next, match items inside self._message_logs
- matches = [
- d
- for d in message_pool
- if start_date_dt <= datetime.datetime.strptime(extract_date_from_timestamp(d["timestamp"]), "%Y-%m-%d") <= end_date_dt
- ]
-
- # start/count support paging through results
- start = int(start) if start is None else start
- count = int(count) if count is None else count
- if start is not None and count is not None:
- return matches[start : start + count], len(matches)
- elif start is None and count is not None:
- return matches[:count], len(matches)
- elif start is not None and count is None:
- return matches[start:], len(matches)
- else:
- return matches, len(matches)
-
-
-class BaseRecallMemory(RecallMemory):
- """Recall memory based on base functions implemented by storage connectors"""
-
- def __init__(self, agent_state, restrict_search_to_summaries=False):
- # If true, the pool of messages that can be queried are the automated summaries only
- # (generated when the conversation window needs to be shortened)
- self.restrict_search_to_summaries = restrict_search_to_summaries
- from memgpt.agent_store.storage import StorageConnector
-
- self.agent_state = agent_state
-
- # create embedding model
- self.embed_model = embedding_model(agent_state.embedding_config)
- self.embedding_chunk_size = agent_state.embedding_config.embedding_chunk_size
-
- # create storage backend
- self.storage = StorageConnector.get_recall_storage_connector(user_id=agent_state.user_id, agent_id=agent_state.id)
- # TODO: have some mechanism for cleanup otherwise will lead to OOM
- self.cache = {}
-
- def get_all(self, start=0, count=None):
- results = self.storage.get_all(start, count)
- results_json = [message.to_openai_dict() for message in results]
- return results_json, len(results)
-
- def text_search(self, query_string, count=None, start=None):
- results = self.storage.query_text(query_string, count, start)
- results_json = [message.to_openai_dict_search_results() for message in results]
- return results_json, len(results)
-
- def date_search(self, start_date, end_date, count=None, start=None):
- results = self.storage.query_date(start_date, end_date, count, start)
- results_json = [message.to_openai_dict_search_results() for message in results]
- return results_json, len(results)
-
- def __repr__(self) -> str:
- total = self.storage.size()
- system_count = self.storage.size(filters={"role": "system"})
- user_count = self.storage.size(filters={"role": "user"})
- assistant_count = self.storage.size(filters={"role": "assistant"})
- function_count = self.storage.size(filters={"role": "function"})
- other_count = total - (system_count + user_count + assistant_count + function_count)
-
- memory_str = (
- f"Statistics:"
- + f"\n{total} total messages"
- + f"\n{system_count} system"
- + f"\n{user_count} user"
- + f"\n{assistant_count} assistant"
- + f"\n{function_count} function"
- + f"\n{other_count} other"
- )
- return f"\n### RECALL MEMORY ###" + f"\n{memory_str}"
-
- def insert(self, message: Message):
- self.storage.insert(message)
-
- def insert_many(self, messages: List[Message]):
- self.storage.insert_many(messages)
-
- def save(self):
- self.storage.save()
-
- def __len__(self):
- return self.storage.size()
-
-
-class EmbeddingArchivalMemory(ArchivalMemory):
- """Archival memory with embedding based search"""
-
- def __init__(self, agent_state: AgentState, top_k: Optional[int] = 100):
- """Init function for archival memory
-
- :param archival_memory_database: name of dataset to pre-fill archival with
- :type archival_memory_database: str
- """
- from memgpt.agent_store.storage import StorageConnector
-
- self.top_k = top_k
- self.agent_state = agent_state
-
- # create embedding model
- self.embed_model = embedding_model(agent_state.embedding_config)
- self.embedding_chunk_size = agent_state.embedding_config.embedding_chunk_size
- assert self.embedding_chunk_size, f"Must set {agent_state.embedding_config.embedding_chunk_size}"
-
- # create storage backend
- self.storage = StorageConnector.get_archival_storage_connector(user_id=agent_state.user_id, agent_id=agent_state.id)
- # TODO: have some mechanism for cleanup otherwise will lead to OOM
- self.cache = {}
-
- def create_passage(self, text, embedding):
- return Passage(
- user_id=self.agent_state.user_id,
- agent_id=self.agent_state.id,
- text=text,
- embedding=embedding,
- embedding_dim=self.agent_state.embedding_config.embedding_dim,
- embedding_model=self.agent_state.embedding_config.embedding_model,
- )
-
- def save(self):
- """Save the index to disk"""
- self.storage.save()
-
- def insert(self, memory_string, return_ids=False) -> Union[bool, List[uuid.UUID]]:
- """Embed and save memory string"""
-
- if not isinstance(memory_string, str):
- raise TypeError("memory must be a string")
-
- try:
- passages = []
-
- # breakup string into passages
- for text in parse_and_chunk_text(memory_string, self.embedding_chunk_size):
- embedding = self.embed_model.get_text_embedding(text)
- # fixing weird bug where type returned isn't a list, but instead is an object
- # eg: embedding={'object': 'list', 'data': [{'object': 'embedding', 'embedding': [-0.0071973633, -0.07893023,
- if isinstance(embedding, dict):
- try:
- embedding = embedding["data"][0]["embedding"]
- except (KeyError, IndexError):
- # TODO as a fallback, see if we can find any lists in the payload
- raise TypeError(
- f"Got back an unexpected payload from text embedding function, type={type(embedding)}, value={embedding}"
- )
- passages.append(self.create_passage(text, embedding))
-
- # grab the return IDs before the list gets modified
- ids = [str(p.id) for p in passages]
-
- # insert passages
- self.storage.insert_many(passages)
-
- if return_ids:
- return ids
- else:
- return True
-
- except Exception as e:
- print("Archival insert error", e)
- raise e
-
- def search(self, query_string, count=None, start=None):
- """Search query string"""
- if not isinstance(query_string, str):
- return TypeError("query must be a string")
-
- try:
- if query_string not in self.cache:
- # self.cache[query_string] = self.retriever.retrieve(query_string)
- query_vec = query_embedding(self.embed_model, query_string)
- self.cache[query_string] = self.storage.query(query_string, query_vec, top_k=self.top_k)
-
- start = int(start if start else 0)
- count = int(count if count else self.top_k)
- end = min(count + start, len(self.cache[query_string]))
-
- results = self.cache[query_string][start:end]
- results = [{"timestamp": get_local_time(), "content": node.text} for node in results]
- return results, len(results)
- except Exception as e:
- print("Archival search error", e)
- raise e
-
- def __repr__(self) -> str:
- limit = 10
- passages = []
- for passage in list(self.storage.get_all(limit=limit)): # TODO: only get first 10
- passages.append(str(passage.text))
- memory_str = "\n".join(passages)
- return f"\n### ARCHIVAL MEMORY ###" + f"\n{memory_str}" + f"\nSize: {self.storage.size()}"
-
- def __len__(self):
- return self.storage.size()
+import datetime
+import uuid
+from abc import ABC, abstractmethod
+from typing import List, Optional, Tuple, Union
+
+from pydantic import BaseModel, validator
+
+from memgpt.constants import MESSAGE_SUMMARY_REQUEST_ACK, MESSAGE_SUMMARY_WARNING_FRAC
+from memgpt.data_types import AgentState, Message, Passage
+from memgpt.embeddings import embedding_model, parse_and_chunk_text, query_embedding
+from memgpt.llm_api.llm_api_tools import create
+from memgpt.prompts.gpt_summarize import SYSTEM as SUMMARY_PROMPT_SYSTEM
+from memgpt.utils import (
+ count_tokens,
+ extract_date_from_timestamp,
+ get_local_time,
+ printd,
+ validate_date_format,
+)
+
+
+class MemoryModule(BaseModel):
+ """Base class for memory modules"""
+
+ description: Optional[str] = None
+ limit: int = 2000
+ value: Optional[Union[List[str], str]] = None
+
+ def __setattr__(self, name, value):
+ """Run validation if self.value is updated"""
+ super().__setattr__(name, value)
+ if name == "value":
+ # run validation
+ self.__class__.validate(self.dict(exclude_unset=True))
+
+ @validator("value", always=True)
+ def check_value_length(cls, v, values):
+ if v is not None:
+ # Fetching the limit from the values dictionary
+ limit = values.get("limit", 2000) # Default to 2000 if limit is not yet set
+
+ # Check if the value exceeds the limit
+ if isinstance(v, str):
+ length = len(v)
+ elif isinstance(v, list):
+ length = sum(len(item) for item in v)
+ else:
+ raise ValueError("Value must be either a string or a list of strings.")
+
+ if length > limit:
+ error_msg = f"Edit failed: Exceeds {limit} character limit (requested {length})."
+ # TODO: add archival memory error?
+ raise ValueError(error_msg)
+ return v
+
+ def __len__(self):
+ return len(str(self))
+
+ def __str__(self) -> str:
+ if isinstance(self.value, list):
+ return ",".join(self.value)
+ elif isinstance(self.value, str):
+ return self.value
+ else:
+ return ""
+
+
+class BaseMemory:
+
+ def __init__(self):
+ self.memory = {}
+
+ @classmethod
+ def load(cls, state: dict):
+ """Load memory from dictionary object"""
+ obj = cls()
+ for key, value in state.items():
+ obj.memory[key] = MemoryModule(**value)
+ return obj
+
+ def __str__(self) -> str:
+ """Representation of the memory in-context"""
+ section_strs = []
+ for section, module in self.memory.items():
+ section_strs.append(f'<{section} characters="{len(module)}/{module.limit}">\n{module.value}\n')
+ return "\n".join(section_strs)
+
+ def to_dict(self):
+ """Convert to dictionary representation"""
+ return {key: value.dict() for key, value in self.memory.items()}
+
+
+class ChatMemory(BaseMemory):
+
+ def __init__(self, persona: str, human: str, limit: int = 2000):
+ self.memory = {
+ "persona": MemoryModule(name="persona", value=persona, limit=limit),
+ "human": MemoryModule(name="human", value=human, limit=limit),
+ }
+
+ def core_memory_append(self, name: str, content: str) -> Optional[str]:
+ """
+ Append to the contents of core memory.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value += "\n" + content
+ return None
+
+ def core_memory_replace(self, name: str, old_content: str, new_content: str) -> Optional[str]:
+ """
+ Replace the contents of core memory. To delete memories, use an empty string for new_content.
+
+ Args:
+ name (str): Section of the memory to be edited (persona or human).
+ old_content (str): String to replace. Must be an exact match.
+ new_content (str): Content to write to the memory. All unicode (including emojis) are supported.
+
+ Returns:
+ Optional[str]: None is always returned as this function does not produce a response.
+ """
+ self.memory[name].value = self.memory[name].value.replace(old_content, new_content)
+ return None
+
+
+def get_memory_functions(cls: BaseMemory) -> List[callable]:
+ """Get memory functions for a memory class"""
+ functions = {}
+ for func_name in dir(cls):
+ if func_name.startswith("_") or func_name in ["load", "to_dict"]: # skip base functions
+ continue
+ func = getattr(cls, func_name)
+ if callable(func):
+ functions[func_name] = func
+ return functions
+
+
+# class CoreMemory(object):
+# """Held in-context inside the system message
+#
+# Core Memory: Refers to the system block, which provides essential, foundational context to the AI.
+# This includes the persona information, essential user details,
+# and any other baseline data you deem necessary for the AI's basic functioning.
+# """
+#
+# def __init__(self, persona=None, human=None, persona_char_limit=None, human_char_limit=None, archival_memory_exists=True):
+# self.persona = persona
+# self.human = human
+# self.persona_char_limit = persona_char_limit
+# self.human_char_limit = human_char_limit
+#
+# # affects the error message the AI will see on overflow inserts
+# self.archival_memory_exists = archival_memory_exists
+#
+# def __repr__(self) -> str:
+# return f"\n### CORE MEMORY ###" + f"\n=== Persona ===\n{self.persona}" + f"\n\n=== Human ===\n{self.human}"
+#
+# def to_dict(self):
+# return {
+# "persona": self.persona,
+# "human": self.human,
+# }
+#
+# @classmethod
+# def load(cls, state):
+# return cls(state["persona"], state["human"])
+#
+# def edit_persona(self, new_persona):
+# if self.persona_char_limit and len(new_persona) > self.persona_char_limit:
+# error_msg = f"Edit failed: Exceeds {self.persona_char_limit} character limit (requested {len(new_persona)})."
+# if self.archival_memory_exists:
+# error_msg = f"{error_msg} Consider summarizing existing core memories in 'persona' and/or moving lower priority content to archival memory to free up space in core memory, then trying again."
+# raise ValueError(error_msg)
+#
+# self.persona = new_persona
+# return len(self.persona)
+#
+# def edit_human(self, new_human):
+# if self.human_char_limit and len(new_human) > self.human_char_limit:
+# error_msg = f"Edit failed: Exceeds {self.human_char_limit} character limit (requested {len(new_human)})."
+# if self.archival_memory_exists:
+# error_msg = f"{error_msg} Consider summarizing existing core memories in 'human' and/or moving lower priority content to archival memory to free up space in core memory, then trying again."
+# raise ValueError(error_msg)
+#
+# self.human = new_human
+# return len(self.human)
+#
+# def edit(self, field, content):
+# if field == "persona":
+# return self.edit_persona(content)
+# elif field == "human":
+# return self.edit_human(content)
+# else:
+# raise KeyError(f'No memory section named {field} (must be either "persona" or "human")')
+#
+# def edit_append(self, field, content, sep="\n"):
+# if field == "persona":
+# new_content = self.persona + sep + content
+# return self.edit_persona(new_content)
+# elif field == "human":
+# new_content = self.human + sep + content
+# return self.edit_human(new_content)
+# else:
+# raise KeyError(f'No memory section named {field} (must be either "persona" or "human")')
+#
+# def edit_replace(self, field, old_content, new_content):
+# if len(old_content) == 0:
+# raise ValueError("old_content cannot be an empty string (must specify old_content to replace)")
+#
+# if field == "persona":
+# if old_content in self.persona:
+# new_persona = self.persona.replace(old_content, new_content)
+# return self.edit_persona(new_persona)
+# else:
+# raise ValueError("Content not found in persona (make sure to use exact string)")
+# elif field == "human":
+# if old_content in self.human:
+# new_human = self.human.replace(old_content, new_content)
+# return self.edit_human(new_human)
+# else:
+# raise ValueError("Content not found in human (make sure to use exact string)")
+# else:
+# raise KeyError(f'No memory section named {field} (must be either "persona" or "human")')
+
+
+def _format_summary_history(message_history: List[Message]):
+ # TODO use existing prompt formatters for this (eg ChatML)
+ return "\n".join([f"{m.role}: {m.text}" for m in message_history])
+
+
+def summarize_messages(
+ agent_state: AgentState,
+ message_sequence_to_summarize: List[Message],
+ insert_acknowledgement_assistant_message: bool = True,
+):
+ """Summarize a message sequence using GPT"""
+ # we need the context_window
+ context_window = agent_state.llm_config.context_window
+
+ summary_prompt = SUMMARY_PROMPT_SYSTEM
+ summary_input = _format_summary_history(message_sequence_to_summarize)
+ summary_input_tkns = count_tokens(summary_input)
+ if summary_input_tkns > MESSAGE_SUMMARY_WARNING_FRAC * context_window:
+ trunc_ratio = (MESSAGE_SUMMARY_WARNING_FRAC * context_window / summary_input_tkns) * 0.8 # For good measure...
+ cutoff = int(len(message_sequence_to_summarize) * trunc_ratio)
+ summary_input = str(
+ [summarize_messages(agent_state, message_sequence_to_summarize=message_sequence_to_summarize[:cutoff])]
+ + message_sequence_to_summarize[cutoff:]
+ )
+
+ dummy_user_id = uuid.uuid4()
+ dummy_agent_id = uuid.uuid4()
+ message_sequence = []
+ message_sequence.append(Message(user_id=dummy_user_id, agent_id=dummy_agent_id, role="system", text=summary_prompt))
+ if insert_acknowledgement_assistant_message:
+ message_sequence.append(Message(user_id=dummy_user_id, agent_id=dummy_agent_id, role="assistant", text=MESSAGE_SUMMARY_REQUEST_ACK))
+ message_sequence.append(Message(user_id=dummy_user_id, agent_id=dummy_agent_id, role="user", text=summary_input))
+
+ response = create(
+ llm_config=agent_state.llm_config,
+ user_id=agent_state.user_id,
+ messages=message_sequence,
+ )
+
+ printd(f"summarize_messages gpt reply: {response.choices[0]}")
+ reply = response.choices[0].message.content
+ return reply
+
+
+class ArchivalMemory(ABC):
+ @abstractmethod
+ def insert(self, memory_string: str):
+ """Insert new archival memory
+
+ :param memory_string: Memory string to insert
+ :type memory_string: str
+ """
+
+ @abstractmethod
+ def search(self, query_string, count=None, start=None) -> Tuple[List[str], int]:
+ """Search archival memory
+
+ :param query_string: Query string
+ :type query_string: str
+ :param count: Number of results to return (None for all)
+ :type count: Optional[int]
+ :param start: Offset to start returning results from (None if 0)
+ :type start: Optional[int]
+
+ :return: Tuple of (list of results, total number of results)
+ """
+
+ @abstractmethod
+ def __repr__(self) -> str:
+ pass
+
+
+class RecallMemory(ABC):
+ @abstractmethod
+ def text_search(self, query_string, count=None, start=None):
+ """Search messages that match query_string in recall memory"""
+
+ @abstractmethod
+ def date_search(self, start_date, end_date, count=None, start=None):
+ """Search messages between start_date and end_date in recall memory"""
+
+ @abstractmethod
+ def __repr__(self) -> str:
+ pass
+
+ @abstractmethod
+ def insert(self, message: Message):
+ """Insert message into recall memory"""
+
+
+class DummyRecallMemory(RecallMemory):
+ """Dummy in-memory version of a recall memory database (eg run on MongoDB)
+
+ Recall memory here is basically just a full conversation history with the user.
+ Queryable via string matching, or date matching.
+
+ Recall Memory: The AI's capability to search through past interactions,
+ effectively allowing it to 'remember' prior engagements with a user.
+ """
+
+ def __init__(self, message_database=None, restrict_search_to_summaries=False):
+ self._message_logs = [] if message_database is None else message_database # consists of full message dicts
+
+ # If true, the pool of messages that can be queried are the automated summaries only
+ # (generated when the conversation window needs to be shortened)
+ self.restrict_search_to_summaries = restrict_search_to_summaries
+
+ def __len__(self):
+ return len(self._message_logs)
+
+ def __repr__(self) -> str:
+ # don't dump all the conversations, just statistics
+ system_count = user_count = assistant_count = function_count = other_count = 0
+ for msg in self._message_logs:
+ role = msg["message"]["role"]
+ if role == "system":
+ system_count += 1
+ elif role == "user":
+ user_count += 1
+ elif role == "assistant":
+ assistant_count += 1
+ elif role == "function":
+ function_count += 1
+ else:
+ other_count += 1
+ memory_str = (
+ f"Statistics:"
+ + f"\n{len(self._message_logs)} total messages"
+ + f"\n{system_count} system"
+ + f"\n{user_count} user"
+ + f"\n{assistant_count} assistant"
+ + f"\n{function_count} function"
+ + f"\n{other_count} other"
+ )
+ return f"\n### RECALL MEMORY ###" + f"\n{memory_str}"
+
+ def insert(self, message):
+ raise NotImplementedError("This should be handled by the PersistenceManager, recall memory is just a search layer on top")
+
+ def text_search(self, query_string, count=None, start=None):
+ # in the dummy version, run an (inefficient) case-insensitive match search
+ message_pool = [d for d in self._message_logs if d["message"]["role"] not in ["system", "function"]]
+
+ printd(
+ f"recall_memory.text_search: searching for {query_string} (c={count}, s={start}) in {len(self._message_logs)} total messages"
+ )
+ matches = [
+ d for d in message_pool if d["message"]["content"] is not None and query_string.lower() in d["message"]["content"].lower()
+ ]
+ printd(f"recall_memory - matches:\n{matches[start:start+count]}")
+
+ # start/count support paging through results
+ if start is not None and count is not None:
+ return matches[start : start + count], len(matches)
+ elif start is None and count is not None:
+ return matches[:count], len(matches)
+ elif start is not None and count is None:
+ return matches[start:], len(matches)
+ else:
+ return matches, len(matches)
+
+ def date_search(self, start_date, end_date, count=None, start=None):
+ message_pool = [d for d in self._message_logs if d["message"]["role"] not in ["system", "function"]]
+
+ # First, validate the start_date and end_date format
+ if not validate_date_format(start_date) or not validate_date_format(end_date):
+ raise ValueError("Invalid date format. Expected format: YYYY-MM-DD")
+
+ # Convert dates to datetime objects for comparison
+ start_date_dt = datetime.datetime.strptime(start_date, "%Y-%m-%d")
+ end_date_dt = datetime.datetime.strptime(end_date, "%Y-%m-%d")
+
+ # Next, match items inside self._message_logs
+ matches = [
+ d
+ for d in message_pool
+ if start_date_dt <= datetime.datetime.strptime(extract_date_from_timestamp(d["timestamp"]), "%Y-%m-%d") <= end_date_dt
+ ]
+
+ # start/count support paging through results
+ start = int(start) if start is None else start
+ count = int(count) if count is None else count
+ if start is not None and count is not None:
+ return matches[start : start + count], len(matches)
+ elif start is None and count is not None:
+ return matches[:count], len(matches)
+ elif start is not None and count is None:
+ return matches[start:], len(matches)
+ else:
+ return matches, len(matches)
+
+
+class BaseRecallMemory(RecallMemory):
+ """Recall memory based on base functions implemented by storage connectors"""
+
+ def __init__(self, agent_state, restrict_search_to_summaries=False):
+ # If true, the pool of messages that can be queried are the automated summaries only
+ # (generated when the conversation window needs to be shortened)
+ self.restrict_search_to_summaries = restrict_search_to_summaries
+ from memgpt.agent_store.storage import StorageConnector
+
+ self.agent_state = agent_state
+
+ # create embedding model
+ self.embed_model = embedding_model(agent_state.embedding_config)
+ self.embedding_chunk_size = agent_state.embedding_config.embedding_chunk_size
+
+ # create storage backend
+ self.storage = StorageConnector.get_recall_storage_connector(user_id=agent_state.user_id, agent_id=agent_state.id)
+ # TODO: have some mechanism for cleanup otherwise will lead to OOM
+ self.cache = {}
+
+ def get_all(self, start=0, count=None):
+ results = self.storage.get_all(start, count)
+ results_json = [message.to_openai_dict() for message in results]
+ return results_json, len(results)
+
+ def text_search(self, query_string, count=None, start=None):
+ results = self.storage.query_text(query_string, count, start)
+ results_json = [message.to_openai_dict_search_results() for message in results]
+ return results_json, len(results)
+
+ def date_search(self, start_date, end_date, count=None, start=None):
+ results = self.storage.query_date(start_date, end_date, count, start)
+ results_json = [message.to_openai_dict_search_results() for message in results]
+ return results_json, len(results)
+
+ def __repr__(self) -> str:
+ total = self.storage.size()
+ system_count = self.storage.size(filters={"role": "system"})
+ user_count = self.storage.size(filters={"role": "user"})
+ assistant_count = self.storage.size(filters={"role": "assistant"})
+ function_count = self.storage.size(filters={"role": "function"})
+ other_count = total - (system_count + user_count + assistant_count + function_count)
+
+ memory_str = (
+ f"Statistics:"
+ + f"\n{total} total messages"
+ + f"\n{system_count} system"
+ + f"\n{user_count} user"
+ + f"\n{assistant_count} assistant"
+ + f"\n{function_count} function"
+ + f"\n{other_count} other"
+ )
+ return f"\n### RECALL MEMORY ###" + f"\n{memory_str}"
+
+ def insert(self, message: Message):
+ self.storage.insert(message)
+
+ def insert_many(self, messages: List[Message]):
+ self.storage.insert_many(messages)
+
+ def save(self):
+ self.storage.save()
+
+ def __len__(self):
+ return self.storage.size()
+
+
+class EmbeddingArchivalMemory(ArchivalMemory):
+ """Archival memory with embedding based search"""
+
+ def __init__(self, agent_state: AgentState, top_k: Optional[int] = 100):
+ """Init function for archival memory
+
+ :param archival_memory_database: name of dataset to pre-fill archival with
+ :type archival_memory_database: str
+ """
+ from memgpt.agent_store.storage import StorageConnector
+
+ self.top_k = top_k
+ self.agent_state = agent_state
+
+ # create embedding model
+ self.embed_model = embedding_model(agent_state.embedding_config)
+ self.embedding_chunk_size = agent_state.embedding_config.embedding_chunk_size
+ assert self.embedding_chunk_size, f"Must set {agent_state.embedding_config.embedding_chunk_size}"
+
+ # create storage backend
+ self.storage = StorageConnector.get_archival_storage_connector(user_id=agent_state.user_id, agent_id=agent_state.id)
+ # TODO: have some mechanism for cleanup otherwise will lead to OOM
+ self.cache = {}
+
+ def create_passage(self, text, embedding):
+ return Passage(
+ user_id=self.agent_state.user_id,
+ agent_id=self.agent_state.id,
+ text=text,
+ embedding=embedding,
+ embedding_dim=self.agent_state.embedding_config.embedding_dim,
+ embedding_model=self.agent_state.embedding_config.embedding_model,
+ )
+
+ def save(self):
+ """Save the index to disk"""
+ self.storage.save()
+
+ def insert(self, memory_string, return_ids=False) -> Union[bool, List[uuid.UUID]]:
+ """Embed and save memory string"""
+
+ if not isinstance(memory_string, str):
+ raise TypeError("memory must be a string")
+
+ try:
+ passages = []
+
+ # breakup string into passages
+ for text in parse_and_chunk_text(memory_string, self.embedding_chunk_size):
+ embedding = self.embed_model.get_text_embedding(text)
+ # fixing weird bug where type returned isn't a list, but instead is an object
+ # eg: embedding={'object': 'list', 'data': [{'object': 'embedding', 'embedding': [-0.0071973633, -0.07893023,
+ if isinstance(embedding, dict):
+ try:
+ embedding = embedding["data"][0]["embedding"]
+ except (KeyError, IndexError):
+ # TODO as a fallback, see if we can find any lists in the payload
+ raise TypeError(
+ f"Got back an unexpected payload from text embedding function, type={type(embedding)}, value={embedding}"
+ )
+ passages.append(self.create_passage(text, embedding))
+
+ # grab the return IDs before the list gets modified
+ ids = [str(p.id) for p in passages]
+
+ # insert passages
+ self.storage.insert_many(passages)
+
+ if return_ids:
+ return ids
+ else:
+ return True
+
+ except Exception as e:
+ print("Archival insert error", e)
+ raise e
+
+ def search(self, query_string, count=None, start=None):
+ """Search query string"""
+ if not isinstance(query_string, str):
+ return TypeError("query must be a string")
+
+ try:
+ if query_string not in self.cache:
+ # self.cache[query_string] = self.retriever.retrieve(query_string)
+ query_vec = query_embedding(self.embed_model, query_string)
+ self.cache[query_string] = self.storage.query(query_string, query_vec, top_k=self.top_k)
+
+ start = int(start if start else 0)
+ count = int(count if count else self.top_k)
+ end = min(count + start, len(self.cache[query_string]))
+
+ results = self.cache[query_string][start:end]
+ results = [{"timestamp": get_local_time(), "content": node.text} for node in results]
+ return results, len(results)
+ except Exception as e:
+ print("Archival search error", e)
+ raise e
+
+ def __repr__(self) -> str:
+ limit = 10
+ passages = []
+ for passage in list(self.storage.get_all(limit=limit)): # TODO: only get first 10
+ passages.append(str(passage.text))
+ memory_str = "\n".join(passages)
+ return f"\n### ARCHIVAL MEMORY ###" + f"\n{memory_str}" + f"\nSize: {self.storage.size()}"
+
+ def __len__(self):
+ return self.storage.size()
diff --git a/memgpt/persistence_manager.py b/memgpt/persistence_manager.py
index bbead880..a095417b 100644
--- a/memgpt/persistence_manager.py
+++ b/memgpt/persistence_manager.py
@@ -1,155 +1,155 @@
-from abc import ABC, abstractmethod
-from datetime import datetime
-from typing import List
-
-from memgpt.data_types import AgentState, Message
-from memgpt.memory import BaseRecallMemory, EmbeddingArchivalMemory
-from memgpt.utils import printd
-
-
-def parse_formatted_time(formatted_time: str):
- # parse times returned by memgpt.utils.get_formatted_time()
- try:
- return datetime.strptime(formatted_time.strip(), "%Y-%m-%d %I:%M:%S %p %Z%z")
- except:
- return datetime.strptime(formatted_time.strip(), "%Y-%m-%d %I:%M:%S %p")
-
-
-class PersistenceManager(ABC):
- @abstractmethod
- def trim_messages(self, num):
- pass
-
- @abstractmethod
- def prepend_to_messages(self, added_messages):
- pass
-
- @abstractmethod
- def append_to_messages(self, added_messages):
- pass
-
- @abstractmethod
- def swap_system_message(self, new_system_message):
- pass
-
- @abstractmethod
- def update_memory(self, new_memory):
- pass
-
-
-class LocalStateManager(PersistenceManager):
- """In-memory state manager has nothing to manage, all agents are held in-memory"""
-
- recall_memory_cls = BaseRecallMemory
- archival_memory_cls = EmbeddingArchivalMemory
-
- def __init__(self, agent_state: AgentState):
- # Memory held in-state useful for debugging stateful versions
- self.memory = None
- # self.messages = [] # current in-context messages
- # self.all_messages = [] # all messages seen in current session (needed if lazily synchronizing state with DB)
- self.archival_memory = EmbeddingArchivalMemory(agent_state)
- self.recall_memory = BaseRecallMemory(agent_state)
- # self.agent_state = agent_state
-
- def save(self):
- """Ensure storage connectors save data"""
- self.archival_memory.save()
- self.recall_memory.save()
-
- def init(self, agent):
- """Connect persistent state manager to agent"""
- printd(f"Initializing {self.__class__.__name__} with agent object")
- # self.all_messages = [{"timestamp": get_local_time(), "message": msg} for msg in agent.messages.copy()]
- # self.messages = [{"timestamp": get_local_time(), "message": msg} for msg in agent.messages.copy()]
- self.memory = agent.memory
- # printd(f"{self.__class__.__name__}.all_messages.len = {len(self.all_messages)}")
- printd(f"{self.__class__.__name__}.messages.len = {len(self.messages)}")
-
- '''
- def json_to_message(self, message_json) -> Message:
- """Convert agent message JSON into Message object"""
-
- # get message
- if "message" in message_json:
- message = message_json["message"]
- else:
- message = message_json
-
- # get timestamp
- if "timestamp" in message_json:
- timestamp = parse_formatted_time(message_json["timestamp"])
- else:
- timestamp = get_local_time()
-
- # TODO: change this when we fully migrate to tool calls API
- if "function_call" in message:
- tool_calls = [
- ToolCall(
- id=message["tool_call_id"],
- tool_call_type="function",
- function={
- "name": message["function_call"]["name"],
- "arguments": message["function_call"]["arguments"],
- },
- )
- ]
- printd(f"Saving tool calls {[vars(tc) for tc in tool_calls]}")
- else:
- tool_calls = None
-
- # if message["role"] == "function":
- # message["role"] = "tool"
-
- return Message(
- user_id=self.agent_state.user_id,
- agent_id=self.agent_state.id,
- role=message["role"],
- text=message["content"],
- name=message["name"] if "name" in message else None,
- model=self.agent_state.llm_config.model,
- created_at=timestamp,
- tool_calls=tool_calls,
- tool_call_id=message["tool_call_id"] if "tool_call_id" in message else None,
- id=message["id"] if "id" in message else None,
- )
- '''
-
- def trim_messages(self, num):
- # printd(f"InMemoryStateManager.trim_messages")
- # self.messages = [self.messages[0]] + self.messages[num:]
- pass
-
- def prepend_to_messages(self, added_messages: List[Message]):
- # first tag with timestamps
- # added_messages = [{"timestamp": get_local_time(), "message": msg} for msg in added_messages]
-
- printd(f"{self.__class__.__name__}.prepend_to_message")
- # self.messages = [self.messages[0]] + added_messages + self.messages[1:]
-
- # add to recall memory
- self.recall_memory.insert_many([m for m in added_messages])
-
- def append_to_messages(self, added_messages: List[Message]):
- # first tag with timestamps
- # added_messages = [{"timestamp": get_local_time(), "message": msg} for msg in added_messages]
-
- printd(f"{self.__class__.__name__}.append_to_messages")
- # self.messages = self.messages + added_messages
-
- # add to recall memory
- self.recall_memory.insert_many([m for m in added_messages])
-
- def swap_system_message(self, new_system_message: Message):
- # first tag with timestamps
- # new_system_message = {"timestamp": get_local_time(), "message": new_system_message}
-
- printd(f"{self.__class__.__name__}.swap_system_message")
- # self.messages[0] = new_system_message
-
- # add to recall memory
- self.recall_memory.insert(new_system_message)
-
- def update_memory(self, new_memory):
- printd(f"{self.__class__.__name__}.update_memory")
- self.memory = new_memory
+from abc import ABC, abstractmethod
+from datetime import datetime
+from typing import List
+
+from memgpt.data_types import AgentState, Message
+from memgpt.memory import BaseRecallMemory, EmbeddingArchivalMemory
+from memgpt.utils import printd
+
+
+def parse_formatted_time(formatted_time: str):
+ # parse times returned by memgpt.utils.get_formatted_time()
+ try:
+ return datetime.strptime(formatted_time.strip(), "%Y-%m-%d %I:%M:%S %p %Z%z")
+ except:
+ return datetime.strptime(formatted_time.strip(), "%Y-%m-%d %I:%M:%S %p")
+
+
+class PersistenceManager(ABC):
+ @abstractmethod
+ def trim_messages(self, num):
+ pass
+
+ @abstractmethod
+ def prepend_to_messages(self, added_messages):
+ pass
+
+ @abstractmethod
+ def append_to_messages(self, added_messages):
+ pass
+
+ @abstractmethod
+ def swap_system_message(self, new_system_message):
+ pass
+
+ @abstractmethod
+ def update_memory(self, new_memory):
+ pass
+
+
+class LocalStateManager(PersistenceManager):
+ """In-memory state manager has nothing to manage, all agents are held in-memory"""
+
+ recall_memory_cls = BaseRecallMemory
+ archival_memory_cls = EmbeddingArchivalMemory
+
+ def __init__(self, agent_state: AgentState):
+ # Memory held in-state useful for debugging stateful versions
+ self.memory = None
+ # self.messages = [] # current in-context messages
+ # self.all_messages = [] # all messages seen in current session (needed if lazily synchronizing state with DB)
+ self.archival_memory = EmbeddingArchivalMemory(agent_state)
+ self.recall_memory = BaseRecallMemory(agent_state)
+ # self.agent_state = agent_state
+
+ def save(self):
+ """Ensure storage connectors save data"""
+ self.archival_memory.save()
+ self.recall_memory.save()
+
+ def init(self, agent):
+ """Connect persistent state manager to agent"""
+ printd(f"Initializing {self.__class__.__name__} with agent object")
+ # self.all_messages = [{"timestamp": get_local_time(), "message": msg} for msg in agent.messages.copy()]
+ # self.messages = [{"timestamp": get_local_time(), "message": msg} for msg in agent.messages.copy()]
+ self.memory = agent.memory
+ # printd(f"{self.__class__.__name__}.all_messages.len = {len(self.all_messages)}")
+ printd(f"{self.__class__.__name__}.messages.len = {len(self.messages)}")
+
+ '''
+ def json_to_message(self, message_json) -> Message:
+ """Convert agent message JSON into Message object"""
+
+ # get message
+ if "message" in message_json:
+ message = message_json["message"]
+ else:
+ message = message_json
+
+ # get timestamp
+ if "timestamp" in message_json:
+ timestamp = parse_formatted_time(message_json["timestamp"])
+ else:
+ timestamp = get_local_time()
+
+ # TODO: change this when we fully migrate to tool calls API
+ if "function_call" in message:
+ tool_calls = [
+ ToolCall(
+ id=message["tool_call_id"],
+ tool_call_type="function",
+ function={
+ "name": message["function_call"]["name"],
+ "arguments": message["function_call"]["arguments"],
+ },
+ )
+ ]
+ printd(f"Saving tool calls {[vars(tc) for tc in tool_calls]}")
+ else:
+ tool_calls = None
+
+ # if message["role"] == "function":
+ # message["role"] = "tool"
+
+ return Message(
+ user_id=self.agent_state.user_id,
+ agent_id=self.agent_state.id,
+ role=message["role"],
+ text=message["content"],
+ name=message["name"] if "name" in message else None,
+ model=self.agent_state.llm_config.model,
+ created_at=timestamp,
+ tool_calls=tool_calls,
+ tool_call_id=message["tool_call_id"] if "tool_call_id" in message else None,
+ id=message["id"] if "id" in message else None,
+ )
+ '''
+
+ def trim_messages(self, num):
+ # printd(f"InMemoryStateManager.trim_messages")
+ # self.messages = [self.messages[0]] + self.messages[num:]
+ pass
+
+ def prepend_to_messages(self, added_messages: List[Message]):
+ # first tag with timestamps
+ # added_messages = [{"timestamp": get_local_time(), "message": msg} for msg in added_messages]
+
+ printd(f"{self.__class__.__name__}.prepend_to_message")
+ # self.messages = [self.messages[0]] + added_messages + self.messages[1:]
+
+ # add to recall memory
+ self.recall_memory.insert_many([m for m in added_messages])
+
+ def append_to_messages(self, added_messages: List[Message]):
+ # first tag with timestamps
+ # added_messages = [{"timestamp": get_local_time(), "message": msg} for msg in added_messages]
+
+ printd(f"{self.__class__.__name__}.append_to_messages")
+ # self.messages = self.messages + added_messages
+
+ # add to recall memory
+ self.recall_memory.insert_many([m for m in added_messages])
+
+ def swap_system_message(self, new_system_message: Message):
+ # first tag with timestamps
+ # new_system_message = {"timestamp": get_local_time(), "message": new_system_message}
+
+ printd(f"{self.__class__.__name__}.swap_system_message")
+ # self.messages[0] = new_system_message
+
+ # add to recall memory
+ self.recall_memory.insert(new_system_message)
+
+ def update_memory(self, new_memory):
+ printd(f"{self.__class__.__name__}.update_memory")
+ self.memory = new_memory
diff --git a/memgpt/presets/presets.py b/memgpt/presets/presets.py
index 372195f1..b17f5277 100644
--- a/memgpt/presets/presets.py
+++ b/memgpt/presets/presets.py
@@ -1,91 +1,91 @@
-import importlib
-import inspect
-import os
-import uuid
-
-from memgpt.data_types import AgentState, Preset
-from memgpt.functions.functions import load_function_set
-from memgpt.interface import AgentInterface
-from memgpt.metadata import MetadataStore
-from memgpt.models.pydantic_models import HumanModel, PersonaModel, ToolModel
-from memgpt.presets.utils import load_all_presets
-from memgpt.utils import list_human_files, list_persona_files, printd
-
-available_presets = load_all_presets()
-preset_options = list(available_presets.keys())
-
-
-def load_module_tools(module_name="base"):
- # return List[ToolModel] from base.py tools
- full_module_name = f"memgpt.functions.function_sets.{module_name}"
- try:
- module = importlib.import_module(full_module_name)
- except Exception as e:
- # Handle other general exceptions
- raise e
-
- # function tags
-
- try:
- # Load the function set
- functions_to_schema = load_function_set(module)
- except ValueError as e:
- err = f"Error loading function set '{module_name}': {e}"
- printd(err)
-
- # create tool in db
- tools = []
- for name, schema in functions_to_schema.items():
- # print([str(inspect.getsource(line)) for line in schema["imports"]])
- source_code = inspect.getsource(schema["python_function"])
- tags = [module_name]
- if module_name == "base":
- tags.append("memgpt-base")
-
- tools.append(
- ToolModel(
- name=name,
- tags=tags,
- source_type="python",
- module=schema["module"],
- source_code=source_code,
- json_schema=schema["json_schema"],
- )
- )
- return tools
-
-
-def add_default_tools(user_id: uuid.UUID, ms: MetadataStore):
- module_name = "base"
- for tool in load_module_tools(module_name=module_name):
- existing_tool = ms.get_tool(tool.name)
- if not existing_tool:
- ms.add_tool(tool)
-
-
-def add_default_humans_and_personas(user_id: uuid.UUID, ms: MetadataStore):
- for persona_file in list_persona_files():
- text = open(persona_file, "r", encoding="utf-8").read()
- name = os.path.basename(persona_file).replace(".txt", "")
- if ms.get_persona(user_id=user_id, name=name) is not None:
- printd(f"Persona '{name}' already exists for user '{user_id}'")
- continue
- persona = PersonaModel(name=name, text=text, user_id=user_id)
- ms.add_persona(persona)
- for human_file in list_human_files():
- text = open(human_file, "r", encoding="utf-8").read()
- name = os.path.basename(human_file).replace(".txt", "")
- if ms.get_human(user_id=user_id, name=name) is not None:
- printd(f"Human '{name}' already exists for user '{user_id}'")
- continue
- human = HumanModel(name=name, text=text, user_id=user_id)
- print(human, user_id)
- ms.add_human(human)
-
-
-# def create_agent_from_preset(preset_name, agent_config, model, persona, human, interface, persistence_manager):
-def create_agent_from_preset(
- agent_state: AgentState, preset: Preset, interface: AgentInterface, persona_is_file: bool = True, human_is_file: bool = True
-):
- """Initialize a new agent from a preset (combination of system + function)"""
- raise DeprecationWarning("Function no longer supported - pass a Preset object to Agent.__init__ instead")
+import importlib
+import inspect
+import os
+import uuid
+
+from memgpt.data_types import AgentState, Preset
+from memgpt.functions.functions import load_function_set
+from memgpt.interface import AgentInterface
+from memgpt.metadata import MetadataStore
+from memgpt.models.pydantic_models import HumanModel, PersonaModel, ToolModel
+from memgpt.presets.utils import load_all_presets
+from memgpt.utils import list_human_files, list_persona_files, printd
+
+available_presets = load_all_presets()
+preset_options = list(available_presets.keys())
+
+
+def load_module_tools(module_name="base"):
+ # return List[ToolModel] from base.py tools
+ full_module_name = f"memgpt.functions.function_sets.{module_name}"
+ try:
+ module = importlib.import_module(full_module_name)
+ except Exception as e:
+ # Handle other general exceptions
+ raise e
+
+ # function tags
+
+ try:
+ # Load the function set
+ functions_to_schema = load_function_set(module)
+ except ValueError as e:
+ err = f"Error loading function set '{module_name}': {e}"
+ printd(err)
+
+ # create tool in db
+ tools = []
+ for name, schema in functions_to_schema.items():
+ # print([str(inspect.getsource(line)) for line in schema["imports"]])
+ source_code = inspect.getsource(schema["python_function"])
+ tags = [module_name]
+ if module_name == "base":
+ tags.append("memgpt-base")
+
+ tools.append(
+ ToolModel(
+ name=name,
+ tags=tags,
+ source_type="python",
+ module=schema["module"],
+ source_code=source_code,
+ json_schema=schema["json_schema"],
+ )
+ )
+ return tools
+
+
+def add_default_tools(user_id: uuid.UUID, ms: MetadataStore):
+ module_name = "base"
+ for tool in load_module_tools(module_name=module_name):
+ existing_tool = ms.get_tool(tool.name)
+ if not existing_tool:
+ ms.add_tool(tool)
+
+
+def add_default_humans_and_personas(user_id: uuid.UUID, ms: MetadataStore):
+ for persona_file in list_persona_files():
+ text = open(persona_file, "r", encoding="utf-8").read()
+ name = os.path.basename(persona_file).replace(".txt", "")
+ if ms.get_persona(user_id=user_id, name=name) is not None:
+ printd(f"Persona '{name}' already exists for user '{user_id}'")
+ continue
+ persona = PersonaModel(name=name, text=text, user_id=user_id)
+ ms.add_persona(persona)
+ for human_file in list_human_files():
+ text = open(human_file, "r", encoding="utf-8").read()
+ name = os.path.basename(human_file).replace(".txt", "")
+ if ms.get_human(user_id=user_id, name=name) is not None:
+ printd(f"Human '{name}' already exists for user '{user_id}'")
+ continue
+ human = HumanModel(name=name, text=text, user_id=user_id)
+ print(human, user_id)
+ ms.add_human(human)
+
+
+# def create_agent_from_preset(preset_name, agent_config, model, persona, human, interface, persistence_manager):
+def create_agent_from_preset(
+ agent_state: AgentState, preset: Preset, interface: AgentInterface, persona_is_file: bool = True, human_is_file: bool = True
+):
+ """Initialize a new agent from a preset (combination of system + function)"""
+ raise DeprecationWarning("Function no longer supported - pass a Preset object to Agent.__init__ instead")
diff --git a/memgpt/prompts/gpt_functions.py b/memgpt/prompts/gpt_functions.py
index 4446a6c1..41af04a0 100644
--- a/memgpt/prompts/gpt_functions.py
+++ b/memgpt/prompts/gpt_functions.py
@@ -1,312 +1,312 @@
-from ..constants import FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT, MAX_PAUSE_HEARTBEATS
-
-# FUNCTIONS_PROMPT_MULTISTEP_NO_HEARTBEATS = FUNCTIONS_PROMPT_MULTISTEP[:-1]
-FUNCTIONS_CHAINING = {
- "send_message": {
- "name": "send_message",
- "description": "Sends a message to the human user.",
- "parameters": {
- "type": "object",
- "properties": {
- # https://json-schema.org/understanding-json-schema/reference/array.html
- "message": {
- "type": "string",
- "description": "Message contents. All unicode (including emojis) are supported.",
- },
- },
- "required": ["message"],
- },
- },
- "pause_heartbeats": {
- "name": "pause_heartbeats",
- "description": "Temporarily ignore timed heartbeats. You may still receive messages from manual heartbeats and other events.",
- "parameters": {
- "type": "object",
- "properties": {
- # https://json-schema.org/understanding-json-schema/reference/array.html
- "minutes": {
- "type": "integer",
- "description": f"Number of minutes to ignore heartbeats for. Max value of {MAX_PAUSE_HEARTBEATS} minutes ({MAX_PAUSE_HEARTBEATS//60} hours).",
- },
- },
- "required": ["minutes"],
- },
- },
- "message_chatgpt": {
- "name": "message_chatgpt",
- "description": "Send a message to a more basic AI, ChatGPT. A useful resource for asking questions. ChatGPT does not retain memory of previous interactions.",
- "parameters": {
- "type": "object",
- "properties": {
- # https://json-schema.org/understanding-json-schema/reference/array.html
- "message": {
- "type": "string",
- "description": "Message to send ChatGPT. Phrase your message as a full English sentence.",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["message", "request_heartbeat"],
- },
- },
- "core_memory_append": {
- "name": "core_memory_append",
- "description": "Append to the contents of core memory.",
- "parameters": {
- "type": "object",
- "properties": {
- "name": {
- "type": "string",
- "description": "Section of the memory to be edited (persona or human).",
- },
- "content": {
- "type": "string",
- "description": "Content to write to the memory. All unicode (including emojis) are supported.",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["name", "content", "request_heartbeat"],
- },
- },
- "core_memory_replace": {
- "name": "core_memory_replace",
- "description": "Replace the contents of core memory. To delete memories, use an empty string for new_content.",
- "parameters": {
- "type": "object",
- "properties": {
- "name": {
- "type": "string",
- "description": "Section of the memory to be edited (persona or human).",
- },
- "old_content": {
- "type": "string",
- "description": "String to replace. Must be an exact match.",
- },
- "new_content": {
- "type": "string",
- "description": "Content to write to the memory. All unicode (including emojis) are supported.",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["name", "old_content", "new_content", "request_heartbeat"],
- },
- },
- "recall_memory_search": {
- "name": "recall_memory_search",
- "description": "Search prior conversation history using a string.",
- "parameters": {
- "type": "object",
- "properties": {
- "query": {
- "type": "string",
- "description": "String to search for.",
- },
- "page": {
- "type": "integer",
- "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["query", "page", "request_heartbeat"],
- },
- },
- "conversation_search": {
- "name": "conversation_search",
- "description": "Search prior conversation history using case-insensitive string matching.",
- "parameters": {
- "type": "object",
- "properties": {
- "query": {
- "type": "string",
- "description": "String to search for.",
- },
- "page": {
- "type": "integer",
- "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["query", "request_heartbeat"],
- },
- },
- "recall_memory_search_date": {
- "name": "recall_memory_search_date",
- "description": "Search prior conversation history using a date range.",
- "parameters": {
- "type": "object",
- "properties": {
- "start_date": {
- "type": "string",
- "description": "The start of the date range to search, in the format 'YYYY-MM-DD'.",
- },
- "end_date": {
- "type": "string",
- "description": "The end of the date range to search, in the format 'YYYY-MM-DD'.",
- },
- "page": {
- "type": "integer",
- "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["start_date", "end_date", "page", "request_heartbeat"],
- },
- },
- "conversation_search_date": {
- "name": "conversation_search_date",
- "description": "Search prior conversation history using a date range.",
- "parameters": {
- "type": "object",
- "properties": {
- "start_date": {
- "type": "string",
- "description": "The start of the date range to search, in the format 'YYYY-MM-DD'.",
- },
- "end_date": {
- "type": "string",
- "description": "The end of the date range to search, in the format 'YYYY-MM-DD'.",
- },
- "page": {
- "type": "integer",
- "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["start_date", "end_date", "request_heartbeat"],
- },
- },
- "archival_memory_insert": {
- "name": "archival_memory_insert",
- "description": "Add to archival memory. Make sure to phrase the memory contents such that it can be easily queried later.",
- "parameters": {
- "type": "object",
- "properties": {
- "content": {
- "type": "string",
- "description": "Content to write to the memory. All unicode (including emojis) are supported.",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["content", "request_heartbeat"],
- },
- },
- "archival_memory_search": {
- "name": "archival_memory_search",
- "description": "Search archival memory using semantic (embedding-based) search.",
- "parameters": {
- "type": "object",
- "properties": {
- "query": {
- "type": "string",
- "description": "String to search for.",
- },
- "page": {
- "type": "integer",
- "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["query", "request_heartbeat"],
- },
- },
- "read_from_text_file": {
- "name": "read_from_text_file",
- "description": "Read lines from a text file.",
- "parameters": {
- "type": "object",
- "properties": {
- "filename": {
- "type": "string",
- "description": "The name of the file to read.",
- },
- "line_start": {
- "type": "integer",
- "description": "Line to start reading from.",
- },
- "num_lines": {
- "type": "integer",
- "description": "How many lines to read (defaults to 1).",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["filename", "line_start", "request_heartbeat"],
- },
- },
- "append_to_text_file": {
- "name": "append_to_text_file",
- "description": "Append to a text file.",
- "parameters": {
- "type": "object",
- "properties": {
- "filename": {
- "type": "string",
- "description": "The name of the file to append to.",
- },
- "content": {
- "type": "string",
- "description": "Content to append to the file.",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["filename", "content", "request_heartbeat"],
- },
- },
- "http_request": {
- "name": "http_request",
- "description": "Generates an HTTP request and returns the response.",
- "parameters": {
- "type": "object",
- "properties": {
- "method": {
- "type": "string",
- "description": "The HTTP method (e.g., 'GET', 'POST').",
- },
- "url": {
- "type": "string",
- "description": "The URL for the request.",
- },
- "payload_json": {
- "type": "string",
- "description": "A JSON string representing the request payload.",
- },
- "request_heartbeat": {
- "type": "boolean",
- "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
- },
- },
- "required": ["method", "url", "request_heartbeat"],
- },
- },
-}
+from ..constants import FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT, MAX_PAUSE_HEARTBEATS
+
+# FUNCTIONS_PROMPT_MULTISTEP_NO_HEARTBEATS = FUNCTIONS_PROMPT_MULTISTEP[:-1]
+FUNCTIONS_CHAINING = {
+ "send_message": {
+ "name": "send_message",
+ "description": "Sends a message to the human user.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ # https://json-schema.org/understanding-json-schema/reference/array.html
+ "message": {
+ "type": "string",
+ "description": "Message contents. All unicode (including emojis) are supported.",
+ },
+ },
+ "required": ["message"],
+ },
+ },
+ "pause_heartbeats": {
+ "name": "pause_heartbeats",
+ "description": "Temporarily ignore timed heartbeats. You may still receive messages from manual heartbeats and other events.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ # https://json-schema.org/understanding-json-schema/reference/array.html
+ "minutes": {
+ "type": "integer",
+ "description": f"Number of minutes to ignore heartbeats for. Max value of {MAX_PAUSE_HEARTBEATS} minutes ({MAX_PAUSE_HEARTBEATS//60} hours).",
+ },
+ },
+ "required": ["minutes"],
+ },
+ },
+ "message_chatgpt": {
+ "name": "message_chatgpt",
+ "description": "Send a message to a more basic AI, ChatGPT. A useful resource for asking questions. ChatGPT does not retain memory of previous interactions.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ # https://json-schema.org/understanding-json-schema/reference/array.html
+ "message": {
+ "type": "string",
+ "description": "Message to send ChatGPT. Phrase your message as a full English sentence.",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["message", "request_heartbeat"],
+ },
+ },
+ "core_memory_append": {
+ "name": "core_memory_append",
+ "description": "Append to the contents of core memory.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "name": {
+ "type": "string",
+ "description": "Section of the memory to be edited (persona or human).",
+ },
+ "content": {
+ "type": "string",
+ "description": "Content to write to the memory. All unicode (including emojis) are supported.",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["name", "content", "request_heartbeat"],
+ },
+ },
+ "core_memory_replace": {
+ "name": "core_memory_replace",
+ "description": "Replace the contents of core memory. To delete memories, use an empty string for new_content.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "name": {
+ "type": "string",
+ "description": "Section of the memory to be edited (persona or human).",
+ },
+ "old_content": {
+ "type": "string",
+ "description": "String to replace. Must be an exact match.",
+ },
+ "new_content": {
+ "type": "string",
+ "description": "Content to write to the memory. All unicode (including emojis) are supported.",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["name", "old_content", "new_content", "request_heartbeat"],
+ },
+ },
+ "recall_memory_search": {
+ "name": "recall_memory_search",
+ "description": "Search prior conversation history using a string.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "query": {
+ "type": "string",
+ "description": "String to search for.",
+ },
+ "page": {
+ "type": "integer",
+ "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["query", "page", "request_heartbeat"],
+ },
+ },
+ "conversation_search": {
+ "name": "conversation_search",
+ "description": "Search prior conversation history using case-insensitive string matching.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "query": {
+ "type": "string",
+ "description": "String to search for.",
+ },
+ "page": {
+ "type": "integer",
+ "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["query", "request_heartbeat"],
+ },
+ },
+ "recall_memory_search_date": {
+ "name": "recall_memory_search_date",
+ "description": "Search prior conversation history using a date range.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "start_date": {
+ "type": "string",
+ "description": "The start of the date range to search, in the format 'YYYY-MM-DD'.",
+ },
+ "end_date": {
+ "type": "string",
+ "description": "The end of the date range to search, in the format 'YYYY-MM-DD'.",
+ },
+ "page": {
+ "type": "integer",
+ "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["start_date", "end_date", "page", "request_heartbeat"],
+ },
+ },
+ "conversation_search_date": {
+ "name": "conversation_search_date",
+ "description": "Search prior conversation history using a date range.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "start_date": {
+ "type": "string",
+ "description": "The start of the date range to search, in the format 'YYYY-MM-DD'.",
+ },
+ "end_date": {
+ "type": "string",
+ "description": "The end of the date range to search, in the format 'YYYY-MM-DD'.",
+ },
+ "page": {
+ "type": "integer",
+ "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["start_date", "end_date", "request_heartbeat"],
+ },
+ },
+ "archival_memory_insert": {
+ "name": "archival_memory_insert",
+ "description": "Add to archival memory. Make sure to phrase the memory contents such that it can be easily queried later.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "content": {
+ "type": "string",
+ "description": "Content to write to the memory. All unicode (including emojis) are supported.",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["content", "request_heartbeat"],
+ },
+ },
+ "archival_memory_search": {
+ "name": "archival_memory_search",
+ "description": "Search archival memory using semantic (embedding-based) search.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "query": {
+ "type": "string",
+ "description": "String to search for.",
+ },
+ "page": {
+ "type": "integer",
+ "description": "Allows you to page through results. Only use on a follow-up query. Defaults to 0 (first page).",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["query", "request_heartbeat"],
+ },
+ },
+ "read_from_text_file": {
+ "name": "read_from_text_file",
+ "description": "Read lines from a text file.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "filename": {
+ "type": "string",
+ "description": "The name of the file to read.",
+ },
+ "line_start": {
+ "type": "integer",
+ "description": "Line to start reading from.",
+ },
+ "num_lines": {
+ "type": "integer",
+ "description": "How many lines to read (defaults to 1).",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["filename", "line_start", "request_heartbeat"],
+ },
+ },
+ "append_to_text_file": {
+ "name": "append_to_text_file",
+ "description": "Append to a text file.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "filename": {
+ "type": "string",
+ "description": "The name of the file to append to.",
+ },
+ "content": {
+ "type": "string",
+ "description": "Content to append to the file.",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["filename", "content", "request_heartbeat"],
+ },
+ },
+ "http_request": {
+ "name": "http_request",
+ "description": "Generates an HTTP request and returns the response.",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "method": {
+ "type": "string",
+ "description": "The HTTP method (e.g., 'GET', 'POST').",
+ },
+ "url": {
+ "type": "string",
+ "description": "The URL for the request.",
+ },
+ "payload_json": {
+ "type": "string",
+ "description": "A JSON string representing the request payload.",
+ },
+ "request_heartbeat": {
+ "type": "boolean",
+ "description": FUNCTION_PARAM_DESCRIPTION_REQ_HEARTBEAT,
+ },
+ },
+ "required": ["method", "url", "request_heartbeat"],
+ },
+ },
+}
diff --git a/memgpt/prompts/gpt_summarize.py b/memgpt/prompts/gpt_summarize.py
index 95c0e199..945268de 100644
--- a/memgpt/prompts/gpt_summarize.py
+++ b/memgpt/prompts/gpt_summarize.py
@@ -1,14 +1,14 @@
-WORD_LIMIT = 100
-SYSTEM = f"""
-Your job is to summarize a history of previous messages in a conversation between an AI persona and a human.
-The conversation you are given is a from a fixed context window and may not be complete.
-Messages sent by the AI are marked with the 'assistant' role.
-The AI 'assistant' can also make calls to functions, whose outputs can be seen in messages with the 'function' role.
-Things the AI says in the message content are considered inner monologue and are not seen by the user.
-The only AI messages seen by the user are from when the AI uses 'send_message'.
-Messages the user sends are in the 'user' role.
-The 'user' role is also used for important system events, such as login events and heartbeat events (heartbeats run the AI's program without user action, allowing the AI to act without prompting from the user sending them a message).
-Summarize what happened in the conversation from the perspective of the AI (use the first person).
-Keep your summary less than {WORD_LIMIT} words, do NOT exceed this word limit.
-Only output the summary, do NOT include anything else in your output.
-"""
+WORD_LIMIT = 100
+SYSTEM = f"""
+Your job is to summarize a history of previous messages in a conversation between an AI persona and a human.
+The conversation you are given is a from a fixed context window and may not be complete.
+Messages sent by the AI are marked with the 'assistant' role.
+The AI 'assistant' can also make calls to functions, whose outputs can be seen in messages with the 'function' role.
+Things the AI says in the message content are considered inner monologue and are not seen by the user.
+The only AI messages seen by the user are from when the AI uses 'send_message'.
+Messages the user sends are in the 'user' role.
+The 'user' role is also used for important system events, such as login events and heartbeat events (heartbeats run the AI's program without user action, allowing the AI to act without prompting from the user sending them a message).
+Summarize what happened in the conversation from the perspective of the AI (use the first person).
+Keep your summary less than {WORD_LIMIT} words, do NOT exceed this word limit.
+Only output the summary, do NOT include anything else in your output.
+"""
diff --git a/memgpt/prompts/gpt_system.py b/memgpt/prompts/gpt_system.py
index 9cde4495..214a416a 100644
--- a/memgpt/prompts/gpt_system.py
+++ b/memgpt/prompts/gpt_system.py
@@ -1,26 +1,26 @@
-import os
-
-from memgpt.constants import MEMGPT_DIR
-
-
-def get_system_text(key):
- filename = f"{key}.txt"
- file_path = os.path.join(os.path.dirname(__file__), "system", filename)
-
- # first look in prompts/system/*.txt
- if os.path.exists(file_path):
- with open(file_path, "r", encoding="utf-8") as file:
- return file.read().strip()
- else:
- # try looking in ~/.memgpt/system_prompts/*.txt
- user_system_prompts_dir = os.path.join(MEMGPT_DIR, "system_prompts")
- # create directory if it doesn't exist
- if not os.path.exists(user_system_prompts_dir):
- os.makedirs(user_system_prompts_dir)
- # look inside for a matching system prompt
- file_path = os.path.join(user_system_prompts_dir, filename)
- if os.path.exists(file_path):
- with open(file_path, "r", encoding="utf-8") as file:
- return file.read().strip()
- else:
- raise FileNotFoundError(f"No file found for key {key}, path={file_path}")
+import os
+
+from memgpt.constants import MEMGPT_DIR
+
+
+def get_system_text(key):
+ filename = f"{key}.txt"
+ file_path = os.path.join(os.path.dirname(__file__), "system", filename)
+
+ # first look in prompts/system/*.txt
+ if os.path.exists(file_path):
+ with open(file_path, "r", encoding="utf-8") as file:
+ return file.read().strip()
+ else:
+ # try looking in ~/.memgpt/system_prompts/*.txt
+ user_system_prompts_dir = os.path.join(MEMGPT_DIR, "system_prompts")
+ # create directory if it doesn't exist
+ if not os.path.exists(user_system_prompts_dir):
+ os.makedirs(user_system_prompts_dir)
+ # look inside for a matching system prompt
+ file_path = os.path.join(user_system_prompts_dir, filename)
+ if os.path.exists(file_path):
+ with open(file_path, "r", encoding="utf-8") as file:
+ return file.read().strip()
+ else:
+ raise FileNotFoundError(f"No file found for key {key}, path={file_path}")
diff --git a/memgpt/system.py b/memgpt/system.py
index 97d3b199..dcfefdca 100644
--- a/memgpt/system.py
+++ b/memgpt/system.py
@@ -1,208 +1,208 @@
-import json
-import uuid
-from typing import Optional
-
-from .constants import (
- INITIAL_BOOT_MESSAGE,
- INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG,
- INITIAL_BOOT_MESSAGE_SEND_MESSAGE_THOUGHT,
- JSON_ENSURE_ASCII,
- MESSAGE_SUMMARY_WARNING_STR,
-)
-from .utils import get_local_time
-
-
-def get_initial_boot_messages(version="startup"):
- if version == "startup":
- initial_boot_message = INITIAL_BOOT_MESSAGE
- messages = [
- {"role": "assistant", "content": initial_boot_message},
- ]
-
- elif version == "startup_with_send_message":
- tool_call_id = str(uuid.uuid4())
- messages = [
- # first message includes both inner monologue and function call to send_message
- {
- "role": "assistant",
- "content": INITIAL_BOOT_MESSAGE_SEND_MESSAGE_THOUGHT,
- # "function_call": {
- # "name": "send_message",
- # "arguments": '{\n "message": "' + f"{INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG}" + '"\n}',
- # },
- "tool_calls": [
- {
- "id": tool_call_id,
- "type": "function",
- "function": {
- "name": "send_message",
- "arguments": '{\n "message": "' + f"{INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG}" + '"\n}',
- },
- }
- ],
- },
- # obligatory function return message
- {
- # "role": "function",
- "role": "tool",
- "name": "send_message", # NOTE: technically not up to spec, this is old functions style
- "content": package_function_response(True, None),
- "tool_call_id": tool_call_id,
- },
- ]
-
- elif version == "startup_with_send_message_gpt35":
- tool_call_id = str(uuid.uuid4())
- messages = [
- # first message includes both inner monologue and function call to send_message
- {
- "role": "assistant",
- "content": "*inner thoughts* Still waiting on the user. Sending a message with function.",
- # "function_call": {"name": "send_message", "arguments": '{\n "message": "' + f"Hi, is anyone there?" + '"\n}'},
- "tool_calls": [
- {
- "id": tool_call_id,
- "type": "function",
- "function": {
- "name": "send_message",
- "arguments": '{\n "message": "' + f"Hi, is anyone there?" + '"\n}',
- },
- }
- ],
- },
- # obligatory function return message
- {
- # "role": "function",
- "role": "tool",
- "name": "send_message",
- "content": package_function_response(True, None),
- "tool_call_id": tool_call_id,
- },
- ]
-
- else:
- raise ValueError(version)
-
- return messages
-
-
-def get_heartbeat(reason="Automated timer", include_location=False, location_name="San Francisco, CA, USA"):
- # Package the message with time and location
- formatted_time = get_local_time()
- packaged_message = {
- "type": "heartbeat",
- "reason": reason,
- "time": formatted_time,
- }
-
- if include_location:
- packaged_message["location"] = location_name
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
-
-
-def get_login_event(last_login="Never (first login)", include_location=False, location_name="San Francisco, CA, USA"):
- # Package the message with time and location
- formatted_time = get_local_time()
- packaged_message = {
- "type": "login",
- "last_login": last_login,
- "time": formatted_time,
- }
-
- if include_location:
- packaged_message["location"] = location_name
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
-
-
-def package_user_message(
- user_message: str,
- time: Optional[str] = None,
- include_location: bool = False,
- location_name: Optional[str] = "San Francisco, CA, USA",
- name: Optional[str] = None,
-):
- # Package the message with time and location
- formatted_time = time if time else get_local_time()
- packaged_message = {
- "type": "user_message",
- "message": user_message,
- "time": formatted_time,
- }
-
- if include_location:
- packaged_message["location"] = location_name
-
- if name:
- packaged_message["name"] = name
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
-
-
-def package_function_response(was_success, response_string, timestamp=None):
- formatted_time = get_local_time() if timestamp is None else timestamp
- packaged_message = {
- "status": "OK" if was_success else "Failed",
- "message": response_string,
- "time": formatted_time,
- }
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
-
-
-def package_system_message(system_message, message_type="system_alert", time=None):
- formatted_time = time if time else get_local_time()
- packaged_message = {
- "type": message_type,
- "message": system_message,
- "time": formatted_time,
- }
-
- return json.dumps(packaged_message)
-
-
-def package_summarize_message(summary, summary_length, hidden_message_count, total_message_count, timestamp=None):
- context_message = (
- f"Note: prior messages ({hidden_message_count} of {total_message_count} total messages) have been hidden from view due to conversation memory constraints.\n"
- + f"The following is a summary of the previous {summary_length} messages:\n {summary}"
- )
-
- formatted_time = get_local_time() if timestamp is None else timestamp
- packaged_message = {
- "type": "system_alert",
- "message": context_message,
- "time": formatted_time,
- }
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
-
-
-def package_summarize_message_no_summary(hidden_message_count, timestamp=None, message=None):
- """Add useful metadata to the summary message"""
-
- # Package the message with time and location
- formatted_time = get_local_time() if timestamp is None else timestamp
- context_message = (
- message
- if message
- else f"Note: {hidden_message_count} prior messages with the user have been hidden from view due to conversation memory constraints. Older messages are stored in Recall Memory and can be viewed using functions."
- )
- packaged_message = {
- "type": "system_alert",
- "message": context_message,
- "time": formatted_time,
- }
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
-
-
-def get_token_limit_warning():
- formatted_time = get_local_time()
- packaged_message = {
- "type": "system_alert",
- "message": MESSAGE_SUMMARY_WARNING_STR,
- "time": formatted_time,
- }
-
- return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+import json
+import uuid
+from typing import Optional
+
+from .constants import (
+ INITIAL_BOOT_MESSAGE,
+ INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG,
+ INITIAL_BOOT_MESSAGE_SEND_MESSAGE_THOUGHT,
+ JSON_ENSURE_ASCII,
+ MESSAGE_SUMMARY_WARNING_STR,
+)
+from .utils import get_local_time
+
+
+def get_initial_boot_messages(version="startup"):
+ if version == "startup":
+ initial_boot_message = INITIAL_BOOT_MESSAGE
+ messages = [
+ {"role": "assistant", "content": initial_boot_message},
+ ]
+
+ elif version == "startup_with_send_message":
+ tool_call_id = str(uuid.uuid4())
+ messages = [
+ # first message includes both inner monologue and function call to send_message
+ {
+ "role": "assistant",
+ "content": INITIAL_BOOT_MESSAGE_SEND_MESSAGE_THOUGHT,
+ # "function_call": {
+ # "name": "send_message",
+ # "arguments": '{\n "message": "' + f"{INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG}" + '"\n}',
+ # },
+ "tool_calls": [
+ {
+ "id": tool_call_id,
+ "type": "function",
+ "function": {
+ "name": "send_message",
+ "arguments": '{\n "message": "' + f"{INITIAL_BOOT_MESSAGE_SEND_MESSAGE_FIRST_MSG}" + '"\n}',
+ },
+ }
+ ],
+ },
+ # obligatory function return message
+ {
+ # "role": "function",
+ "role": "tool",
+ "name": "send_message", # NOTE: technically not up to spec, this is old functions style
+ "content": package_function_response(True, None),
+ "tool_call_id": tool_call_id,
+ },
+ ]
+
+ elif version == "startup_with_send_message_gpt35":
+ tool_call_id = str(uuid.uuid4())
+ messages = [
+ # first message includes both inner monologue and function call to send_message
+ {
+ "role": "assistant",
+ "content": "*inner thoughts* Still waiting on the user. Sending a message with function.",
+ # "function_call": {"name": "send_message", "arguments": '{\n "message": "' + f"Hi, is anyone there?" + '"\n}'},
+ "tool_calls": [
+ {
+ "id": tool_call_id,
+ "type": "function",
+ "function": {
+ "name": "send_message",
+ "arguments": '{\n "message": "' + f"Hi, is anyone there?" + '"\n}',
+ },
+ }
+ ],
+ },
+ # obligatory function return message
+ {
+ # "role": "function",
+ "role": "tool",
+ "name": "send_message",
+ "content": package_function_response(True, None),
+ "tool_call_id": tool_call_id,
+ },
+ ]
+
+ else:
+ raise ValueError(version)
+
+ return messages
+
+
+def get_heartbeat(reason="Automated timer", include_location=False, location_name="San Francisco, CA, USA"):
+ # Package the message with time and location
+ formatted_time = get_local_time()
+ packaged_message = {
+ "type": "heartbeat",
+ "reason": reason,
+ "time": formatted_time,
+ }
+
+ if include_location:
+ packaged_message["location"] = location_name
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+
+
+def get_login_event(last_login="Never (first login)", include_location=False, location_name="San Francisco, CA, USA"):
+ # Package the message with time and location
+ formatted_time = get_local_time()
+ packaged_message = {
+ "type": "login",
+ "last_login": last_login,
+ "time": formatted_time,
+ }
+
+ if include_location:
+ packaged_message["location"] = location_name
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+
+
+def package_user_message(
+ user_message: str,
+ time: Optional[str] = None,
+ include_location: bool = False,
+ location_name: Optional[str] = "San Francisco, CA, USA",
+ name: Optional[str] = None,
+):
+ # Package the message with time and location
+ formatted_time = time if time else get_local_time()
+ packaged_message = {
+ "type": "user_message",
+ "message": user_message,
+ "time": formatted_time,
+ }
+
+ if include_location:
+ packaged_message["location"] = location_name
+
+ if name:
+ packaged_message["name"] = name
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+
+
+def package_function_response(was_success, response_string, timestamp=None):
+ formatted_time = get_local_time() if timestamp is None else timestamp
+ packaged_message = {
+ "status": "OK" if was_success else "Failed",
+ "message": response_string,
+ "time": formatted_time,
+ }
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+
+
+def package_system_message(system_message, message_type="system_alert", time=None):
+ formatted_time = time if time else get_local_time()
+ packaged_message = {
+ "type": message_type,
+ "message": system_message,
+ "time": formatted_time,
+ }
+
+ return json.dumps(packaged_message)
+
+
+def package_summarize_message(summary, summary_length, hidden_message_count, total_message_count, timestamp=None):
+ context_message = (
+ f"Note: prior messages ({hidden_message_count} of {total_message_count} total messages) have been hidden from view due to conversation memory constraints.\n"
+ + f"The following is a summary of the previous {summary_length} messages:\n {summary}"
+ )
+
+ formatted_time = get_local_time() if timestamp is None else timestamp
+ packaged_message = {
+ "type": "system_alert",
+ "message": context_message,
+ "time": formatted_time,
+ }
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+
+
+def package_summarize_message_no_summary(hidden_message_count, timestamp=None, message=None):
+ """Add useful metadata to the summary message"""
+
+ # Package the message with time and location
+ formatted_time = get_local_time() if timestamp is None else timestamp
+ context_message = (
+ message
+ if message
+ else f"Note: {hidden_message_count} prior messages with the user have been hidden from view due to conversation memory constraints. Older messages are stored in Recall Memory and can be viewed using functions."
+ )
+ packaged_message = {
+ "type": "system_alert",
+ "message": context_message,
+ "time": formatted_time,
+ }
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
+
+
+def get_token_limit_warning():
+ formatted_time = get_local_time()
+ packaged_message = {
+ "type": "system_alert",
+ "message": MESSAGE_SUMMARY_WARNING_STR,
+ "time": formatted_time,
+ }
+
+ return json.dumps(packaged_message, ensure_ascii=JSON_ENSURE_ASCII)
diff --git a/memgpt/utils.py b/memgpt/utils.py
index 1ff2c508..13efd521 100644
--- a/memgpt/utils.py
+++ b/memgpt/utils.py
@@ -1,1047 +1,1047 @@
-import copy
-import difflib
-import hashlib
-import inspect
-import io
-import json
-import os
-import pickle
-import platform
-import random
-import re
-import subprocess
-import sys
-import uuid
-from contextlib import contextmanager
-from datetime import datetime, timedelta, timezone
-from functools import wraps
-from typing import List, Union, _GenericAlias, get_type_hints
-from urllib.parse import urljoin, urlparse
-
-import demjson3 as demjson
-import pytz
-import tiktoken
-
-import memgpt
-from memgpt.constants import (
- CLI_WARNING_PREFIX,
- CORE_MEMORY_HUMAN_CHAR_LIMIT,
- CORE_MEMORY_PERSONA_CHAR_LIMIT,
- FUNCTION_RETURN_CHAR_LIMIT,
- JSON_ENSURE_ASCII,
- JSON_LOADS_STRICT,
- MEMGPT_DIR,
- TOOL_CALL_ID_MAX_LEN,
-)
-from memgpt.models.chat_completion_response import ChatCompletionResponse
-from memgpt.openai_backcompat.openai_object import OpenAIObject
-
-DEBUG = False
-if "LOG_LEVEL" in os.environ:
- if os.environ["LOG_LEVEL"] == "DEBUG":
- DEBUG = True
-
-
-ADJECTIVE_BANK = [
- "beautiful",
- "gentle",
- "angry",
- "vivacious",
- "grumpy",
- "luxurious",
- "fierce",
- "delicate",
- "fluffy",
- "radiant",
- "elated",
- "magnificent",
- "sassy",
- "ecstatic",
- "lustrous",
- "gleaming",
- "sorrowful",
- "majestic",
- "proud",
- "dynamic",
- "energetic",
- "mysterious",
- "loyal",
- "brave",
- "decisive",
- "frosty",
- "cheerful",
- "adorable",
- "melancholy",
- "vibrant",
- "elegant",
- "gracious",
- "inquisitive",
- "opulent",
- "peaceful",
- "rebellious",
- "scintillating",
- "dazzling",
- "whimsical",
- "impeccable",
- "meticulous",
- "resilient",
- "charming",
- "vivacious",
- "creative",
- "intuitive",
- "compassionate",
- "innovative",
- "enthusiastic",
- "tremendous",
- "effervescent",
- "tenacious",
- "fearless",
- "sophisticated",
- "witty",
- "optimistic",
- "exquisite",
- "sincere",
- "generous",
- "kindhearted",
- "serene",
- "amiable",
- "adventurous",
- "bountiful",
- "courageous",
- "diligent",
- "exotic",
- "grateful",
- "harmonious",
- "imaginative",
- "jubilant",
- "keen",
- "luminous",
- "nurturing",
- "outgoing",
- "passionate",
- "quaint",
- "resourceful",
- "sturdy",
- "tactful",
- "unassuming",
- "versatile",
- "wondrous",
- "youthful",
- "zealous",
- "ardent",
- "benevolent",
- "capricious",
- "dedicated",
- "empathetic",
- "fabulous",
- "gregarious",
- "humble",
- "intriguing",
- "jovial",
- "kind",
- "lovable",
- "mindful",
- "noble",
- "original",
- "pleasant",
- "quixotic",
- "reliable",
- "spirited",
- "tranquil",
- "unique",
- "venerable",
- "warmhearted",
- "xenodochial",
- "yearning",
- "zesty",
- "amusing",
- "blissful",
- "calm",
- "daring",
- "enthusiastic",
- "faithful",
- "graceful",
- "honest",
- "incredible",
- "joyful",
- "kind",
- "lovely",
- "merry",
- "noble",
- "optimistic",
- "peaceful",
- "quirky",
- "respectful",
- "sweet",
- "trustworthy",
- "understanding",
- "vibrant",
- "witty",
- "xenial",
- "youthful",
- "zealous",
- "ambitious",
- "brilliant",
- "careful",
- "devoted",
- "energetic",
- "friendly",
- "glorious",
- "humorous",
- "intelligent",
- "jovial",
- "knowledgeable",
- "loyal",
- "modest",
- "nice",
- "obedient",
- "patient",
- "quiet",
- "resilient",
- "selfless",
- "tolerant",
- "unique",
- "versatile",
- "warm",
- "xerothermic",
- "yielding",
- "zestful",
- "amazing",
- "bold",
- "charming",
- "determined",
- "exciting",
- "funny",
- "happy",
- "imaginative",
- "jolly",
- "keen",
- "loving",
- "magnificent",
- "nifty",
- "outstanding",
- "polite",
- "quick",
- "reliable",
- "sincere",
- "thoughtful",
- "unusual",
- "valuable",
- "wonderful",
- "xenodochial",
- "zealful",
- "admirable",
- "bright",
- "clever",
- "dedicated",
- "extraordinary",
- "generous",
- "hardworking",
- "inspiring",
- "jubilant",
- "kindhearted",
- "lively",
- "miraculous",
- "neat",
- "openminded",
- "passionate",
- "remarkable",
- "stunning",
- "truthful",
- "upbeat",
- "vivacious",
- "welcoming",
- "yare",
- "zealous",
-]
-
-NOUN_BANK = [
- "lizard",
- "firefighter",
- "banana",
- "castle",
- "dolphin",
- "elephant",
- "forest",
- "giraffe",
- "harbor",
- "iceberg",
- "jewelry",
- "kangaroo",
- "library",
- "mountain",
- "notebook",
- "orchard",
- "penguin",
- "quilt",
- "rainbow",
- "squirrel",
- "teapot",
- "umbrella",
- "volcano",
- "waterfall",
- "xylophone",
- "yacht",
- "zebra",
- "apple",
- "butterfly",
- "caterpillar",
- "dragonfly",
- "elephant",
- "flamingo",
- "gorilla",
- "hippopotamus",
- "iguana",
- "jellyfish",
- "koala",
- "lemur",
- "mongoose",
- "nighthawk",
- "octopus",
- "panda",
- "quokka",
- "rhinoceros",
- "salamander",
- "tortoise",
- "unicorn",
- "vulture",
- "walrus",
- "xenopus",
- "yak",
- "zebu",
- "asteroid",
- "balloon",
- "compass",
- "dinosaur",
- "eagle",
- "firefly",
- "galaxy",
- "hedgehog",
- "island",
- "jaguar",
- "kettle",
- "lion",
- "mammoth",
- "nucleus",
- "owl",
- "pumpkin",
- "quasar",
- "reindeer",
- "snail",
- "tiger",
- "universe",
- "vampire",
- "wombat",
- "xerus",
- "yellowhammer",
- "zeppelin",
- "alligator",
- "buffalo",
- "cactus",
- "donkey",
- "emerald",
- "falcon",
- "gazelle",
- "hamster",
- "icicle",
- "jackal",
- "kitten",
- "leopard",
- "mushroom",
- "narwhal",
- "opossum",
- "peacock",
- "quail",
- "rabbit",
- "scorpion",
- "toucan",
- "urchin",
- "viper",
- "wolf",
- "xray",
- "yucca",
- "zebu",
- "acorn",
- "biscuit",
- "cupcake",
- "daisy",
- "eyeglasses",
- "frisbee",
- "goblin",
- "hamburger",
- "icicle",
- "jackfruit",
- "kaleidoscope",
- "lighthouse",
- "marshmallow",
- "nectarine",
- "obelisk",
- "pancake",
- "quicksand",
- "raspberry",
- "spinach",
- "truffle",
- "umbrella",
- "volleyball",
- "walnut",
- "xylophonist",
- "yogurt",
- "zucchini",
- "asterisk",
- "blackberry",
- "chimpanzee",
- "dumpling",
- "espresso",
- "fireplace",
- "gnome",
- "hedgehog",
- "illustration",
- "jackhammer",
- "kumquat",
- "lemongrass",
- "mandolin",
- "nugget",
- "ostrich",
- "parakeet",
- "quiche",
- "racquet",
- "seashell",
- "tadpole",
- "unicorn",
- "vaccination",
- "wolverine",
- "xenophobia",
- "yam",
- "zeppelin",
- "accordion",
- "broccoli",
- "carousel",
- "daffodil",
- "eggplant",
- "flamingo",
- "grapefruit",
- "harpsichord",
- "impression",
- "jackrabbit",
- "kitten",
- "llama",
- "mandarin",
- "nachos",
- "obelisk",
- "papaya",
- "quokka",
- "rooster",
- "sunflower",
- "turnip",
- "ukulele",
- "viper",
- "waffle",
- "xylograph",
- "yeti",
- "zephyr",
- "abacus",
- "blueberry",
- "crocodile",
- "dandelion",
- "echidna",
- "fig",
- "giraffe",
- "hamster",
- "iguana",
- "jackal",
- "kiwi",
- "lobster",
- "marmot",
- "noodle",
- "octopus",
- "platypus",
- "quail",
- "raccoon",
- "starfish",
- "tulip",
- "urchin",
- "vampire",
- "walrus",
- "xylophone",
- "yak",
- "zebra",
-]
-
-
-def smart_urljoin(base_url: str, relative_url: str) -> str:
- """urljoin is stupid and wants a trailing / at the end of the endpoint address, or it will chop the suffix off"""
- if not base_url.endswith("/"):
- base_url += "/"
- return urljoin(base_url, relative_url)
-
-
-def is_utc_datetime(dt: datetime) -> bool:
- return dt.tzinfo is not None and dt.tzinfo.utcoffset(dt) == timedelta(0)
-
-
-def get_tool_call_id() -> str:
- return str(uuid.uuid4())[:TOOL_CALL_ID_MAX_LEN]
-
-
-def assistant_function_to_tool(assistant_message: dict) -> dict:
- assert "function_call" in assistant_message
- new_msg = copy.deepcopy(assistant_message)
- function_call = new_msg.pop("function_call")
- new_msg["tool_calls"] = [
- {
- "id": get_tool_call_id(),
- "type": "function",
- "function": function_call,
- }
- ]
- return new_msg
-
-
-def is_optional_type(hint):
- """Check if the type hint is an Optional type."""
- if isinstance(hint, _GenericAlias):
- return hint.__origin__ is Union and type(None) in hint.__args__
- return False
-
-
-def enforce_types(func):
- @wraps(func)
- def wrapper(*args, **kwargs):
- # Get type hints, excluding the return type hint
- hints = {k: v for k, v in get_type_hints(func).items() if k != "return"}
-
- # Get the function's argument names
- arg_names = inspect.getfullargspec(func).args
-
- # Pair each argument with its corresponding type hint
- args_with_hints = dict(zip(arg_names[1:], args[1:])) # Skipping 'self'
-
- # Check types of arguments
- for arg_name, arg_value in args_with_hints.items():
- hint = hints.get(arg_name)
- if hint and not isinstance(arg_value, hint) and not (is_optional_type(hint) and arg_value is None):
- raise ValueError(f"Argument {arg_name} does not match type {hint}")
-
- # Check types of keyword arguments
- for arg_name, arg_value in kwargs.items():
- hint = hints.get(arg_name)
- if hint and not isinstance(arg_value, hint) and not (is_optional_type(hint) and arg_value is None):
- raise ValueError(f"Argument {arg_name} does not match type {hint}")
-
- return func(*args, **kwargs)
-
- return wrapper
-
-
-def annotate_message_json_list_with_tool_calls(messages: List[dict], allow_tool_roles: bool = False):
- """Add in missing tool_call_id fields to a list of messages using function call style
-
- Walk through the list forwards:
- - If we encounter an assistant message that calls a function ("function_call") but doesn't have a "tool_call_id" field
- - Generate the tool_call_id
- - Then check if the subsequent message is a role == "function" message
- - If so, then att
- """
- tool_call_index = None
- tool_call_id = None
- updated_messages = []
-
- for i, message in enumerate(messages):
- if "role" not in message:
- raise ValueError(f"message missing 'role' field:\n{message}")
-
- # If we find a function call w/o a tool call ID annotation, annotate it
- if message["role"] == "assistant" and "function_call" in message:
- if "tool_call_id" in message and message["tool_call_id"] is not None:
- printd(f"Message already has tool_call_id")
- tool_call_id = message["tool_call_id"]
- else:
- tool_call_id = str(uuid.uuid4())
- message["tool_call_id"] = tool_call_id
- tool_call_index = i
-
- # After annotating the call, we expect to find a follow-up response (also unannotated)
- elif message["role"] == "function":
- # We should have a new tool call id in the buffer
- if tool_call_id is None:
- # raise ValueError(
- print(
- f"Got a function call role, but did not have a saved tool_call_id ready to use (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
- # allow a soft fail in this case
- message["tool_call_id"] = str(uuid.uuid4())
- elif "tool_call_id" in message:
- raise ValueError(
- f"Got a function call role, but it already had a saved tool_call_id (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
- elif i != tool_call_index + 1:
- raise ValueError(
- f"Got a function call role, saved tool_call_id came earlier than i-1 (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
- else:
- message["tool_call_id"] = tool_call_id
- tool_call_id = None # wipe the buffer
-
- elif message["role"] == "assistant" and "tool_calls" in message and message["tool_calls"] is not None:
- if not allow_tool_roles:
- raise NotImplementedError(
- f"tool_call_id annotation is meant for deprecated functions style, but got role 'assistant' with 'tool_calls' in message (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
-
- if len(message["tool_calls"]) != 1:
- raise NotImplementedError(
- f"Got unexpected format for tool_calls inside assistant message (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
-
- assistant_tool_call = message["tool_calls"][0]
- if "id" in assistant_tool_call and assistant_tool_call["id"] is not None:
- printd(f"Message already has id (tool_call_id)")
- tool_call_id = assistant_tool_call["id"]
- else:
- tool_call_id = str(uuid.uuid4())
- message["tool_calls"][0]["id"] = tool_call_id
- # also just put it at the top level for ease-of-access
- # message["tool_call_id"] = tool_call_id
- tool_call_index = i
-
- elif message["role"] == "tool":
- if not allow_tool_roles:
- raise NotImplementedError(
- f"tool_call_id annotation is meant for deprecated functions style, but got role 'tool' in message (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
-
- # if "tool_call_id" not in message or message["tool_call_id"] is None:
- # raise ValueError(f"Got a tool call role, but there's no tool_call_id:\n{messages[:i]}\n{message}")
-
- # We should have a new tool call id in the buffer
- if tool_call_id is None:
- # raise ValueError(
- print(
- f"Got a tool call role, but did not have a saved tool_call_id ready to use (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
- # allow a soft fail in this case
- message["tool_call_id"] = str(uuid.uuid4())
- elif "tool_call_id" in message and message["tool_call_id"] is not None:
- if tool_call_id is not None and tool_call_id != message["tool_call_id"]:
- # just wipe it
- # raise ValueError(
- # f"Got a tool call role, but it already had a saved tool_call_id (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- # )
- message["tool_call_id"] = tool_call_id
- tool_call_id = None # wipe the buffer
- else:
- tool_call_id = None
- elif i != tool_call_index + 1:
- raise ValueError(
- f"Got a tool call role, saved tool_call_id came earlier than i-1 (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
- )
- else:
- message["tool_call_id"] = tool_call_id
- tool_call_id = None # wipe the buffer
-
- else:
- # eg role == 'user', nothing to do here
- pass
-
- updated_messages.append(copy.deepcopy(message))
-
- return updated_messages
-
-
-def version_less_than(version_a: str, version_b: str) -> bool:
- """Compare versions to check if version_a is less than version_b."""
- # Regular expression to match version strings of the format int.int.int
- version_pattern = re.compile(r"^\d+\.\d+\.\d+$")
-
- # Assert that version strings match the required format
- if not version_pattern.match(version_a) or not version_pattern.match(version_b):
- raise ValueError("Version strings must be in the format 'int.int.int'")
-
- # Split the version strings into parts
- parts_a = [int(part) for part in version_a.split(".")]
- parts_b = [int(part) for part in version_b.split(".")]
-
- # Compare version parts
- return parts_a < parts_b
-
-
-def create_random_username() -> str:
- """Generate a random username by combining an adjective and a noun."""
- adjective = random.choice(ADJECTIVE_BANK).capitalize()
- noun = random.choice(NOUN_BANK).capitalize()
- return adjective + noun
-
-
-def verify_first_message_correctness(
- response: ChatCompletionResponse, require_send_message: bool = True, require_monologue: bool = False
-) -> bool:
- """Can be used to enforce that the first message always uses send_message"""
- response_message = response.choices[0].message
-
- # First message should be a call to send_message with a non-empty content
- if (hasattr(response_message, "function_call") and response_message.function_call is not None) and (
- hasattr(response_message, "tool_calls") and response_message.tool_calls is not None
- ):
- printd(f"First message includes both function call AND tool call: {response_message}")
- return False
- elif hasattr(response_message, "function_call") and response_message.function_call is not None:
- function_call = response_message.function_call
- elif hasattr(response_message, "tool_calls") and response_message.tool_calls is not None:
- function_call = response_message.tool_calls[0].function
- else:
- printd(f"First message didn't include function call: {response_message}")
- return False
-
- function_name = function_call.name if function_call is not None else ""
- if require_send_message and function_name != "send_message" and function_name != "archival_memory_search":
- printd(f"First message function call wasn't send_message or archival_memory_search: {response_message}")
- return False
-
- if require_monologue and (not response_message.content or response_message.content is None or response_message.content == ""):
- printd(f"First message missing internal monologue: {response_message}")
- return False
-
- if response_message.content:
- ### Extras
- monologue = response_message.content
-
- def contains_special_characters(s):
- special_characters = '(){}[]"'
- return any(char in s for char in special_characters)
-
- if contains_special_characters(monologue):
- printd(f"First message internal monologue contained special characters: {response_message}")
- return False
- # if 'functions' in monologue or 'send_message' in monologue or 'inner thought' in monologue.lower():
- if "functions" in monologue or "send_message" in monologue:
- # Sometimes the syntax won't be correct and internal syntax will leak into message.context
- printd(f"First message internal monologue contained reserved words: {response_message}")
- return False
-
- return True
-
-
-def is_valid_url(url):
- try:
- result = urlparse(url)
- return all([result.scheme, result.netloc])
- except ValueError:
- return False
-
-
-@contextmanager
-def suppress_stdout():
- """Used to temporarily stop stdout (eg for the 'MockLLM' message)"""
- new_stdout = io.StringIO()
- old_stdout = sys.stdout
- sys.stdout = new_stdout
- try:
- yield
- finally:
- sys.stdout = old_stdout
-
-
-def open_folder_in_explorer(folder_path):
- """
- Opens the specified folder in the system's native file explorer.
-
- :param folder_path: Absolute path to the folder to be opened.
- """
- if not os.path.exists(folder_path):
- raise ValueError(f"The specified folder {folder_path} does not exist.")
-
- # Determine the operating system
- os_name = platform.system()
-
- # Open the folder based on the operating system
- if os_name == "Windows":
- # Windows: use 'explorer' command
- subprocess.run(["explorer", folder_path], check=True)
- elif os_name == "Darwin":
- # macOS: use 'open' command
- subprocess.run(["open", folder_path], check=True)
- elif os_name == "Linux":
- # Linux: use 'xdg-open' command (works for most Linux distributions)
- subprocess.run(["xdg-open", folder_path], check=True)
- else:
- raise OSError(f"Unsupported operating system {os_name}.")
-
-
-# Custom unpickler
-class OpenAIBackcompatUnpickler(pickle.Unpickler):
- def find_class(self, module, name):
- if module == "openai.openai_object":
- return OpenAIObject
- return super().find_class(module, name)
-
-
-def count_tokens(s: str, model: str = "gpt-4") -> int:
- encoding = tiktoken.encoding_for_model(model)
- return len(encoding.encode(s))
-
-
-def printd(*args, **kwargs):
- if DEBUG:
- print(*args, **kwargs)
-
-
-def united_diff(str1, str2):
- lines1 = str1.splitlines(True)
- lines2 = str2.splitlines(True)
- diff = difflib.unified_diff(lines1, lines2)
- return "".join(diff)
-
-
-def parse_formatted_time(formatted_time):
- # parse times returned by memgpt.utils.get_formatted_time()
- return datetime.strptime(formatted_time, "%Y-%m-%d %I:%M:%S %p %Z%z")
-
-
-def datetime_to_timestamp(dt):
- # convert datetime object to integer timestamp
- return int(dt.timestamp())
-
-
-def timestamp_to_datetime(ts):
- # convert integer timestamp to datetime object
- return datetime.fromtimestamp(ts)
-
-
-def get_local_time_military():
- # Get the current time in UTC
- current_time_utc = datetime.now(pytz.utc)
-
- # Convert to San Francisco's time zone (PST/PDT)
- sf_time_zone = pytz.timezone("America/Los_Angeles")
- local_time = current_time_utc.astimezone(sf_time_zone)
-
- # You may format it as you desire
- formatted_time = local_time.strftime("%Y-%m-%d %H:%M:%S %Z%z")
-
- return formatted_time
-
-
-def get_local_time_timezone(timezone="America/Los_Angeles"):
- # Get the current time in UTC
- current_time_utc = datetime.now(pytz.utc)
-
- # Convert to San Francisco's time zone (PST/PDT)
- sf_time_zone = pytz.timezone(timezone)
- local_time = current_time_utc.astimezone(sf_time_zone)
-
- # You may format it as you desire, including AM/PM
- formatted_time = local_time.strftime("%Y-%m-%d %I:%M:%S %p %Z%z")
-
- return formatted_time
-
-
-def get_local_time(timezone=None):
- if timezone is not None:
- time_str = get_local_time_timezone(timezone)
- else:
- # Get the current time, which will be in the local timezone of the computer
- local_time = datetime.now().astimezone()
-
- # You may format it as you desire, including AM/PM
- time_str = local_time.strftime("%Y-%m-%d %I:%M:%S %p %Z%z")
-
- return time_str.strip()
-
-
-def get_utc_time() -> datetime:
- """Get the current UTC time"""
- # return datetime.now(pytz.utc)
- return datetime.now(timezone.utc)
-
-
-def format_datetime(dt):
- return dt.strftime("%Y-%m-%d %I:%M:%S %p %Z%z")
-
-
-def parse_json(string) -> dict:
- """Parse JSON string into JSON with both json and demjson"""
- result = None
- try:
- result = json.loads(string, strict=JSON_LOADS_STRICT)
- return result
- except Exception as e:
- print(f"Error parsing json with json package: {e}")
-
- try:
- result = demjson.decode(string)
- return result
- except demjson.JSONDecodeError as e:
- print(f"Error parsing json with demjson package: {e}")
- raise e
-
-
-def validate_function_response(function_response_string: any, strict: bool = False, truncate: bool = True) -> str:
- """Check to make sure that a function used by MemGPT returned a valid response
-
- Responses need to be strings (or None) that fall under a certain text count limit.
- """
- if not isinstance(function_response_string, str):
- # Soft correction for a few basic types
-
- if function_response_string is None:
- # function_response_string = "Empty (no function output)"
- function_response_string = "None" # backcompat
-
- elif isinstance(function_response_string, dict):
- if strict:
- # TODO add better error message
- raise ValueError(function_response_string)
-
- # Allow dict through since it will be cast to json.dumps()
- try:
- # TODO find a better way to do this that won't result in double escapes
- function_response_string = json.dumps(function_response_string, ensure_ascii=JSON_ENSURE_ASCII)
- except:
- raise ValueError(function_response_string)
-
- else:
- if strict:
- # TODO add better error message
- raise ValueError(function_response_string)
-
- # Try to convert to a string, but throw a warning to alert the user
- try:
- function_response_string = str(function_response_string)
- except:
- raise ValueError(function_response_string)
-
- # Now check the length and make sure it doesn't go over the limit
- # TODO we should change this to a max token limit that's variable based on tokens remaining (or context-window)
- if truncate and len(function_response_string) > FUNCTION_RETURN_CHAR_LIMIT:
- print(
- f"{CLI_WARNING_PREFIX}function return was over limit ({len(function_response_string)} > {FUNCTION_RETURN_CHAR_LIMIT}) and was truncated"
- )
- function_response_string = f"{function_response_string[:FUNCTION_RETURN_CHAR_LIMIT]}... [NOTE: function output was truncated since it exceeded the character limit ({len(function_response_string)} > {FUNCTION_RETURN_CHAR_LIMIT})]"
-
- return function_response_string
-
-
-def list_agent_config_files(sort="last_modified"):
- """List all agent config files, ignoring dotfiles."""
- agent_dir = os.path.join(MEMGPT_DIR, "agents")
- files = os.listdir(agent_dir)
-
- # Remove dotfiles like .DS_Store
- files = [file for file in files if not file.startswith(".")]
-
- # Remove anything that's not a directory
- files = [file for file in files if os.path.isdir(os.path.join(agent_dir, file))]
-
- if sort is not None:
- if sort == "last_modified":
- # Sort the directories by last modified (most recent first)
- files.sort(key=lambda x: os.path.getmtime(os.path.join(agent_dir, x)), reverse=True)
- else:
- raise ValueError(f"Unrecognized sorting option {sort}")
-
- return files
-
-
-def list_human_files():
- """List all humans files"""
- defaults_dir = os.path.join(memgpt.__path__[0], "humans", "examples")
- user_dir = os.path.join(MEMGPT_DIR, "humans")
-
- memgpt_defaults = os.listdir(defaults_dir)
- memgpt_defaults = [os.path.join(defaults_dir, f) for f in memgpt_defaults if f.endswith(".txt")]
-
- if os.path.exists(user_dir):
- user_added = os.listdir(user_dir)
- user_added = [os.path.join(user_dir, f) for f in user_added]
- else:
- user_added = []
- return memgpt_defaults + user_added
-
-
-def list_persona_files():
- """List all personas files"""
- defaults_dir = os.path.join(memgpt.__path__[0], "personas", "examples")
- user_dir = os.path.join(MEMGPT_DIR, "personas")
-
- memgpt_defaults = os.listdir(defaults_dir)
- memgpt_defaults = [os.path.join(defaults_dir, f) for f in memgpt_defaults if f.endswith(".txt")]
-
- if os.path.exists(user_dir):
- user_added = os.listdir(user_dir)
- user_added = [os.path.join(user_dir, f) for f in user_added]
- else:
- user_added = []
- return memgpt_defaults + user_added
-
-
-def get_human_text(name: str, enforce_limit=True):
- for file_path in list_human_files():
- file = os.path.basename(file_path)
- if f"{name}.txt" == file or name == file:
- human_text = open(file_path, "r", encoding="utf-8").read().strip()
- if enforce_limit and len(human_text) > CORE_MEMORY_HUMAN_CHAR_LIMIT:
- raise ValueError(f"Contents of {name}.txt is over the character limit ({len(human_text)} > {CORE_MEMORY_HUMAN_CHAR_LIMIT})")
- return human_text
-
- raise ValueError(f"Human {name}.txt not found")
-
-
-def get_persona_text(name: str, enforce_limit=True):
- for file_path in list_persona_files():
- file = os.path.basename(file_path)
- if f"{name}.txt" == file or name == file:
- persona_text = open(file_path, "r", encoding="utf-8").read().strip()
- if enforce_limit and len(persona_text) > CORE_MEMORY_PERSONA_CHAR_LIMIT:
- raise ValueError(
- f"Contents of {name}.txt is over the character limit ({len(persona_text)} > {CORE_MEMORY_PERSONA_CHAR_LIMIT})"
- )
- return persona_text
-
- raise ValueError(f"Persona {name}.txt not found")
-
-
-def get_human_text(name: str):
- for file_path in list_human_files():
- file = os.path.basename(file_path)
- if f"{name}.txt" == file or name == file:
- return open(file_path, "r", encoding="utf-8").read().strip()
-
-
-def get_schema_diff(schema_a, schema_b):
- # Assuming f_schema and linked_function['json_schema'] are your JSON schemas
- f_schema_json = json.dumps(schema_a, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
- linked_function_json = json.dumps(schema_b, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
-
- # Compute the difference using difflib
- difference = list(difflib.ndiff(f_schema_json.splitlines(keepends=True), linked_function_json.splitlines(keepends=True)))
-
- # Filter out lines that don't represent changes
- difference = [line for line in difference if line.startswith("+ ") or line.startswith("- ")]
-
- return "".join(difference)
-
-
-# datetime related
-def validate_date_format(date_str):
- """Validate the given date string in the format 'YYYY-MM-DD'."""
- try:
- datetime.strptime(date_str, "%Y-%m-%d")
- return True
- except (ValueError, TypeError):
- return False
-
-
-def extract_date_from_timestamp(timestamp):
- """Extracts and returns the date from the given timestamp."""
- # Extracts the date (ignoring the time and timezone)
- match = re.match(r"(\d{4}-\d{2}-\d{2})", timestamp)
- return match.group(1) if match else None
-
-
-def create_uuid_from_string(val: str):
- """
- Generate consistent UUID from a string
- from: https://samos-it.com/posts/python-create-uuid-from-random-string-of-words.html
- """
- hex_string = hashlib.md5(val.encode("UTF-8")).hexdigest()
- return uuid.UUID(hex=hex_string)
+import copy
+import difflib
+import hashlib
+import inspect
+import io
+import json
+import os
+import pickle
+import platform
+import random
+import re
+import subprocess
+import sys
+import uuid
+from contextlib import contextmanager
+from datetime import datetime, timedelta, timezone
+from functools import wraps
+from typing import List, Union, _GenericAlias, get_type_hints
+from urllib.parse import urljoin, urlparse
+
+import demjson3 as demjson
+import pytz
+import tiktoken
+
+import memgpt
+from memgpt.constants import (
+ CLI_WARNING_PREFIX,
+ CORE_MEMORY_HUMAN_CHAR_LIMIT,
+ CORE_MEMORY_PERSONA_CHAR_LIMIT,
+ FUNCTION_RETURN_CHAR_LIMIT,
+ JSON_ENSURE_ASCII,
+ JSON_LOADS_STRICT,
+ MEMGPT_DIR,
+ TOOL_CALL_ID_MAX_LEN,
+)
+from memgpt.models.chat_completion_response import ChatCompletionResponse
+from memgpt.openai_backcompat.openai_object import OpenAIObject
+
+DEBUG = False
+if "LOG_LEVEL" in os.environ:
+ if os.environ["LOG_LEVEL"] == "DEBUG":
+ DEBUG = True
+
+
+ADJECTIVE_BANK = [
+ "beautiful",
+ "gentle",
+ "angry",
+ "vivacious",
+ "grumpy",
+ "luxurious",
+ "fierce",
+ "delicate",
+ "fluffy",
+ "radiant",
+ "elated",
+ "magnificent",
+ "sassy",
+ "ecstatic",
+ "lustrous",
+ "gleaming",
+ "sorrowful",
+ "majestic",
+ "proud",
+ "dynamic",
+ "energetic",
+ "mysterious",
+ "loyal",
+ "brave",
+ "decisive",
+ "frosty",
+ "cheerful",
+ "adorable",
+ "melancholy",
+ "vibrant",
+ "elegant",
+ "gracious",
+ "inquisitive",
+ "opulent",
+ "peaceful",
+ "rebellious",
+ "scintillating",
+ "dazzling",
+ "whimsical",
+ "impeccable",
+ "meticulous",
+ "resilient",
+ "charming",
+ "vivacious",
+ "creative",
+ "intuitive",
+ "compassionate",
+ "innovative",
+ "enthusiastic",
+ "tremendous",
+ "effervescent",
+ "tenacious",
+ "fearless",
+ "sophisticated",
+ "witty",
+ "optimistic",
+ "exquisite",
+ "sincere",
+ "generous",
+ "kindhearted",
+ "serene",
+ "amiable",
+ "adventurous",
+ "bountiful",
+ "courageous",
+ "diligent",
+ "exotic",
+ "grateful",
+ "harmonious",
+ "imaginative",
+ "jubilant",
+ "keen",
+ "luminous",
+ "nurturing",
+ "outgoing",
+ "passionate",
+ "quaint",
+ "resourceful",
+ "sturdy",
+ "tactful",
+ "unassuming",
+ "versatile",
+ "wondrous",
+ "youthful",
+ "zealous",
+ "ardent",
+ "benevolent",
+ "capricious",
+ "dedicated",
+ "empathetic",
+ "fabulous",
+ "gregarious",
+ "humble",
+ "intriguing",
+ "jovial",
+ "kind",
+ "lovable",
+ "mindful",
+ "noble",
+ "original",
+ "pleasant",
+ "quixotic",
+ "reliable",
+ "spirited",
+ "tranquil",
+ "unique",
+ "venerable",
+ "warmhearted",
+ "xenodochial",
+ "yearning",
+ "zesty",
+ "amusing",
+ "blissful",
+ "calm",
+ "daring",
+ "enthusiastic",
+ "faithful",
+ "graceful",
+ "honest",
+ "incredible",
+ "joyful",
+ "kind",
+ "lovely",
+ "merry",
+ "noble",
+ "optimistic",
+ "peaceful",
+ "quirky",
+ "respectful",
+ "sweet",
+ "trustworthy",
+ "understanding",
+ "vibrant",
+ "witty",
+ "xenial",
+ "youthful",
+ "zealous",
+ "ambitious",
+ "brilliant",
+ "careful",
+ "devoted",
+ "energetic",
+ "friendly",
+ "glorious",
+ "humorous",
+ "intelligent",
+ "jovial",
+ "knowledgeable",
+ "loyal",
+ "modest",
+ "nice",
+ "obedient",
+ "patient",
+ "quiet",
+ "resilient",
+ "selfless",
+ "tolerant",
+ "unique",
+ "versatile",
+ "warm",
+ "xerothermic",
+ "yielding",
+ "zestful",
+ "amazing",
+ "bold",
+ "charming",
+ "determined",
+ "exciting",
+ "funny",
+ "happy",
+ "imaginative",
+ "jolly",
+ "keen",
+ "loving",
+ "magnificent",
+ "nifty",
+ "outstanding",
+ "polite",
+ "quick",
+ "reliable",
+ "sincere",
+ "thoughtful",
+ "unusual",
+ "valuable",
+ "wonderful",
+ "xenodochial",
+ "zealful",
+ "admirable",
+ "bright",
+ "clever",
+ "dedicated",
+ "extraordinary",
+ "generous",
+ "hardworking",
+ "inspiring",
+ "jubilant",
+ "kindhearted",
+ "lively",
+ "miraculous",
+ "neat",
+ "openminded",
+ "passionate",
+ "remarkable",
+ "stunning",
+ "truthful",
+ "upbeat",
+ "vivacious",
+ "welcoming",
+ "yare",
+ "zealous",
+]
+
+NOUN_BANK = [
+ "lizard",
+ "firefighter",
+ "banana",
+ "castle",
+ "dolphin",
+ "elephant",
+ "forest",
+ "giraffe",
+ "harbor",
+ "iceberg",
+ "jewelry",
+ "kangaroo",
+ "library",
+ "mountain",
+ "notebook",
+ "orchard",
+ "penguin",
+ "quilt",
+ "rainbow",
+ "squirrel",
+ "teapot",
+ "umbrella",
+ "volcano",
+ "waterfall",
+ "xylophone",
+ "yacht",
+ "zebra",
+ "apple",
+ "butterfly",
+ "caterpillar",
+ "dragonfly",
+ "elephant",
+ "flamingo",
+ "gorilla",
+ "hippopotamus",
+ "iguana",
+ "jellyfish",
+ "koala",
+ "lemur",
+ "mongoose",
+ "nighthawk",
+ "octopus",
+ "panda",
+ "quokka",
+ "rhinoceros",
+ "salamander",
+ "tortoise",
+ "unicorn",
+ "vulture",
+ "walrus",
+ "xenopus",
+ "yak",
+ "zebu",
+ "asteroid",
+ "balloon",
+ "compass",
+ "dinosaur",
+ "eagle",
+ "firefly",
+ "galaxy",
+ "hedgehog",
+ "island",
+ "jaguar",
+ "kettle",
+ "lion",
+ "mammoth",
+ "nucleus",
+ "owl",
+ "pumpkin",
+ "quasar",
+ "reindeer",
+ "snail",
+ "tiger",
+ "universe",
+ "vampire",
+ "wombat",
+ "xerus",
+ "yellowhammer",
+ "zeppelin",
+ "alligator",
+ "buffalo",
+ "cactus",
+ "donkey",
+ "emerald",
+ "falcon",
+ "gazelle",
+ "hamster",
+ "icicle",
+ "jackal",
+ "kitten",
+ "leopard",
+ "mushroom",
+ "narwhal",
+ "opossum",
+ "peacock",
+ "quail",
+ "rabbit",
+ "scorpion",
+ "toucan",
+ "urchin",
+ "viper",
+ "wolf",
+ "xray",
+ "yucca",
+ "zebu",
+ "acorn",
+ "biscuit",
+ "cupcake",
+ "daisy",
+ "eyeglasses",
+ "frisbee",
+ "goblin",
+ "hamburger",
+ "icicle",
+ "jackfruit",
+ "kaleidoscope",
+ "lighthouse",
+ "marshmallow",
+ "nectarine",
+ "obelisk",
+ "pancake",
+ "quicksand",
+ "raspberry",
+ "spinach",
+ "truffle",
+ "umbrella",
+ "volleyball",
+ "walnut",
+ "xylophonist",
+ "yogurt",
+ "zucchini",
+ "asterisk",
+ "blackberry",
+ "chimpanzee",
+ "dumpling",
+ "espresso",
+ "fireplace",
+ "gnome",
+ "hedgehog",
+ "illustration",
+ "jackhammer",
+ "kumquat",
+ "lemongrass",
+ "mandolin",
+ "nugget",
+ "ostrich",
+ "parakeet",
+ "quiche",
+ "racquet",
+ "seashell",
+ "tadpole",
+ "unicorn",
+ "vaccination",
+ "wolverine",
+ "xenophobia",
+ "yam",
+ "zeppelin",
+ "accordion",
+ "broccoli",
+ "carousel",
+ "daffodil",
+ "eggplant",
+ "flamingo",
+ "grapefruit",
+ "harpsichord",
+ "impression",
+ "jackrabbit",
+ "kitten",
+ "llama",
+ "mandarin",
+ "nachos",
+ "obelisk",
+ "papaya",
+ "quokka",
+ "rooster",
+ "sunflower",
+ "turnip",
+ "ukulele",
+ "viper",
+ "waffle",
+ "xylograph",
+ "yeti",
+ "zephyr",
+ "abacus",
+ "blueberry",
+ "crocodile",
+ "dandelion",
+ "echidna",
+ "fig",
+ "giraffe",
+ "hamster",
+ "iguana",
+ "jackal",
+ "kiwi",
+ "lobster",
+ "marmot",
+ "noodle",
+ "octopus",
+ "platypus",
+ "quail",
+ "raccoon",
+ "starfish",
+ "tulip",
+ "urchin",
+ "vampire",
+ "walrus",
+ "xylophone",
+ "yak",
+ "zebra",
+]
+
+
+def smart_urljoin(base_url: str, relative_url: str) -> str:
+ """urljoin is stupid and wants a trailing / at the end of the endpoint address, or it will chop the suffix off"""
+ if not base_url.endswith("/"):
+ base_url += "/"
+ return urljoin(base_url, relative_url)
+
+
+def is_utc_datetime(dt: datetime) -> bool:
+ return dt.tzinfo is not None and dt.tzinfo.utcoffset(dt) == timedelta(0)
+
+
+def get_tool_call_id() -> str:
+ return str(uuid.uuid4())[:TOOL_CALL_ID_MAX_LEN]
+
+
+def assistant_function_to_tool(assistant_message: dict) -> dict:
+ assert "function_call" in assistant_message
+ new_msg = copy.deepcopy(assistant_message)
+ function_call = new_msg.pop("function_call")
+ new_msg["tool_calls"] = [
+ {
+ "id": get_tool_call_id(),
+ "type": "function",
+ "function": function_call,
+ }
+ ]
+ return new_msg
+
+
+def is_optional_type(hint):
+ """Check if the type hint is an Optional type."""
+ if isinstance(hint, _GenericAlias):
+ return hint.__origin__ is Union and type(None) in hint.__args__
+ return False
+
+
+def enforce_types(func):
+ @wraps(func)
+ def wrapper(*args, **kwargs):
+ # Get type hints, excluding the return type hint
+ hints = {k: v for k, v in get_type_hints(func).items() if k != "return"}
+
+ # Get the function's argument names
+ arg_names = inspect.getfullargspec(func).args
+
+ # Pair each argument with its corresponding type hint
+ args_with_hints = dict(zip(arg_names[1:], args[1:])) # Skipping 'self'
+
+ # Check types of arguments
+ for arg_name, arg_value in args_with_hints.items():
+ hint = hints.get(arg_name)
+ if hint and not isinstance(arg_value, hint) and not (is_optional_type(hint) and arg_value is None):
+ raise ValueError(f"Argument {arg_name} does not match type {hint}")
+
+ # Check types of keyword arguments
+ for arg_name, arg_value in kwargs.items():
+ hint = hints.get(arg_name)
+ if hint and not isinstance(arg_value, hint) and not (is_optional_type(hint) and arg_value is None):
+ raise ValueError(f"Argument {arg_name} does not match type {hint}")
+
+ return func(*args, **kwargs)
+
+ return wrapper
+
+
+def annotate_message_json_list_with_tool_calls(messages: List[dict], allow_tool_roles: bool = False):
+ """Add in missing tool_call_id fields to a list of messages using function call style
+
+ Walk through the list forwards:
+ - If we encounter an assistant message that calls a function ("function_call") but doesn't have a "tool_call_id" field
+ - Generate the tool_call_id
+ - Then check if the subsequent message is a role == "function" message
+ - If so, then att
+ """
+ tool_call_index = None
+ tool_call_id = None
+ updated_messages = []
+
+ for i, message in enumerate(messages):
+ if "role" not in message:
+ raise ValueError(f"message missing 'role' field:\n{message}")
+
+ # If we find a function call w/o a tool call ID annotation, annotate it
+ if message["role"] == "assistant" and "function_call" in message:
+ if "tool_call_id" in message and message["tool_call_id"] is not None:
+ printd(f"Message already has tool_call_id")
+ tool_call_id = message["tool_call_id"]
+ else:
+ tool_call_id = str(uuid.uuid4())
+ message["tool_call_id"] = tool_call_id
+ tool_call_index = i
+
+ # After annotating the call, we expect to find a follow-up response (also unannotated)
+ elif message["role"] == "function":
+ # We should have a new tool call id in the buffer
+ if tool_call_id is None:
+ # raise ValueError(
+ print(
+ f"Got a function call role, but did not have a saved tool_call_id ready to use (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+ # allow a soft fail in this case
+ message["tool_call_id"] = str(uuid.uuid4())
+ elif "tool_call_id" in message:
+ raise ValueError(
+ f"Got a function call role, but it already had a saved tool_call_id (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+ elif i != tool_call_index + 1:
+ raise ValueError(
+ f"Got a function call role, saved tool_call_id came earlier than i-1 (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+ else:
+ message["tool_call_id"] = tool_call_id
+ tool_call_id = None # wipe the buffer
+
+ elif message["role"] == "assistant" and "tool_calls" in message and message["tool_calls"] is not None:
+ if not allow_tool_roles:
+ raise NotImplementedError(
+ f"tool_call_id annotation is meant for deprecated functions style, but got role 'assistant' with 'tool_calls' in message (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+
+ if len(message["tool_calls"]) != 1:
+ raise NotImplementedError(
+ f"Got unexpected format for tool_calls inside assistant message (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+
+ assistant_tool_call = message["tool_calls"][0]
+ if "id" in assistant_tool_call and assistant_tool_call["id"] is not None:
+ printd(f"Message already has id (tool_call_id)")
+ tool_call_id = assistant_tool_call["id"]
+ else:
+ tool_call_id = str(uuid.uuid4())
+ message["tool_calls"][0]["id"] = tool_call_id
+ # also just put it at the top level for ease-of-access
+ # message["tool_call_id"] = tool_call_id
+ tool_call_index = i
+
+ elif message["role"] == "tool":
+ if not allow_tool_roles:
+ raise NotImplementedError(
+ f"tool_call_id annotation is meant for deprecated functions style, but got role 'tool' in message (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+
+ # if "tool_call_id" not in message or message["tool_call_id"] is None:
+ # raise ValueError(f"Got a tool call role, but there's no tool_call_id:\n{messages[:i]}\n{message}")
+
+ # We should have a new tool call id in the buffer
+ if tool_call_id is None:
+ # raise ValueError(
+ print(
+ f"Got a tool call role, but did not have a saved tool_call_id ready to use (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+ # allow a soft fail in this case
+ message["tool_call_id"] = str(uuid.uuid4())
+ elif "tool_call_id" in message and message["tool_call_id"] is not None:
+ if tool_call_id is not None and tool_call_id != message["tool_call_id"]:
+ # just wipe it
+ # raise ValueError(
+ # f"Got a tool call role, but it already had a saved tool_call_id (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ # )
+ message["tool_call_id"] = tool_call_id
+ tool_call_id = None # wipe the buffer
+ else:
+ tool_call_id = None
+ elif i != tool_call_index + 1:
+ raise ValueError(
+ f"Got a tool call role, saved tool_call_id came earlier than i-1 (i={i}, total={len(messages)}):\n{messages[:i]}\n{message}"
+ )
+ else:
+ message["tool_call_id"] = tool_call_id
+ tool_call_id = None # wipe the buffer
+
+ else:
+ # eg role == 'user', nothing to do here
+ pass
+
+ updated_messages.append(copy.deepcopy(message))
+
+ return updated_messages
+
+
+def version_less_than(version_a: str, version_b: str) -> bool:
+ """Compare versions to check if version_a is less than version_b."""
+ # Regular expression to match version strings of the format int.int.int
+ version_pattern = re.compile(r"^\d+\.\d+\.\d+$")
+
+ # Assert that version strings match the required format
+ if not version_pattern.match(version_a) or not version_pattern.match(version_b):
+ raise ValueError("Version strings must be in the format 'int.int.int'")
+
+ # Split the version strings into parts
+ parts_a = [int(part) for part in version_a.split(".")]
+ parts_b = [int(part) for part in version_b.split(".")]
+
+ # Compare version parts
+ return parts_a < parts_b
+
+
+def create_random_username() -> str:
+ """Generate a random username by combining an adjective and a noun."""
+ adjective = random.choice(ADJECTIVE_BANK).capitalize()
+ noun = random.choice(NOUN_BANK).capitalize()
+ return adjective + noun
+
+
+def verify_first_message_correctness(
+ response: ChatCompletionResponse, require_send_message: bool = True, require_monologue: bool = False
+) -> bool:
+ """Can be used to enforce that the first message always uses send_message"""
+ response_message = response.choices[0].message
+
+ # First message should be a call to send_message with a non-empty content
+ if (hasattr(response_message, "function_call") and response_message.function_call is not None) and (
+ hasattr(response_message, "tool_calls") and response_message.tool_calls is not None
+ ):
+ printd(f"First message includes both function call AND tool call: {response_message}")
+ return False
+ elif hasattr(response_message, "function_call") and response_message.function_call is not None:
+ function_call = response_message.function_call
+ elif hasattr(response_message, "tool_calls") and response_message.tool_calls is not None:
+ function_call = response_message.tool_calls[0].function
+ else:
+ printd(f"First message didn't include function call: {response_message}")
+ return False
+
+ function_name = function_call.name if function_call is not None else ""
+ if require_send_message and function_name != "send_message" and function_name != "archival_memory_search":
+ printd(f"First message function call wasn't send_message or archival_memory_search: {response_message}")
+ return False
+
+ if require_monologue and (not response_message.content or response_message.content is None or response_message.content == ""):
+ printd(f"First message missing internal monologue: {response_message}")
+ return False
+
+ if response_message.content:
+ ### Extras
+ monologue = response_message.content
+
+ def contains_special_characters(s):
+ special_characters = '(){}[]"'
+ return any(char in s for char in special_characters)
+
+ if contains_special_characters(monologue):
+ printd(f"First message internal monologue contained special characters: {response_message}")
+ return False
+ # if 'functions' in monologue or 'send_message' in monologue or 'inner thought' in monologue.lower():
+ if "functions" in monologue or "send_message" in monologue:
+ # Sometimes the syntax won't be correct and internal syntax will leak into message.context
+ printd(f"First message internal monologue contained reserved words: {response_message}")
+ return False
+
+ return True
+
+
+def is_valid_url(url):
+ try:
+ result = urlparse(url)
+ return all([result.scheme, result.netloc])
+ except ValueError:
+ return False
+
+
+@contextmanager
+def suppress_stdout():
+ """Used to temporarily stop stdout (eg for the 'MockLLM' message)"""
+ new_stdout = io.StringIO()
+ old_stdout = sys.stdout
+ sys.stdout = new_stdout
+ try:
+ yield
+ finally:
+ sys.stdout = old_stdout
+
+
+def open_folder_in_explorer(folder_path):
+ """
+ Opens the specified folder in the system's native file explorer.
+
+ :param folder_path: Absolute path to the folder to be opened.
+ """
+ if not os.path.exists(folder_path):
+ raise ValueError(f"The specified folder {folder_path} does not exist.")
+
+ # Determine the operating system
+ os_name = platform.system()
+
+ # Open the folder based on the operating system
+ if os_name == "Windows":
+ # Windows: use 'explorer' command
+ subprocess.run(["explorer", folder_path], check=True)
+ elif os_name == "Darwin":
+ # macOS: use 'open' command
+ subprocess.run(["open", folder_path], check=True)
+ elif os_name == "Linux":
+ # Linux: use 'xdg-open' command (works for most Linux distributions)
+ subprocess.run(["xdg-open", folder_path], check=True)
+ else:
+ raise OSError(f"Unsupported operating system {os_name}.")
+
+
+# Custom unpickler
+class OpenAIBackcompatUnpickler(pickle.Unpickler):
+ def find_class(self, module, name):
+ if module == "openai.openai_object":
+ return OpenAIObject
+ return super().find_class(module, name)
+
+
+def count_tokens(s: str, model: str = "gpt-4") -> int:
+ encoding = tiktoken.encoding_for_model(model)
+ return len(encoding.encode(s))
+
+
+def printd(*args, **kwargs):
+ if DEBUG:
+ print(*args, **kwargs)
+
+
+def united_diff(str1, str2):
+ lines1 = str1.splitlines(True)
+ lines2 = str2.splitlines(True)
+ diff = difflib.unified_diff(lines1, lines2)
+ return "".join(diff)
+
+
+def parse_formatted_time(formatted_time):
+ # parse times returned by memgpt.utils.get_formatted_time()
+ return datetime.strptime(formatted_time, "%Y-%m-%d %I:%M:%S %p %Z%z")
+
+
+def datetime_to_timestamp(dt):
+ # convert datetime object to integer timestamp
+ return int(dt.timestamp())
+
+
+def timestamp_to_datetime(ts):
+ # convert integer timestamp to datetime object
+ return datetime.fromtimestamp(ts)
+
+
+def get_local_time_military():
+ # Get the current time in UTC
+ current_time_utc = datetime.now(pytz.utc)
+
+ # Convert to San Francisco's time zone (PST/PDT)
+ sf_time_zone = pytz.timezone("America/Los_Angeles")
+ local_time = current_time_utc.astimezone(sf_time_zone)
+
+ # You may format it as you desire
+ formatted_time = local_time.strftime("%Y-%m-%d %H:%M:%S %Z%z")
+
+ return formatted_time
+
+
+def get_local_time_timezone(timezone="America/Los_Angeles"):
+ # Get the current time in UTC
+ current_time_utc = datetime.now(pytz.utc)
+
+ # Convert to San Francisco's time zone (PST/PDT)
+ sf_time_zone = pytz.timezone(timezone)
+ local_time = current_time_utc.astimezone(sf_time_zone)
+
+ # You may format it as you desire, including AM/PM
+ formatted_time = local_time.strftime("%Y-%m-%d %I:%M:%S %p %Z%z")
+
+ return formatted_time
+
+
+def get_local_time(timezone=None):
+ if timezone is not None:
+ time_str = get_local_time_timezone(timezone)
+ else:
+ # Get the current time, which will be in the local timezone of the computer
+ local_time = datetime.now().astimezone()
+
+ # You may format it as you desire, including AM/PM
+ time_str = local_time.strftime("%Y-%m-%d %I:%M:%S %p %Z%z")
+
+ return time_str.strip()
+
+
+def get_utc_time() -> datetime:
+ """Get the current UTC time"""
+ # return datetime.now(pytz.utc)
+ return datetime.now(timezone.utc)
+
+
+def format_datetime(dt):
+ return dt.strftime("%Y-%m-%d %I:%M:%S %p %Z%z")
+
+
+def parse_json(string) -> dict:
+ """Parse JSON string into JSON with both json and demjson"""
+ result = None
+ try:
+ result = json.loads(string, strict=JSON_LOADS_STRICT)
+ return result
+ except Exception as e:
+ print(f"Error parsing json with json package: {e}")
+
+ try:
+ result = demjson.decode(string)
+ return result
+ except demjson.JSONDecodeError as e:
+ print(f"Error parsing json with demjson package: {e}")
+ raise e
+
+
+def validate_function_response(function_response_string: any, strict: bool = False, truncate: bool = True) -> str:
+ """Check to make sure that a function used by MemGPT returned a valid response
+
+ Responses need to be strings (or None) that fall under a certain text count limit.
+ """
+ if not isinstance(function_response_string, str):
+ # Soft correction for a few basic types
+
+ if function_response_string is None:
+ # function_response_string = "Empty (no function output)"
+ function_response_string = "None" # backcompat
+
+ elif isinstance(function_response_string, dict):
+ if strict:
+ # TODO add better error message
+ raise ValueError(function_response_string)
+
+ # Allow dict through since it will be cast to json.dumps()
+ try:
+ # TODO find a better way to do this that won't result in double escapes
+ function_response_string = json.dumps(function_response_string, ensure_ascii=JSON_ENSURE_ASCII)
+ except:
+ raise ValueError(function_response_string)
+
+ else:
+ if strict:
+ # TODO add better error message
+ raise ValueError(function_response_string)
+
+ # Try to convert to a string, but throw a warning to alert the user
+ try:
+ function_response_string = str(function_response_string)
+ except:
+ raise ValueError(function_response_string)
+
+ # Now check the length and make sure it doesn't go over the limit
+ # TODO we should change this to a max token limit that's variable based on tokens remaining (or context-window)
+ if truncate and len(function_response_string) > FUNCTION_RETURN_CHAR_LIMIT:
+ print(
+ f"{CLI_WARNING_PREFIX}function return was over limit ({len(function_response_string)} > {FUNCTION_RETURN_CHAR_LIMIT}) and was truncated"
+ )
+ function_response_string = f"{function_response_string[:FUNCTION_RETURN_CHAR_LIMIT]}... [NOTE: function output was truncated since it exceeded the character limit ({len(function_response_string)} > {FUNCTION_RETURN_CHAR_LIMIT})]"
+
+ return function_response_string
+
+
+def list_agent_config_files(sort="last_modified"):
+ """List all agent config files, ignoring dotfiles."""
+ agent_dir = os.path.join(MEMGPT_DIR, "agents")
+ files = os.listdir(agent_dir)
+
+ # Remove dotfiles like .DS_Store
+ files = [file for file in files if not file.startswith(".")]
+
+ # Remove anything that's not a directory
+ files = [file for file in files if os.path.isdir(os.path.join(agent_dir, file))]
+
+ if sort is not None:
+ if sort == "last_modified":
+ # Sort the directories by last modified (most recent first)
+ files.sort(key=lambda x: os.path.getmtime(os.path.join(agent_dir, x)), reverse=True)
+ else:
+ raise ValueError(f"Unrecognized sorting option {sort}")
+
+ return files
+
+
+def list_human_files():
+ """List all humans files"""
+ defaults_dir = os.path.join(memgpt.__path__[0], "humans", "examples")
+ user_dir = os.path.join(MEMGPT_DIR, "humans")
+
+ memgpt_defaults = os.listdir(defaults_dir)
+ memgpt_defaults = [os.path.join(defaults_dir, f) for f in memgpt_defaults if f.endswith(".txt")]
+
+ if os.path.exists(user_dir):
+ user_added = os.listdir(user_dir)
+ user_added = [os.path.join(user_dir, f) for f in user_added]
+ else:
+ user_added = []
+ return memgpt_defaults + user_added
+
+
+def list_persona_files():
+ """List all personas files"""
+ defaults_dir = os.path.join(memgpt.__path__[0], "personas", "examples")
+ user_dir = os.path.join(MEMGPT_DIR, "personas")
+
+ memgpt_defaults = os.listdir(defaults_dir)
+ memgpt_defaults = [os.path.join(defaults_dir, f) for f in memgpt_defaults if f.endswith(".txt")]
+
+ if os.path.exists(user_dir):
+ user_added = os.listdir(user_dir)
+ user_added = [os.path.join(user_dir, f) for f in user_added]
+ else:
+ user_added = []
+ return memgpt_defaults + user_added
+
+
+def get_human_text(name: str, enforce_limit=True):
+ for file_path in list_human_files():
+ file = os.path.basename(file_path)
+ if f"{name}.txt" == file or name == file:
+ human_text = open(file_path, "r", encoding="utf-8").read().strip()
+ if enforce_limit and len(human_text) > CORE_MEMORY_HUMAN_CHAR_LIMIT:
+ raise ValueError(f"Contents of {name}.txt is over the character limit ({len(human_text)} > {CORE_MEMORY_HUMAN_CHAR_LIMIT})")
+ return human_text
+
+ raise ValueError(f"Human {name}.txt not found")
+
+
+def get_persona_text(name: str, enforce_limit=True):
+ for file_path in list_persona_files():
+ file = os.path.basename(file_path)
+ if f"{name}.txt" == file or name == file:
+ persona_text = open(file_path, "r", encoding="utf-8").read().strip()
+ if enforce_limit and len(persona_text) > CORE_MEMORY_PERSONA_CHAR_LIMIT:
+ raise ValueError(
+ f"Contents of {name}.txt is over the character limit ({len(persona_text)} > {CORE_MEMORY_PERSONA_CHAR_LIMIT})"
+ )
+ return persona_text
+
+ raise ValueError(f"Persona {name}.txt not found")
+
+
+def get_human_text(name: str):
+ for file_path in list_human_files():
+ file = os.path.basename(file_path)
+ if f"{name}.txt" == file or name == file:
+ return open(file_path, "r", encoding="utf-8").read().strip()
+
+
+def get_schema_diff(schema_a, schema_b):
+ # Assuming f_schema and linked_function['json_schema'] are your JSON schemas
+ f_schema_json = json.dumps(schema_a, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
+ linked_function_json = json.dumps(schema_b, indent=2, ensure_ascii=JSON_ENSURE_ASCII)
+
+ # Compute the difference using difflib
+ difference = list(difflib.ndiff(f_schema_json.splitlines(keepends=True), linked_function_json.splitlines(keepends=True)))
+
+ # Filter out lines that don't represent changes
+ difference = [line for line in difference if line.startswith("+ ") or line.startswith("- ")]
+
+ return "".join(difference)
+
+
+# datetime related
+def validate_date_format(date_str):
+ """Validate the given date string in the format 'YYYY-MM-DD'."""
+ try:
+ datetime.strptime(date_str, "%Y-%m-%d")
+ return True
+ except (ValueError, TypeError):
+ return False
+
+
+def extract_date_from_timestamp(timestamp):
+ """Extracts and returns the date from the given timestamp."""
+ # Extracts the date (ignoring the time and timezone)
+ match = re.match(r"(\d{4}-\d{2}-\d{2})", timestamp)
+ return match.group(1) if match else None
+
+
+def create_uuid_from_string(val: str):
+ """
+ Generate consistent UUID from a string
+ from: https://samos-it.com/posts/python-create-uuid-from-random-string-of-words.html
+ """
+ hex_string = hashlib.md5(val.encode("UTF-8")).hexdigest()
+ return uuid.UUID(hex=hex_string)